Service Fabric Stateful Service в Azure - использование ОЗУ продолжает расти. Возможная утечка памяти
Я запускаю приложение Service Fabric в кластере в Azure. Кластер имеет два набора шкал:
- 4 узла B2ms, где тип сервиса с состоянием размещается с ограничениями размещения (первичный набор масштабов)
- 2x F1 узла, где размещен тип сервиса без сохранения состояния.
В приложении есть два типа услуг
- WebAPI - служба без сохранения состояния, используемая для получения статусов из системы через HTTP и отправки их в StatusConsumer.
- StatusConsumer - сервис с отслеживанием состояния, который обрабатывает статусы и сохраняет последний. Экземпляр службы создается для каждой системы. Общается через RemotingV2.
Для своих тестов я использую Application Insights и Service Fabric Analytics для отслеживания производительности. Я наблюдаю следующие параметры:
Метрики для установленного масштаба: процент загрузки процессора, операции чтения с диска / записи в секунду
Applicaiton Insights: время отклика сервера - соответствует времени выполнения метода, который получает статусы в StateC Statusuonsumer.
Service Fabric Analytics: счетчики производительности с агентом анализа журнала на узлах с отслеживанием состояния - используются для наблюдения за использованием ОЗУ узлами.
Каждая моделируемая система отправляет свой статус каждые 30 секунд.
В начале теста использование ОЗУ составляет около 40% для каждого узла, время отклика сервера Avg составляет около 15 мс, загрузка ЦП составляет около 10%, а операции чтения / записи менее 100/ с.
Сразу после начала теста использование ОЗУ начинает медленно нарастать, но в других наблюдаемых показателях нет никакой разницы.
Примерно через час моделирования 1000 систем использование оперативной памяти составляет около 90-95%, и проблемы начинают проявляться в других показателях - пики времени отклика сервера Avg со значениями примерно 5-10 секунд, а операции чтения / записи диска достигают примерно 500/ сек.,
Это продолжается в течение 1-3 минут, затем использование оперативной памяти падает, и все возвращается к нормальной жизни. 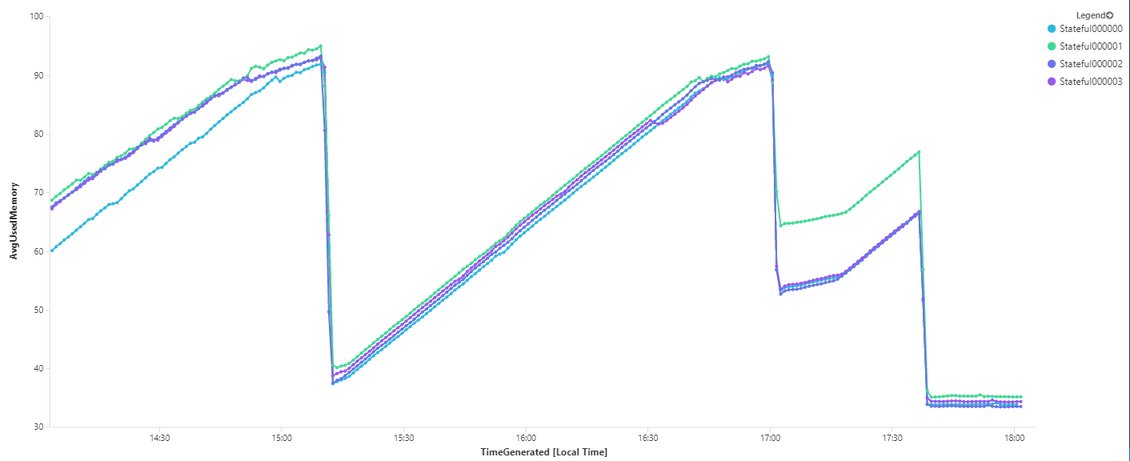
На изображениях видно, что пик ОЗУ соответствует пику времени отклика сервера. В конце графика ОЗУ использование является плоским, чтобы показать, каково поведение без моделирования каких-либо систем.
Количество моделируемых систем только уменьшает или увеличивает время, необходимое ОЗУ для достижения критических уровней - в одном из тестов было смоделировано 200 систем, и рост использования ОЗУ был медленнее.
Что касается кода: в первых тестах код был более сложным, но чтобы найти причину проблемы, я начал удалять функциональность. Все еще не было никакого улучшения. Единственный раз, когда использование оперативной памяти не увеличивалось, это когда я комментировал весь код, а в теле метода, который получает статус, были только блок try / catch и return. В настоящее время код в StatusConsumer такой:
public async Task PostStatus(SystemStatusInfo status){
try{
Stopwatch stopWatch = new Stopwatch();
IReliableDictionary<string, SystemStatusInfo> statusDictionary = await this.StateManager.GetOrAddAsync<IReliableDictionary<string, SystemStatusInfo>>("status");
stopWatch.Start();
using (ITransaction tx = this.StateManager.CreateTransaction())
{
await statusDictionary.AddOrUpdateAsync(tx,"lastConsumedStatus",(key) => { return status; },(key, oldvalue) => status);
await tx.CommitAsync();
}
stopWatch.Stop();
if (stopWatch.ElapsedMilliseconds / 1000 > 4) //seconds
{
Telemetry.TrackTrace($"Queue Status Duration: { stopWatch.ElapsedMilliseconds / 1000 } for {status.SystemId}", SeverityLevel.Critical);
}
}
catch (Exception e) {Telemetry.TrackException(e);}
}
Как я могу диагностировать и / или исправить это?
PS: после подключения к узлам с удаленным рабочим столом в диспетчере задач я вижу, что при использовании ОЗУ около 85% "Память" процесса SystemStatusConsumer, который "держит" экземпляры микросервиса, составляет не более 600 МБ. Это самый высокий уровень потребления, но он все еще не так высок - узел с 8 ГБ ОЗУ. Однако я не знаю, является ли это полезной информацией в этом случае.
0 ответов
После разговора со службой поддержки Azure и нескольких тестов я резко снизил потребление памяти службами.
Основное, что я узнал из общения со службой поддержки, было то, что на самом деле не рекомендуется иметь большое количество сервисов, каждый из которых содержит небольшой объем данных! Дамп памяти приложения показал, что каждая служба имеет примерно 20 КБ фактических данных и 700 КБ журналов изменений в надежных коллекциях, накопленных Service Fabric. Возможно, это не точные цифры, но разница была огромной.
Чтобы уменьшить количество сервисов, я объединил обработку и сохранение статусов нескольких систем в один сервис, используя своего рода разбиение. Я также пробовал использовать Актеров. Все методы работали хорошо.
Есть несколько других настроек, которые я использовал для уменьшения потребления памяти, но большая разница была достигнута за счет изменения архитектуры самих сервисов:
В файле Settings.xml самого сервиса:
CheckpointThresholdInMB = 1
LogTruncationIntervalSeconds = 1200 (Установка этого значения меньше 120 на самом деле ничего не делает или ухудшает ситуацию. Попробуйте использовать значения больше 300)
MaxAccumulatedBackupLogSizeInMB = 1
В коде самой услуги:
ServicePointManager.DefaultConnectionLimit = 200
MaxConcurrentCalls = 512 (RemotingListener и клиент)
Настройки кластера:
- AutomaticMemoryConfiguration - 0 (Если вы не установите этот параметр, остальные работать не будут)
- WriteBufferMemoryPoolMinimumInKB - 16 МБ.
- WriteBufferMemoryPoolMaximumInKB - 32 МБ.