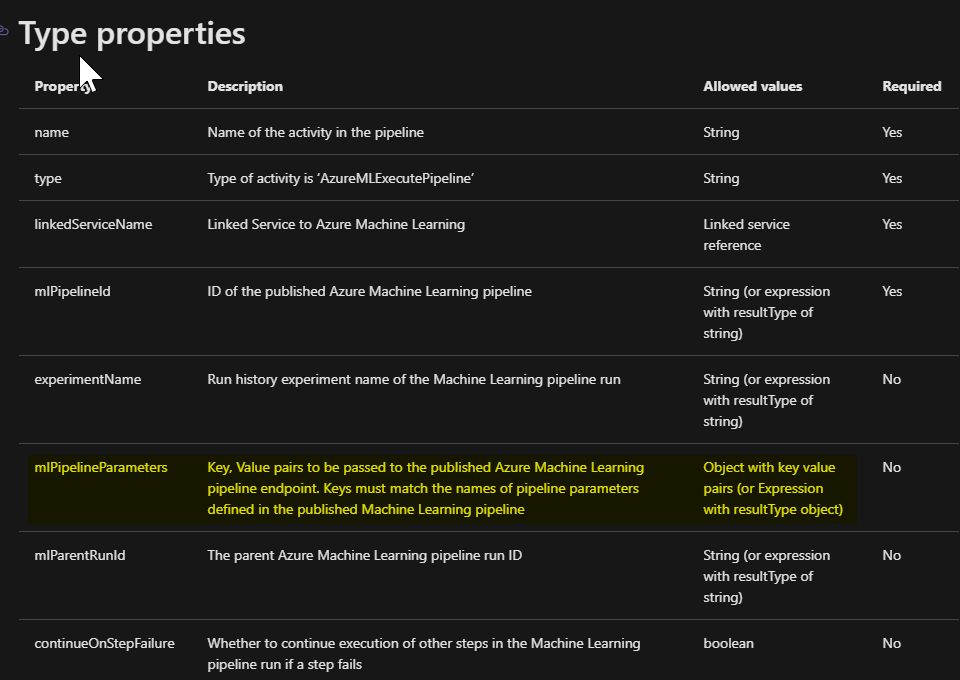
Как передать DataPath PipelineParameter из AzureDatafactory в действие AzureMachineLearningExecutePipeline?
Я пытаюсь прочитать файл из хранилища BLOB-объектов, загрузить его в pandas и записать его в хранилище Blob Storage.
У меня есть конвейер машинного обучения Azure с PythonScriptStep, который принимает 2 PipelineParameters и является DataPaths, как показано ниже.
from azureml.data.datapath import DataPath, DataPathComputeBinding, DataReference from azureml.pipeline.core import PipelineParameter datastore = Datastore(ws, "SampleStore") in_raw_path_default = 'somefolder/raw/alerts/2020/08/03/default_in.csv' in_cleaned_path_default= 'somefolder/cleaned/alerts/2020/08/03/default_out.csv' in_raw_datapath = DataPath(datastore=datastore, path_on_datastore=in_raw_path_default) in_raw_path_pipelineparam = PipelineParameter(name="inrawpath", default_value=in_raw_datapath) raw_datapath_input = (in_raw_path_pipelineparam, DataPathComputeBinding(mode='mount')) in_cleaned_datapath = DataPath(datastore=datastore, path_on_datastore=in_cleaned_path_default) in_cleaned_path_pipelineparam = PipelineParameter(name="incleanedpath", default_value=in_cleaned_datapath) cleaned_datapath_input = (in_cleaned_path_pipelineparam, DataPathComputeBinding(mode='mount')) from azureml.pipeline.steps import PythonScriptStep source_directory = script_folder + '/pipeline_Steps' dataprep_step = PythonScriptStep( script_name="SimpleTest.py", arguments=["--input_data", raw_datapath_input, "--cleaned_data", cleaned_datapath_input], inputs=[raw_datapath_input, cleaned_datapath_input], compute_target=default_compute, source_directory=source_directory, runconfig=run_config, allow_reuse=True ) from azureml.pipeline.core import Pipeline pipeline_test = Pipeline(workspace=ws, steps=[dataprep_step]) test_raw_path = DataPath(datastore=datastore, path_on_datastore='samplefolder/raw/alerts/2017/05/31/test.csv') test_cleaned_path = DataPath(datastore=datastore, path_on_datastore='samplefolder/cleaned/alerts/2020/09/03') pipeline_run_msalerts = Experiment(ws, 'SampleExperiment').submit(pipeline_test, pipeline_parameters={"inrawpath" : test_raw_path, "incleanedpath" : test_cleaned_path})```
Это используемый скрипт (SimpleTesy.py):
import os
import sys
import argparse
import pathlib
import azureml.core
import pandas as pd
parser = argparse.ArgumentParser("datapreponly")
parser.add_argument("--input_data", type=str)
parser.add_argument("--cleaned_data", type=str)
args = parser.parse_args()
print("Argument 1: %s" % args.input_data)
print("Argument 2: %s" % args.cleaned_data)
testDf = pd.read_csv(args.input_data, error_bad_lines=False)
print('Total Data Shape' + str(testDf.shape))
if not (args.cleaned_data is None):
output_path = args.cleaned_data
os.makedirs(output_path, exist_ok=True)
outdatapath = output_path + '/alert.csv'
testDf.to_csv(outdatapath, index=False)
Запуск этого AzureMLPipeline из AzureDataFactory:
приведенный выше код отлично работает, выполняя конвейер машинного обучения в AzureMLWorkspace/PipelineSDK. Я пытаюсь запустить AzureMLpipeline из действия AzureDataFactory(AzureMachineLearningExecutePipeline) следующим образом
[![Введите здесь описание изображения][1]][1]
Попытался выполнить отладку следующим образом, передав 2 строковых входных пути
rawdatapath = "samplefolder / raw / alerts / 2017/05/31 / test.csv"
cleaneddatapath = "samplefolder / raw / cleaned / 2020/09/03 /" [![[! введите описание изображения здесь][2]][2]
Current directory: /mnt/batch/tasks/shared/LS_root/jobs/myazuremlworkspace/azureml/d8ee11ea-5838-46e5-a8ce-da2fbff5aade/mounts/workspaceblobstore/azureml/d8ee11ea-5838-46e5-a8ce-da2fbff5aade
Preparing to call script [ SimpleTest.py ]
with arguments:
['--input_data', '/mnt/batch/tasks/shared/LS_root/jobs/myazuremlworkspace/azureml/d8ee11ea-5838-46e5-a8ce-da2fbff5aade/mounts/SampleStore/somefolder/raw/alerts/2020/08/03/default_in.csv',
'--cleaned_data', '/mnt/batch/tasks/shared/LS_root/jobs/myazuremlworkspace/azureml/d8ee11ea-5838-46e5-a8ce-da2fbff5aade/mounts/SampleStore/somefolder/cleaned/alerts/2020/08/03/default_out.csv']
After variable expansion, calling script [ SimpleTest.py ] with arguments:
['--input_data', '/mnt/batch/tasks/shared/LS_root/jobs/myazuremlworkspace/azureml/d8ee11ea-5838-46e5-a8ce-da2fbff5aade/mounts/SampleStore/somefolder/raw/alerts/2020/08/03/default_in.csv',
'--cleaned_data', '/mnt/batch/tasks/shared/LS_root/jobs/myazuremlworkspace/azureml/d8ee11ea-5838-46e5-a8ce-da2fbff5aade/mounts/SampleStore/somefolder/cleaned/alerts/2020/08/03/default_out.csv']
Script type = None
Argument 1: /mnt/batch/tasks/shared/LS_root/jobs/myazuremlworkspace/azureml/d8ee11ea-5838-46e5-a8ce-da2fbff5aade/mounts/SampleStore/somefolder/raw/alerts/2020/08/03/default_in.csv
Argument 2: /mnt/batch/tasks/shared/LS_root/jobs/myazuremlworkspace/azureml/d8ee11ea-5838-46e5-a8ce-da2fbff5aade/mounts/SampleStore/somefolder/cleaned/alerts/2020/08/03/default_out.csv
.......................
FileNotFoundError: [Errno 2] No such file or directory: '/mnt/batch/tasks/shared/LS_root/jobs/myazuremlworkspace/azureml/d8ee11ea-5838-46e5-a8ce-da2fbff5aade/mounts/SampleStore/somefolder/raw/alerts/2020/08/03/default_in.csv'
Он показывает, что вместо параметра конвейера используется путь по умолчанию (отсутствие такой ошибки файла или каталога не менее важно, поскольку основной момент заключается в том, что путь по умолчанию используется вместо параметров конвейера). Я сомневаюсь, что это связано с передачей параметра конвейера в виде строки вместо пути к данным.
** НАКОНЕЦ ВОПРОС: ** Как передать путь данных в AzureMLPipelineActivity из фабрики данных Azure?
Спасибо. [1]: [2]: 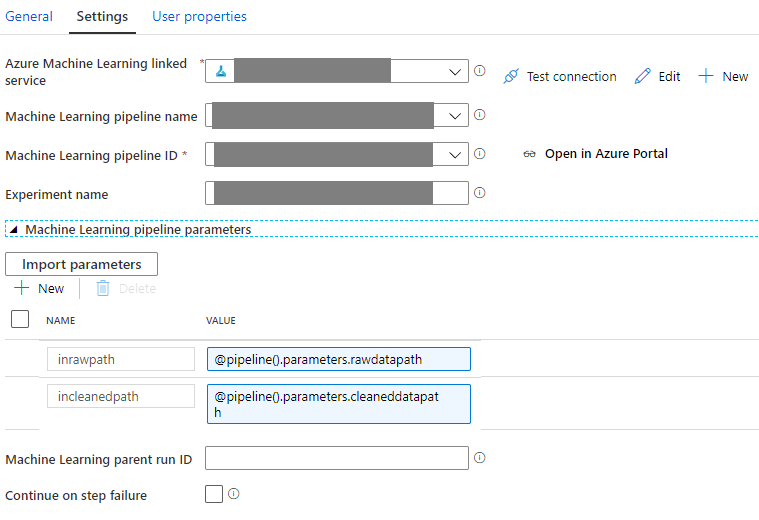
0 ответов
Этот блокнот демонстрирует использование
DataPath и
PipelineParametersв AML Pipeline. Вы узнаете, как струны и
DataPath можно параметризовать и отправить в AML Pipelines через
PipelineParameters. Вы можете параметризовать входной набор данных, и вот образец записной книжки, в котором показано, как это сделать.
В настоящее время,
ParallelRunStepпринимает набор данных в качестве входных данных. вы можете добавить еще один шаг перед
ParallelRunStep для создания объекта набора данных, указывающего на новые данные, и перехода к
ParallelRunStep. Вот пример использования нескольких шагов:
Для вывода, если вы используете
append_row действие вывода, вы можете настроить имя выходного файла с помощью
append_row_file_nameconfig. Вывод будет сохранен в большом двоичном объекте по умолчанию. Чтобы переместить его в другой магазин, мы предлагаем использовать другой
DataTransferStep после
ParallelRunStep. Следуйте этому примеру для шага передачи данных:
Получил ответ от Microsoft(см. Эту ветку здесь). Группа разработчиков продукта фабрики данных Azure подтверждает, что на сегодняшний день в фабрике данных Azure (ADF) не поддерживается тип данных для параметра DataPath. Тем не менее, для этого уже есть функция, и работа над ней продолжается. Эта функция будет частью ноябрьского выпуска.
Входные параметры выглядят как строка, попробуйте изменить их как тип данных объекта. Согласно документации, он ожидает параметров объекта {"Key": "value"}.