Точность результата алгоритма NEAT
Я аспирант, который пытается использовать NEAT алгоритм в качестве контроллера для робота, и у меня есть некоторые проблемы с точностью с ним. Я работаю с Python 2.7 и для него, и я использую два NEAT реализации Python:
-
NEATкоторый находится в этом репозитории GitHub: https://github.com/CodeReclaimers/neat-python Поиск в Google, похоже, он использовался в некоторых проектах с успехом. -
multiNEATбиблиотека, разработанная Питером Червенски и Шейном Райаном: http://www.multineat.com/index.html. Который появляется на "официальной" странице программного обеспеченияNEATкаталог программного обеспечения.
При тестировании первого я обнаружил, что моя программа быстро сходится к решению, но это решение недостаточно точное. В качестве недостатка точности я хочу сказать, что отклонение как минимум на 3-5% от медианы и среднего связано с "идеальным" решением в конце эволюции (в зависимости от сложности проблемы ошибка около 10% Это нормально для моих решений. Более того, я мог бы сказать, что я "никогда" не видел значение ошибки ниже 1% между решением, данным NEAT и решение, которое это правильное). Я должен сказать, что я пробовал много разных комбинаций параметров и конфигураций (это старая проблема для меня).
В связи с этим я протестировал вторую библиотеку. MultiNEAT Библиотека сходится быстрее и проще, чем предыдущая. (Я предполагаю, что это из-за реализации C++ вместо чистого Python) Я получаю аналогичные результаты, но у меня все еще есть та же проблема; недостаток точности Эта вторая библиотека также имеет различные параметры конфигурации, и я не нашел правильного сочетания их для повышения производительности проблемы.
Мой вопрос:
Нормально ли это отсутствие точности в NEAT Результаты? Он достигает хороших решений, но недостаточно хорош для управления роботизированной рукой, для чего я и хочу его использовать.
Я напишу, что делаю, если кто-то увидит какую-то концептуальную или техническую ошибку в том, как я изложил свою проблему:
Чтобы упростить задачу, я покажу очень простой пример: мне нужно решить очень простую задачу, я хочу NN, который может вычислить следующую функцию: y = x^2 (похожие результаты найдены с y=x^3 или же y = x^2 + x^3 или аналогичные функции)
Шаги, которые я выполняю при разработке программы:
- "Y" - это входы в сеть, а "X" - выходы. Функции активации нейронной сети являются сигмоидальными функциями.
- Я создаю набор данных из "n" выборок с заданными значениями "X" между
xmin = 0.0иxmax = 10.0 Поскольку я использую сигмоидальные функции, я делаю нормализацию значений "Y" и "X":
- "Y" нормализуется линейно между (Ymin, Ymax) и (-2,0, 2,0) (диапазон входных значений сигмовидной кишки).
- "X" нормируется линейно между (Xmin, Xmax) и (0.0, 1.0) (выходной диапазон сигмоида).
После создания набора данных я подразделяю на выборку поезда (70% процентов от общего количества), проверочный образец и тестовый образец (по 15% каждый).
На этом этапе я создаю популяцию людей для эволюции. Каждый человек из популяции оценивается во всех выборках поездов. Каждая позиция оценивается как:
eval_pos = xmax - abs (xtarget - получено)
А пригодность человека - это среднее значение всех позиций поезда (я тоже выбрал минимум, но это дает мне худшие показатели).
После всей оценки я проверяю лучшего полученного человека на тестовом образце. И вот где я получил эти "неточные значения". Более того, во время процесса оценки максимальное значение, где "abs(xtarget - xobtained) = 0" никогда не получается.
Кроме того, я предполагаю, что то, как я манипулирую данными, правильно, потому что я использую тот же набор данных для обучения нейронной сети в Keras и я получаю намного лучшие результаты, чем с NEAT (ошибка менее 1% достижима после 1000 эпох в слое с 5 нейронами).
На этом этапе я хотел бы знать, нормально ли то, что происходит, потому что я не должен использовать набор данных для разработки контроллера, его нужно изучать "онлайн" и NEAT выглядит как подходящее решение для моей проблемы.
Заранее спасибо.
РЕДАКТОРНАЯ ПОЧТА:
Во-первых, спасибо за комментарий ник. Я отвечу на ваши вопросы ниже:
Я использую
NEATалгоритм.Да, я провел эксперименты по увеличению числа людей в популяции и количества поколений. Типичный график, который я получаю, выглядит так:
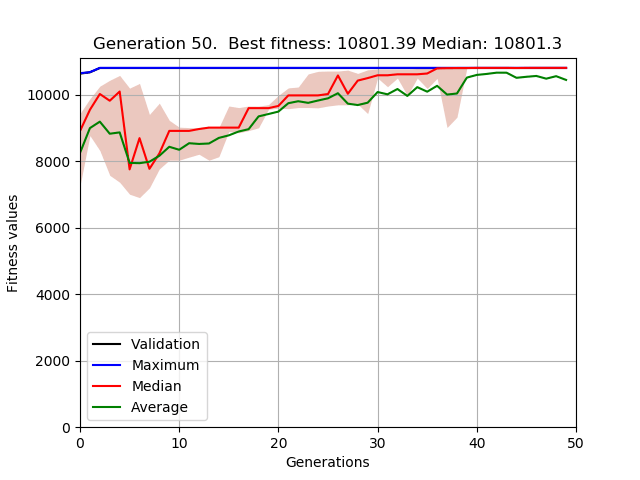
Хотя численность населения в этом примере не такая большая, я получил аналогичные результаты в экспериментах, увеличивающих количество особей или количество поколений. Например, население 500 особей и 500 поколений. В этих экспериментах алгоритм быстро сходится к решению, но, находясь там, лучшее решение застревает, и оно больше не улучшается.
Как я упоминал в моем предыдущем посте, я попробовал несколько экспериментов с множеством различных конфигураций параметров... и графика более или менее похожа на предыдущую.
Кроме того, два других эксперимента, которые я попробовал: когда эволюция достигает точки, где максимальное значение и медиана сходятся, я генерирую другую популяцию на основе этого генома с новыми параметрами конфигурации, где:
Параметры мутации изменяются с высокой вероятностью мутации (вес и вероятность нейрона), чтобы найти новые решения с целью "перепрыгнуть" из текущего генома в другой.
- Мутация нейрона снижена до 0, а вес
mutation probability"увеличение для"mutate weight"в более низком диапазоне, чтобы получить небольшие модификации с целью лучшей регулировки весов. (пытаясь получить" подобную "функциональность как backprop. внесение незначительных изменений в весах)"
- Мутация нейрона снижена до 0, а вес
Эти два эксперимента не сработали, как я ожидал, и лучший геном популяции был таким же, как и у предыдущей популяции.
- Извините, но я не очень хорошо понимаю, что вы хотите сказать, "применяя ваши собственные взвешенные штрафы и вознаграждения в вашей функции пригодности". Что вы подразумеваете под включением штрафов за вес в функцию фитнеса?
С уважением!
2 ответа
Отказ от ответственности: я внес вклад в эти библиотеки.
Вы пытались увеличить численность населения, чтобы ускорить поиск и увеличить количество поколений? Я использую его для торговой задачи, и, увеличив численность населения, мои чемпионы были найдены намного раньше.
Еще одна вещь, о которой стоит подумать, - это применить ваши собственные взвешенные штрафы и вознаграждения в вашей функции фитнеса, чтобы все, что не подходит очень близко, "убилось" раньше и правильный геном был найден быстрее. Следует отметить, что Нит использует функцию фитнеса для обучения, в отличие от градиентного спуска, поэтому он не будет сходиться таким же образом, и, возможно, вам придется тренироваться немного дольше.
Последний вопрос, вы используете аккуратный или hyperneat algo от multineat?
Эй, я думаю, начну с того, что если бы вы попробовали все это, я бы, возможно, хотел бы переписать эксперимент с гипернеатом или эс-гипернеатом, поскольку они на самом деле немного отличаются от оригинального аккуратного алгоритма, генетика такая же, но сети производятся по разному. Что касается штрафов, я имею в виду функцию пригодности для эксперимента, который вы проводите, и функцию пригодности, которую вы используете для оценки сети, но, к сожалению, я не думаю, что смогу сильно помочь, если вы не разместите здесь больше контекст (мне очень жаль, поскольку вы предоставили много, но блок кода действительно помог бы мне быть в состоянии помочь вам).