Почему у моей тренировочной потери есть регулярные всплески?
Я тренирую модель обнаружения объектов Keras, связанную в нижней части этого вопроса, хотя я считаю, что моя проблема не связана ни с Keras, ни с конкретной моделью, которую я пытаюсь обучить (SSD), а с тем, как данные передается модели во время обучения.
Вот моя проблема (см. Изображение ниже): Моя потеря тренировок в целом уменьшается, но она показывает резкие регулярные всплески:

Единица на оси X - это не тренировочные эпохи, а десятки тренировочных шагов. Пики происходят точно один раз каждые 1390 тренировочных шагов, что является точным количеством тренировочных шагов за один полный проход по моему тренировочному набору данных.
Тот факт, что пики всегда возникают после каждого полного прохождения набора данных обучения, заставляет меня подозревать, что проблема не в самой модели, а в данных, которые она передает во время обучения.
Я использую генератор пакетов, предоставленный в репозитории, для генерации пакетов во время обучения. Я проверил исходный код генератора и он перетасовывает набор обучающих данных перед каждым проходом, используя sklearn.utils.shuffle,
Я полностью сбит с толку по двум причинам:
- Набор обучающих данных перемешивается перед каждым проходом.
- Как вы можете видеть в этой записной книжке Jupyter, я использую специальные возможности генерации данных генератора, поэтому теоретически набор данных никогда не должен быть одинаковым для любого прохода: все дополнения являются случайными.
Вот почему я не понимаю эту схему в функции потерь. Используя специальное увеличение данных и перетасовку набора данных перед каждым проходом, я в основном разрушаю любую структуру в наборе данных: крайне маловероятно, что одно и то же преобразование данного изображения когда-либо будет происходить дважды во время обучения, и все же шипы возникают точно после каждого полного прохода по набору данных, как по маслу.
Я сделал несколько тестовых прогнозов, чтобы увидеть, действительно ли модель изучает что-нибудь, и это так! Прогнозы со временем становятся все лучше и лучше, но, конечно, модель учится очень медленно, так как эти всплески, кажется, портят градиент каждые 1390 шагов.
Любые намеки относительно того, что это может быть, с благодарностью! Я использую ту же самую тетрадь Jupyter, которая связана выше для моей тренировки, единственная переменная, которую я изменил, - это размер пакета от 32 до 16. Кроме этого, связанная тетрадь содержит точный учебный процесс, за которым я следую.
Вот ссылка на репозиторий, содержащий модель:
6 ответов
Я понял это сам:
TL; DR:
Убедитесь, что величина потерь не зависит от размера мини-партии.
Длинное объяснение:
В моем случае проблема была специфичной для Кераса.
Возможно, решение этой проблемы кому-то пригодится в какой-то момент.
Оказывается, Керас делит потери по размеру мини-партии. Здесь важно понять, что усреднение по размеру партии происходит не по самой функции потерь, а по усреднению происходит где-то еще в процессе обучения.
Почему это важно?
Модель, которую я тренирую, SSD, использует довольно сложную функцию потери многозадачности, которая выполняет свое усреднение (не по размеру пакета, а по количеству ограничивающих рамок истинности в пакете). Теперь, если функция потерь уже делит потери на некоторое число, которое коррелирует с размером партии, а затем Keras делит на размер партии во второй раз, то внезапно величина значения потери начинает зависеть от размера партии (если быть точным, оно становится обратно пропорциональным размеру партии).
Теперь обычно число выборок в вашем наборе данных не является целым числом, кратным выбранному вами размеру пакета, поэтому самая последняя мини-партия эпохи (здесь я неявно определяю эпоху как один полный проход по набору данных) будет содержать меньше образцов, чем размер партии. Это то, что портит величину потерь, если она зависит от размера партии, и, в свою очередь, портит величину градиента. Поскольку я использую оптимизатор с импульсом, этот перепутанный градиент продолжает влиять на градиенты нескольких последующих тренировочных шагов.
После того, как я скорректировал функцию потерь, умножив потери на размер партии (таким образом, изменив последующее деление Keras на размер партии), все было хорошо: больше не было пиков в потере.
Для тех, кто работает в PyTorch, простое решение, которое решает эту конкретную проблему, заключается в DataLoader отбросить последнюю партию:
train_loader = torch.utils.data.DataLoader(train_set, batch_size=batch_size, shuffle=False,
pin_memory=(torch.cuda.is_available()),
num_workers=num_workers, drop_last=True)
Я бы добавил отсечение градиента, потому что это предотвращает скачки в градиентах, чтобы испортить параметры во время тренировки.
Градиентное обрезание - это метод предотвращения взрыва градиентов в очень глубоких сетях, обычно в рекуррентных нейронных сетях.
Большинство программ позволяет вам добавить параметр отсечения градиента в ваш оптимизатор на основе GD.
Для меня решение и причина проблемы были немного другими.
Проблема по-прежнему будет возникать при определении размера пакета равным 1 или правильному делителю общего количества образцов (чтобы последний пакет все равно был полным).
ТЛ;ДР;
Это артефакт метрики из-за усреднения, который не влияет на обучение. Показатель потерь по умолчанию — это средний убыток за всю текущую эпоху, вплоть до момента, когда вы его прочитали. Вы можете увидеть потери для каждой партии, используя
def on_batch_begin(batch, logs):
model.reset_metrics()
return
lambda_callback = tf.keras.callbacks.LambdaCallback(on_batch_begin=on_batch_begin)
и сдать его при обучении с
model.fit(..., callbacks=[lambda_callback])
Обратите внимание, что это, очевидно, приведет к тому, что все метрики будут сообщать только о последней потере обучающего пакета для каждой эпохи.
Объяснение
Мне удалось определить проблему, как только я заметил это
reset_states()позвони в
model.fit()метод . Я также понял, что это не произойдет в каждом пакете кода пакетного цикла или train_step, поэтому я пошел исследовать дальше.
Глядя на класс, можно увидеть, что функция накапливается и взвешивается по
batch_sizeкак упомянул @Alex. Позже это значение снижается до среднего значения (поскольку это
Meaninstance ), который, наконец, отображает метрику потерь, которую мы видим.
Хорошая новость в том, что_total_loss_meanна самом деле не используется в процессе обучения, поскольку это не значение, возвращаемое функциейLossesContainer's
__call__().
На изображении ниже показан обучающий эксперимент с (серым) и без (розового) «исправления». Это было сделано поверх примера MNIST Tensorflow . В нем можно увидеть эффект усреднения по фактическим данным.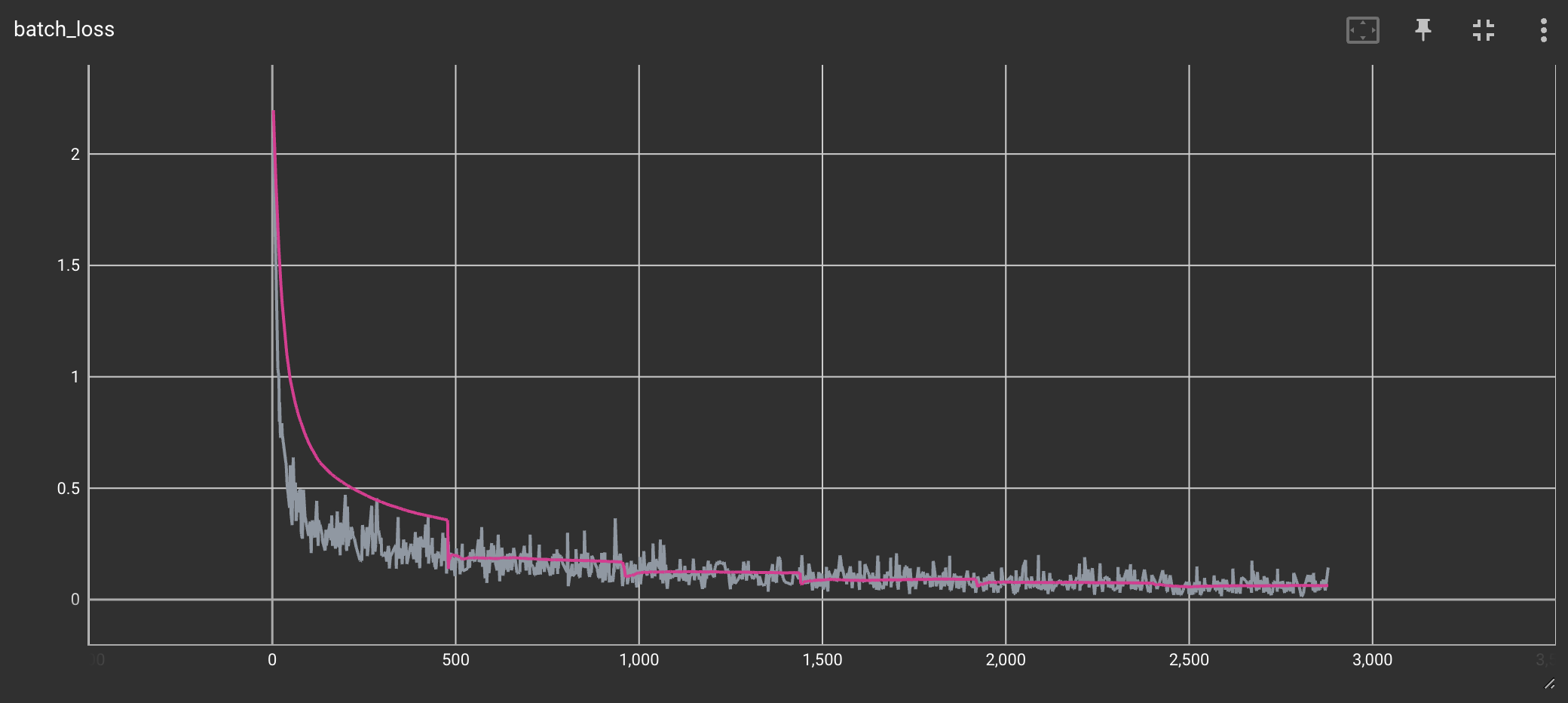
Я столкнулся с аналогичной проблемой при использовании tensorflow. В моем случае проблема не была связана с размером мини-партии. Реальная проблема заключалась в том, что тензорный поток не полностью перетасовывал данные из-за ограничения, установленного буфером_размера, как описано здесь https://www.tensorflow.org/api_docs/python/tf/data/Dataset#shuffle . Для идеального перетасовывания буфер_размер должен быть больше или равен полному размеру набора данных.
Мне помогло изменение значений по умолчанию оптимизатора Adam:
from keras.optimizers import Adam
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5), metrics=['accuracy'])