Путаница матрицы и точность теста для учебника PyTorch Transfer Learning
Следуя учебному пособию по передаче Pytorch Transfer, я заинтересован в том, чтобы сообщать только о точности обучения и тестирования, а также о матрице путаницы (скажем, с помощью склеечной матрицы смешения). Как я могу это сделать? В текущем уроке сообщается только о точности обучения и оценки, и мне трудно разобраться, как включить в него код путаницы sklearn. Ссылка на оригинальный учебник здесь: https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html
%matplotlib inline
from graphviz import Digraph
import torch
from torch.autograd import Variable
# Author: Sasank Chilamkurthy
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
plt.ion()
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = "images"
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, classes = next(iter(dataloaders['train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
scheduler.step()
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['val']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images//2, 2, images_so_far)
ax.axis('off')
ax.set_title('predicted: {}'.format(class_names[preds[j]]))
imshow(inputs.cpu().data[j])
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, 9)
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,
num_epochs=25)
visualize_model(model_ft)
5 ответов
Ответ дан ptrblck сообщества PyTorch. Большое спасибо!
nb_classes = 9
confusion_matrix = torch.zeros(nb_classes, nb_classes)
with torch.no_grad():
for i, (inputs, classes) in enumerate(dataloaders['val']):
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model_ft(inputs)
_, preds = torch.max(outputs, 1)
for t, p in zip(classes.view(-1), preds.view(-1)):
confusion_matrix[t.long(), p.long()] += 1
print(confusion_matrix)
Чтобы получить точность для каждого класса:
print(confusion_matrix.diag()/confusion_matrix.sum(1))
Вот немного измененный (прямой) подход с использованием confusion_matrix sklearn:-
from sklearn.metrics import confusion_matrix
nb_classes = 9
# Initialize the prediction and label lists(tensors)
predlist=torch.zeros(0,dtype=torch.long, device='cpu')
lbllist=torch.zeros(0,dtype=torch.long, device='cpu')
with torch.no_grad():
for i, (inputs, classes) in enumerate(dataloaders['val']):
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model_ft(inputs)
_, preds = torch.max(outputs, 1)
# Append batch prediction results
predlist=torch.cat([predlist,preds.view(-1).cpu()])
lbllist=torch.cat([lbllist,classes.view(-1).cpu()])
# Confusion matrix
conf_mat=confusion_matrix(lbllist.numpy(), predlist.numpy())
print(conf_mat)
# Per-class accuracy
class_accuracy=100*conf_mat.diagonal()/conf_mat.sum(1)
print(class_accuracy)
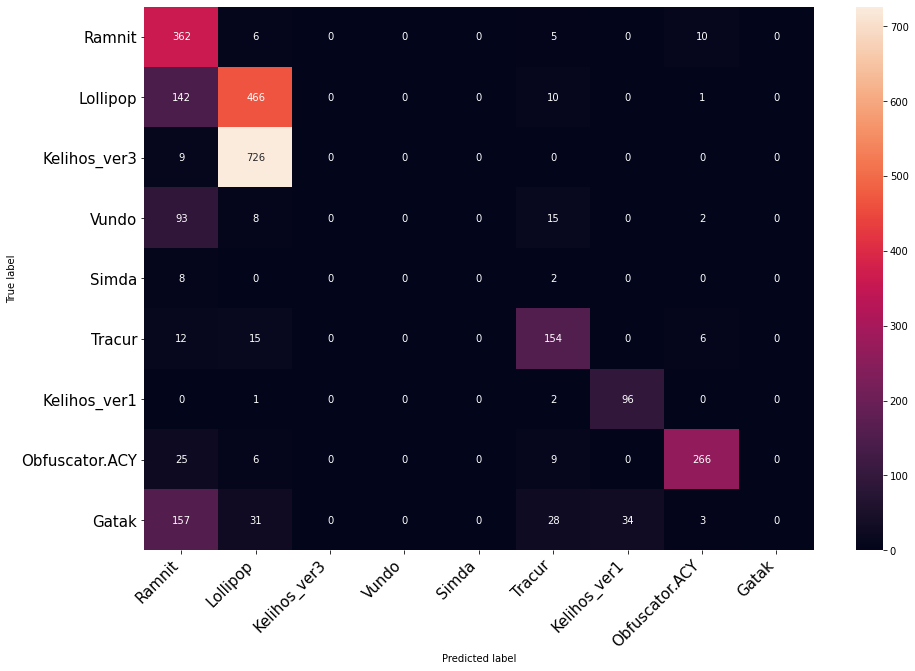
После ответа выше... Вот ответ с некоторой визуализацией
nb_classes = 9
confusion_matrix = np.zeros((nb_classes, nb_classes))
with torch.no_grad():
for i, (inputs, classes) in enumerate(test_loader):
inputs = inputs.to(DEVICE)
classes = classes.to(DEVICE)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for t, p in zip(classes.view(-1), preds.view(-1)):
confusion_matrix[t.long(), p.long()] += 1
plt.figure(figsize=(15,10))
class_names = list(label2class.values())
df_cm = pd.DataFrame(confusion_matrix, index=class_names, columns=class_names).astype(int)
heatmap = sns.heatmap(df_cm, annot=True, fmt="d")
heatmap.yaxis.set_ticklabels(heatmap.yaxis.get_ticklabels(), rotation=0, ha='right',fontsize=15)
heatmap.xaxis.set_ticklabels(heatmap.xaxis.get_ticklabels(), rotation=45, ha='right',fontsize=15)
plt.ylabel('True label')
plt.xlabel('Predicted label')
;
Другой простой способ получить точность - использовать sklearns "precision_score". Вот пример:
from sklearn.metrics import accuracy_score
y_pred = y_pred.data.numpy()
accuracy = accuracy_score(labels, np.argmax(y_pred, axis=1))
Сначала вам нужно получить данные из переменной. "y_pred" - это предсказания вашей модели, а метки - это, конечно, ваши метки.
np.argmax возвращает индекс наибольшего значения внутри массива. Мы хотим получить наибольшее значение, так как оно соответствует классу наибольшей вероятности при использовании softmax для мультиклассовой классификации. Оценка точности вернет процент совпадений между метками и y_pred.
Я использовал следующее, чтобы преобразовать тензоры факела в int, определяющий предсказанный класс.
x = [torch.max(tensor).item() for tensor in x_data]
y = [torch.max(tensor).item() for tensor in y_data]
надеюсь, это поможет! я все еще нуб, так что будьте нежны...