Эффективно выполнять регрессионный анализ нескольких подмножеств столбцов панд
Я мог бы выбрать более короткий вопрос, который фокусируется только на основной проблеме здесь, а именно на перестановках списков. Но причина, по которой я привожу статистические модели и панды в вопрос, заключается в том, что могут существовать специальные инструменты для пошаговой регрессии, которые в то же время обладают гибкостью для сохранения желаемого результата регрессии, как я собираюсь показать вам ниже, но это гораздо эффективнее. По крайней мере, я на это надеюсь.
Учитывая данные, как показано ниже:
Фрагмент кода 1:
# Imports
import pandas as pd
import numpy as np
import itertools
import statsmodels.api as sm
# A datafrane with random numbers
np.random.seed(123)
rows = 12
listVars= ['y','x1', 'x2', 'x3']
rng = pd.date_range('1/1/2017', periods=rows, freq='D')
df_1 = pd.DataFrame(np.random.randint(100,150,size=(rows, len(listVars))), columns=listVars)
df_1 = df_1.set_index(rng)
print(df_1)
Снимок экрана 1:

Я хотел бы запустить несколько регрессионных анализов для зависимой переменной y, используя несколько комбинаций независимых переменных x1, x2 и x3. Другими словами, это пошаговый регрессионный анализ, где y проверяется по x1, а затем x2 и x3 последовательно. Затем y проверяется на соответствие x1 и x2, и так далее:
- ['y', ['x1']]
- ['y', ['x2']]
- ['y', ['x3']]
- ['y', ['x1', 'x2']]
- ['y', ['x1', 'x2', 'x3']]
Мой неэффективный подход:
В двух первых фрагментах, приведенных ниже, я могу сделать именно это путем жесткого кодирования последовательности выполнения с использованием списка списков.
Вот подмножества listVars:
Фрагмент кода 2:
listExec = [[listVars[0], listVars[1:2]],
[listVars[0], listVars[2:3]],
[listVars[0], listVars[3:4]],
[listVars[0], listVars[1:3]],
[listVars[0], listVars[1:4]]]
for l in listExec:
print(l)
Снимок экрана 2:

С помощью listExec я могу настроить процедуру регрессионного анализа и сохранить несколько результатов (rsquared или всю модель вывода mode.summary()) в виде списка:
Фрагмент кода 3:
allResults = []
for l in listExec:
x = listVars[1]
x = sm.add_constant(df_1[l[1]])
model = sm.OLS(df_1[l[0]], x).fit()
result = model.rsquared
allResults.append(result)
печать (allResults)
Снимок экрана 3:
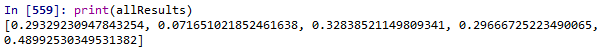
И это довольно круто, но ужасно неэффективно для длинных списков переменных.
Моя попытка составления списка:
Следуя советам из Как создать все перестановки списка в Python и Преобразовать список кортежей в список списков, я могу установить комбинацию ВСЕХ переменных, как это:
Фрагмент кода 4:
allTuples = list(itertools.permutations(listVars))
allCombos = [list(elem) for elem in allTuples]
Снимок экрана 4:
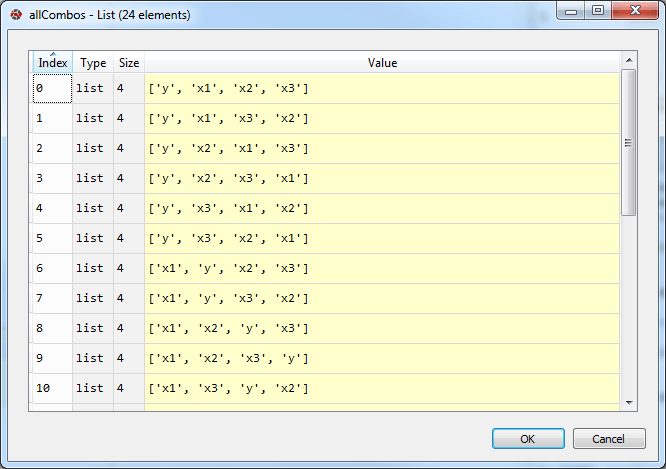
И это очень весело, но не дает мне поэтапного подхода, к которому я стремлюсь. В любом случае, я надеюсь, что некоторые из вас найдут это интересным.
Спасибо за любые предложения!
1 ответ
Основываясь на помощи, которую я получил, я смог собрать функцию, которая собирает все столбцы в фрейме данных pandas, определяет зависимую переменную и возвращает все уникальные комбинации оставшихся переменных. Результат немного отличается от желаемого результата, как определено выше, но, я думаю, имеет больше смысла для практического использования. Я все еще надеюсь, что другие смогут публиковать еще лучшие решения.
Вот:
# Imports
import pandas as pd
import numpy as np
import itertools
# A datafrane with random numbers
np.random.seed(123)
rows = 12
listVars= ['y','x1', 'x2', 'x3']
rng = pd.date_range('1/1/2017', periods=rows, freq='D')
df_1 = pd.DataFrame(np.random.randint(100,150,size=(rows, len(listVars))), columns=listVars)
df_1 = df_1.set_index(rng)
# The function
def StepWise(columns, dependent):
""" Takes the columns of a pandas dataframe, defines a dependent variable
and returns all unique combinations of the remaining (independent) variables.
"""
independent = columns.copy()
independent.remove(dependent)
lst1 = []
lst2 = []
for i in np.arange(1, len(independent)+1):
#print(list(itertools.combinations(independent, i)))
elem = list(itertools.combinations(independent, i))
lst1.append(elem)
lst2.extend(elem)
combosIndependent = [list(elem) for elem in lst2]
combosAll = [[dependent, other] for other in combosIndependent]
return(combosAll)
lExec = StepWise(columns = list(df_1), dependent = 'y')
print(lExec)
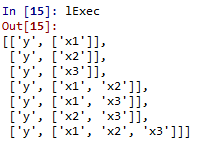
Если вы объедините это с фрагментом 3 выше, вы можете легко сохранить результаты множественного регрессионного анализа для указанной зависимой переменной во фрейме данных pandas.