Анализ настроений в R с использованием TDM/DTM
Я пытаюсь применить анализ настроений в R с помощью моего DTM (матрица терминов документа) или TDM (матрица терминов документа). Я не мог найти аналогичные темы на форуме и в Google. Таким образом, я создал корпус, и из этого корпуса я сгенерировал значение dtm/tdm в R. Мой следующий шаг - применить анализ настроений, который мне понадобится позже, для прогнозирования запасов через SVM. Мой дать код таков:
dtm <- DocumentTermMatrix(docs)
dtm <- removeSparseTerms(dtm, 0.99)
dtm <- as.data.frame(as.matrix(dtm))
tdm <- TermDocumentMatrix(docs)
tdm <- removeSparseTerms(tdm, 0.99)
tdm <- as.data.frame(as.matrix(tdm))
Я прочитал, что это возможно через пакет tidytext с помощью функции get_sentiments(). Но было невозможно применить это с DTM/TDM. Как я могу выполнить анализ настроений для моих очищенных фильтрующих слов, которые уже определены, токены и т. Д.? Я видел, что многие люди делали анализ настроений для пробного предложения, но я хотел бы применить его к моим отдельным словам, чтобы увидеть, являются ли они положительными, отрицательными, оценками и т. Д. Большое спасибо заранее!
2 ответа
SentimentAnalysis имеет хорошую интеграцию с tm,
library(tm)
library(SentimentAnalysis)
documents <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.",
"The waiter forget about my dessert -- what poor service!")
vc <- VCorpus(VectorSource(documents))
dtm <- DocumentTermMatrix(vc)
analyzeSentiment(dtm,
rules=list(
"SentimentLM"=list(
ruleSentiment, loadDictionaryLM()
),
"SentimentQDAP"=list(
ruleSentiment, loadDictionaryQDAP()
)
)
)
# SentimentLM SentimentQDAP
# 1 0.000 0.1428571
# 2 0.000 0.0000000
# 3 0.000 0.0000000
# 4 0.000 0.0000000
# 5 0.000 0.0000000
# 6 -0.125 -0.2500000
Чтобы использовать tidytext в dtm для получения настроений, сначала преобразуйте dtm в формат tidy, а затем выполните внутреннее соединение между данными tidy и словарем поляризованных слов. Я буду использовать тот же документ, что и выше. Некоторые документы в приведенном выше примере являются положительными, но получают оценку по шкале нейтрела. давайте посмотрим, как работает Tidytext
library(tidytext)
library(tm)
library(dplyr)
library(tidyr)
documents <- c("Wow I really like the new light sabers",
"That book was excellent",
"R is a fantastic language",
"The service in this restaurant was miserable",
"This is neither positive or negative",
"The waiter forget about my dessert -- what poor service")
# create tidy format
vectors <- as.character(documents)
v_source <- VectorSource(vectors)
corpuss <- VCorpus(v_source)
dtm <- DocumentTermMatrix(corpuss)
as_tidy <- tidy(dtm)
# Using bing lexicon: you can use other as well(nrc/afinn)
bing <- get_sentiments("bing")
as_bing_words <- inner_join(as_tidy,bing,by = c("term"="word"))
# check positive and negative words
as_bing_words
# set index for documents number
index <- as_bing_words%>%mutate(doc=as.numeric(document))
# count by index and sentiment
index <- index %>% count(sentiment,doc)
# spread into positives and negavtives
index <- index %>% spread(sentiment,n,fill=0)
# add polarity scorer
index <- index %>% mutate(polarity = positive-negative)
index
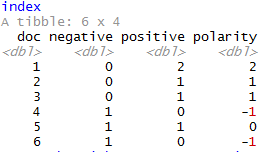
Док 4 и 6 отрицательные,5 нейтрелей и остальные положительные, что на самом деле имеет место