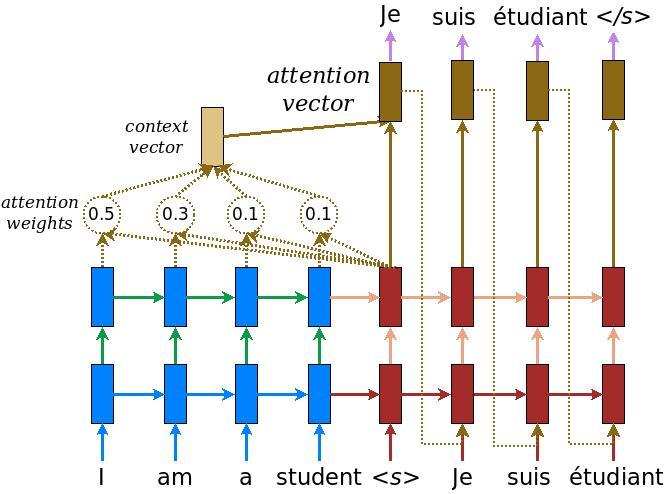
Запустить токен в LSTM-декодере
Я понимаю модель кодера-декодера и то, как выходной сигнал кодера будет входом декодера. Предположим, что здесь у меня есть только модель декодера, у меня есть декодер initial_state (т.е. даны decoder_states_inputs).
Я хочу, чтобы "decoder_inputs" был стартовым токеном (например,
decoder_lstm = LSTM(n_units, return_sequences=True, return_state=True)
decoder_outputs, state_h, state_c = decoder_lstm(decoder_inputs, initial_state=decoder_states_inputs)
Кроме того, я должен добавить стартовый токен к моим оригинальным последовательностям? то есть:
<start> statemnt1
<start> statemnt2
....
1 ответ
Как добавить <start> а также <end> Символ действительно зависит от того, как вы реализуете остальную часть модели, но в большинстве случаев результаты совпадают. Например, в официальном примере тензорного потока он добавляет эти символы в каждое предложение.
def preprocess_sentence(w):
# other preprocessing
w = w.rstrip().strip()
# adding a start and an end token to the sentence
# so that the model know when to start and stop predicting.
w = '<start> ' + w + ' <end>'
return w
# rest of the code
# ... word2idx is a dictionary that map words into unique ids
Затем в части токенизации <start> а также <end> символы отображаются на 4 и 5 соответственно. Но, как вы можете видеть на картинке, он только кормит <start> на входе декодера и <end> на выход декодера. Это означает, что наши данные похожи на:
decoder_inp = raw_decoder_input[:, 0:-1]
decoder_out = raw_decoder_input[:, 1:]