Как вычисляется "сложная" оценка полярности Вейдера в Python NLTK?
Я использую Vader SentimentAnalyzer для получения оценок полярности. Раньше я использовал оценки вероятности для положительного / отрицательного / нейтрального, но я только что понял, что "сложный" показатель в диапазоне от -1 (большинство отрицательных) до 1 (большинство положительных) обеспечит единственную меру полярности. Интересно, как вычисляется "сложный" балл? Это рассчитывается из вектора [pos, neu, neg]?
1 ответ
Алгоритм VADER выводит оценки настроения для 4 классов настроений https://github.com/nltk/nltk/blob/develop/nltk/sentiment/vader.py:
neg: Отрицательныйneu: Нейтральныйpos: Положительныйcompound: Соединение (т. Е. Совокупный балл)
Давайте пройдемся по коду, первый экземпляр соединения находится по адресу https://github.com/nltk/nltk/blob/develop/nltk/sentiment/vader.py, где он вычисляет:
compound = normalize(sum_s)
normalize() Функция определена как таковая на https://github.com/nltk/nltk/blob/develop/nltk/sentiment/vader.py:
def normalize(score, alpha=15):
"""
Normalize the score to be between -1 and 1 using an alpha that
approximates the max expected value
"""
norm_score = score/math.sqrt((score*score) + alpha)
return norm_score
Так что есть гипер-параметр alpha,
Для sum_s, это сумма аргументов настроения, переданных score_valence() функция https://github.com/nltk/nltk/blob/develop/nltk/sentiment/vader.py
И если мы проследим это sentiment аргумент, мы видим, что он вычисляется при вызове polarity_scores() функция на https://github.com/nltk/nltk/blob/develop/nltk/sentiment/vader.py:
def polarity_scores(self, text):
"""
Return a float for sentiment strength based on the input text.
Positive values are positive valence, negative value are negative
valence.
"""
sentitext = SentiText(text)
#text, words_and_emoticons, is_cap_diff = self.preprocess(text)
sentiments = []
words_and_emoticons = sentitext.words_and_emoticons
for item in words_and_emoticons:
valence = 0
i = words_and_emoticons.index(item)
if (i < len(words_and_emoticons) - 1 and item.lower() == "kind" and \
words_and_emoticons[i+1].lower() == "of") or \
item.lower() in BOOSTER_DICT:
sentiments.append(valence)
continue
sentiments = self.sentiment_valence(valence, sentitext, item, i, sentiments)
sentiments = self._but_check(words_and_emoticons, sentiments)
Глядя на polarity_scores функция, что он делает, это перебирать весь лексикон SentiText и проверяет с помощью правил sentiment_valence() функция для присвоения оценки валентности настроению https://github.com/nltk/nltk/blob/develop/nltk/sentiment/vader.py, см. раздел 2.1.1 http://comp.social.gatech.edu/papers/icwsm14.vader.hutto.pdf
Итак, возвращаясь к сложному баллу, мы видим, что:
compoundоценка - нормализованная оценкаsum_sа такжеsum_sявляется суммой валентности, вычисленной на основе некоторой эвристики и лексикона настроений (aka. Интенсивность настроений) и- нормализованный счет просто
sum_sделится на его квадрат плюс альфа-параметр, который увеличивает знаменатель функции нормализации.
Это рассчитывается из вектора [pos, neu, neg]?
Не совсем =)
Если мы посмотрим на score_valence Функция https://github.com/nltk/nltk/blob/develop/nltk/sentiment/vader.py, мы видим, что сложный балл вычисляется с sum_s до того, как положительные, отрицательные и новые оценки рассчитываются с использованием _sift_sentiment_scores() который вычисляет невидимые оценки pos, neg и neu, используя необработанные оценки из sentiment_valence() без суммы.
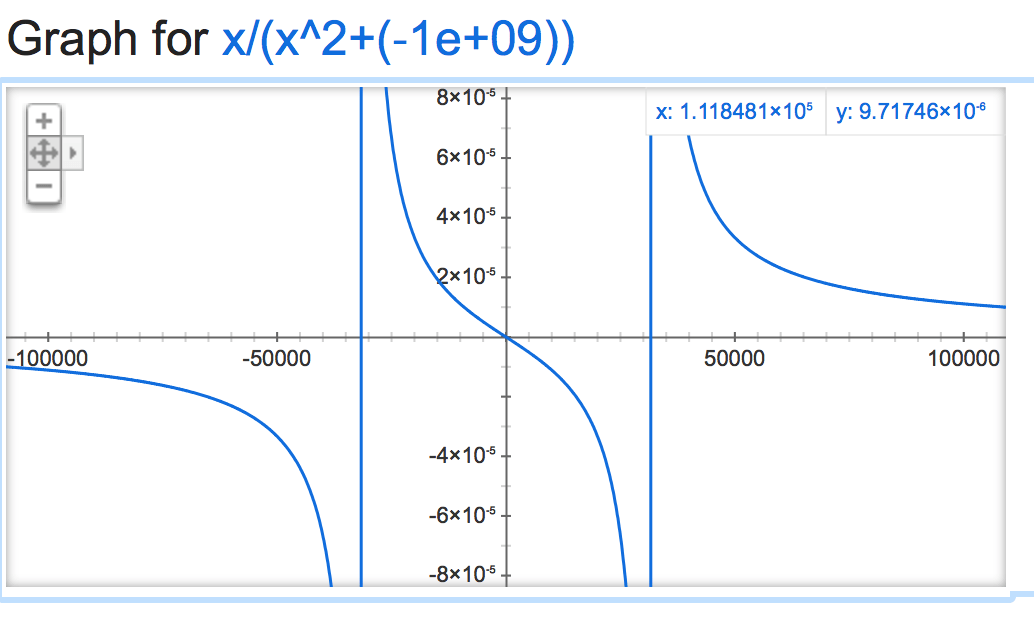
Если мы посмотрим на это alpha mathemagic, кажется, что результат нормализации довольно нестабилен (если оставить без ограничений), в зависимости от значения alpha:
alpha=0:
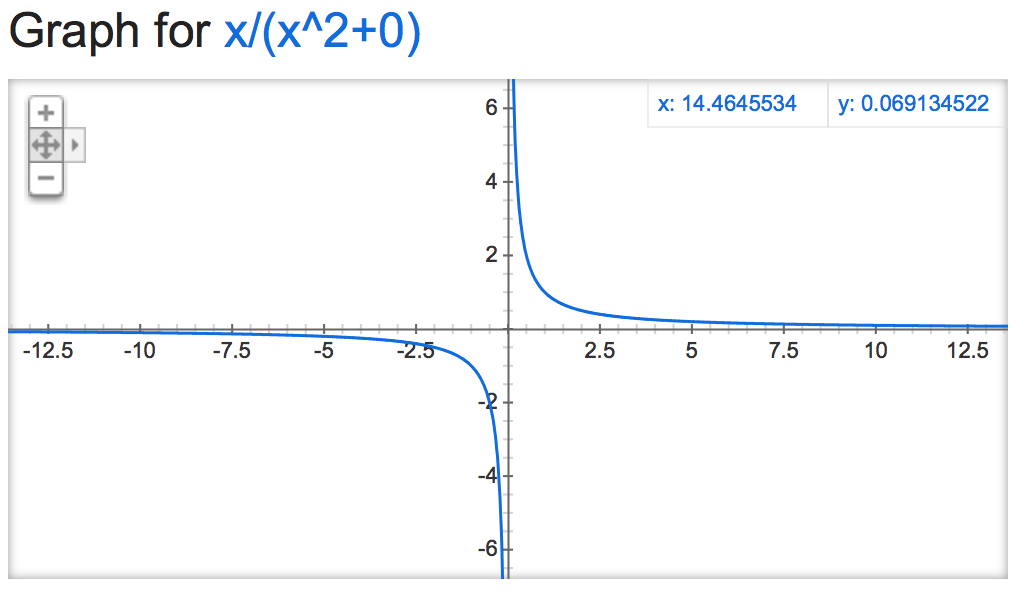
alpha=15:
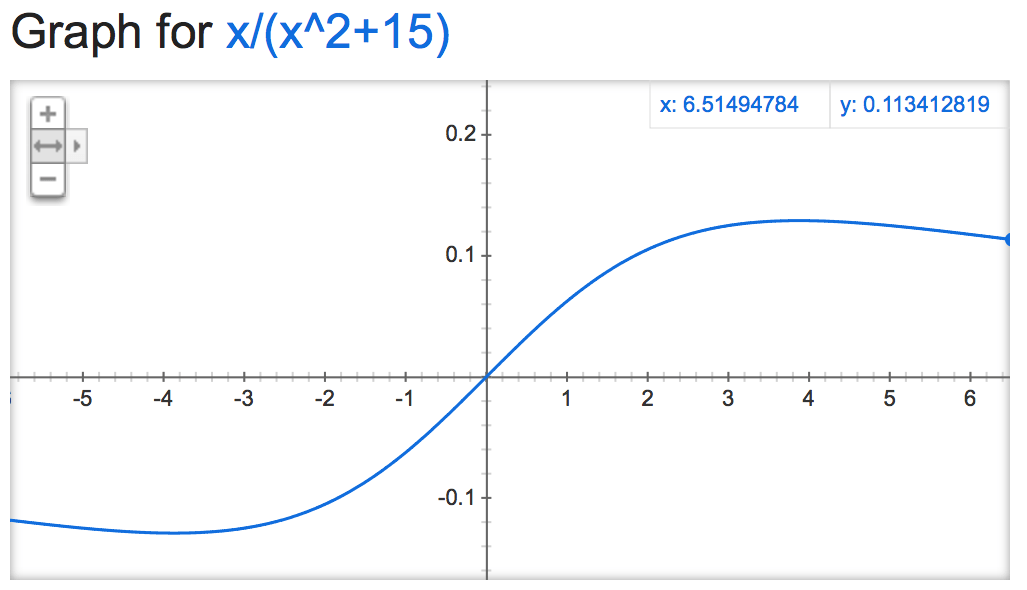
alpha=50000:
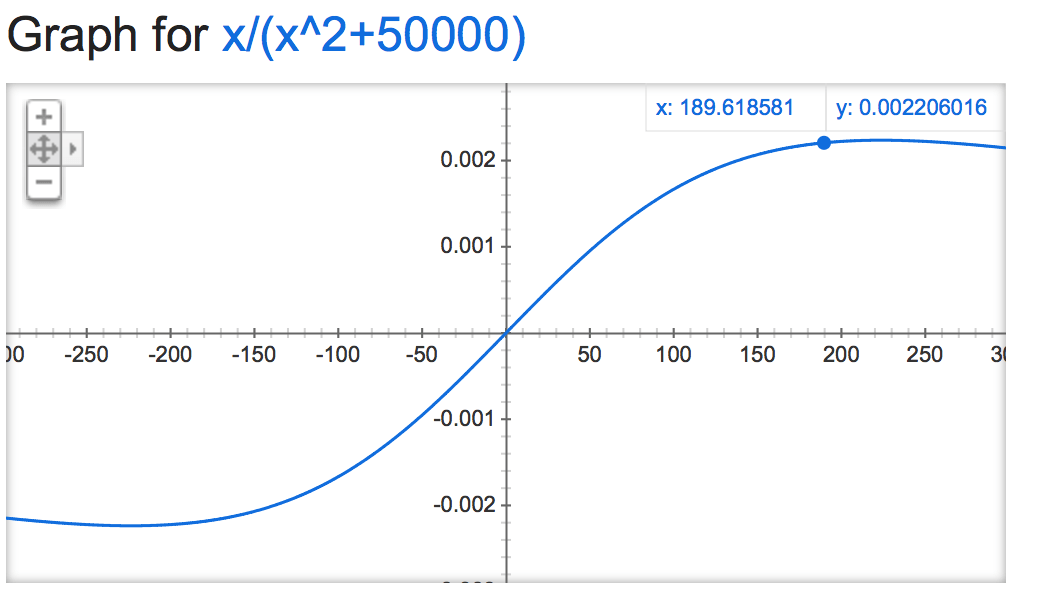
alpha=0.001:
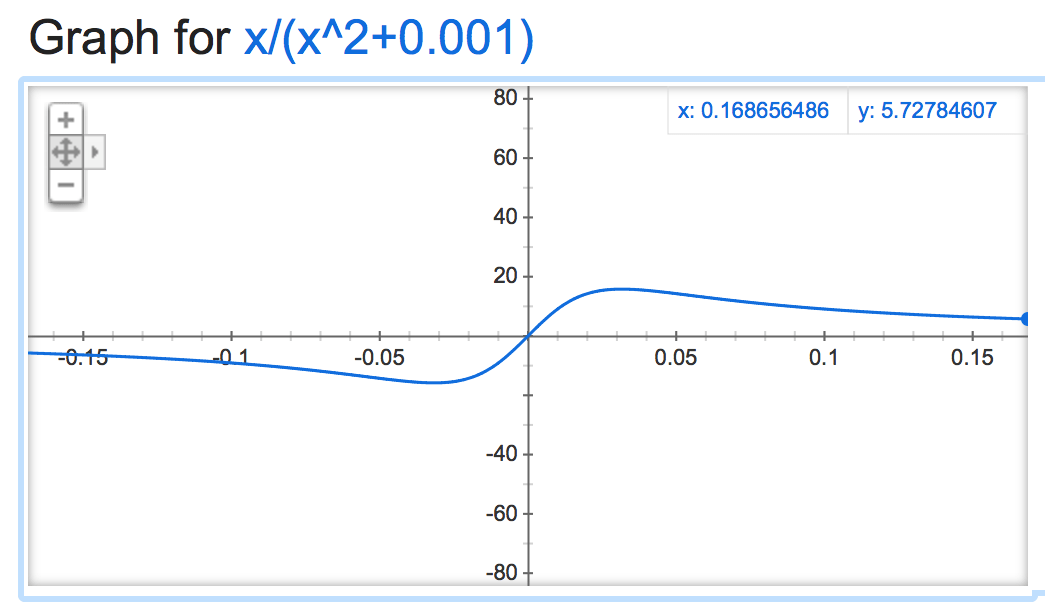
Становится весело, когда отрицательно:
alpha=-10:
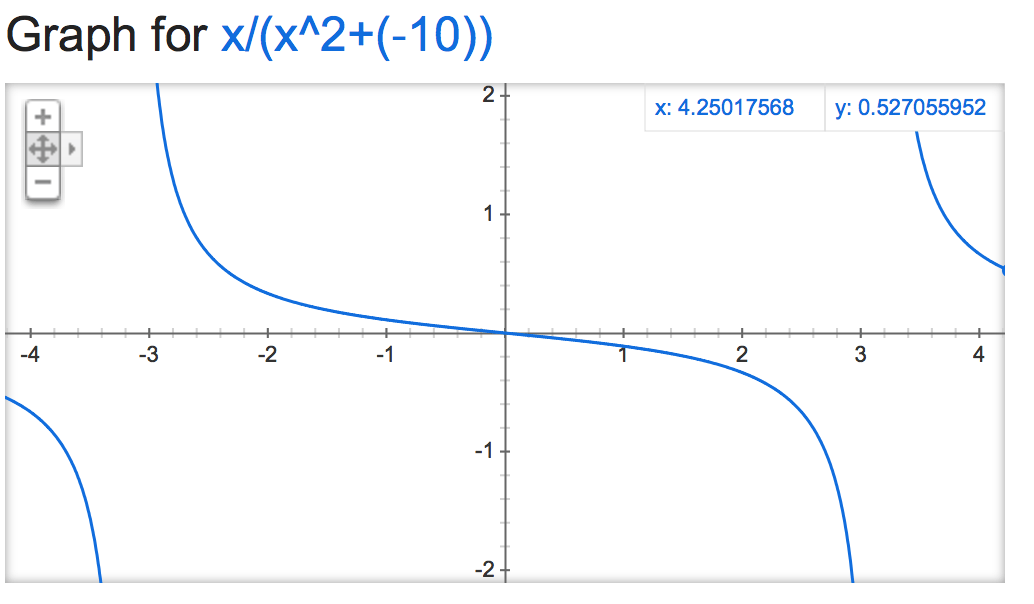
alpha=-1,000,000:
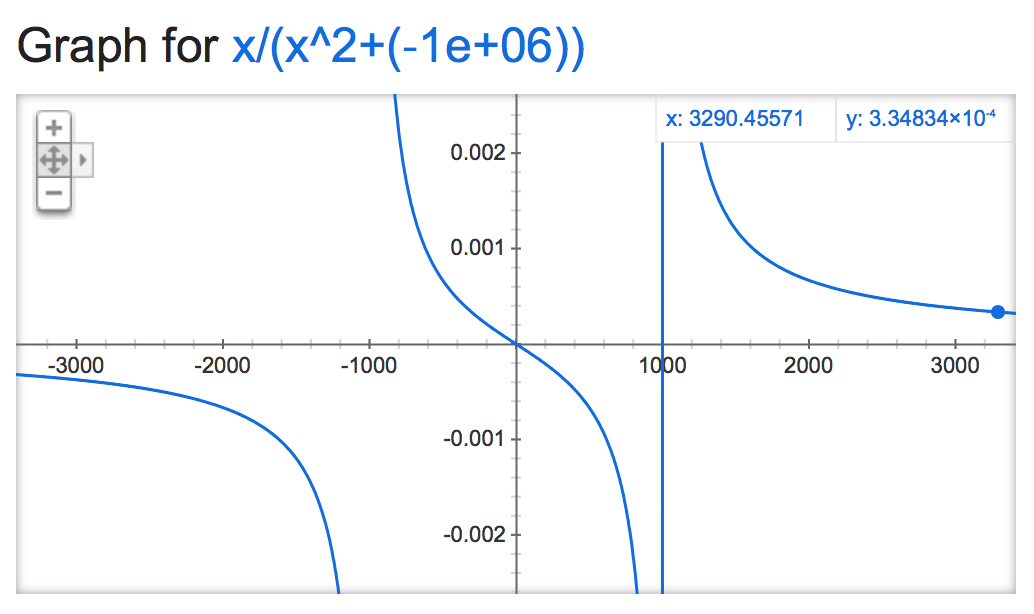
alpha=-1,000,000,000:
В разделе "О подсчете очков" в репозитории github есть описание.