Удаление ненужного MS Office из текстовой строки
У меня есть строка, которая содержит кучу мусора MS Word, как это:
<!--[if gte mso 9]><xml>
<o:OfficeDocumentSettings>
</xml><![endif]--><!--[if gte mso 9]><xml>
<w:WordDocument>
<w:View>Normal</w:View>
<m:mathPr>
<m:mathFont m:val="Cambria Math"/>
<m:brkBin m:val="before"/>
</m:mathPr></w:WordDocument>
</xml><![endif]--><!--[if gte mso 9]>
<style>
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;}
</style>
<![endif]-->
Я попробовал функцию ниже, чтобы удалить его, но они только удаляют части и оставляют тонну пустого пространства:
Public Function CleanOfficeJunk(html As String) As String
' start by completely removing all unwanted tags
html = System.Text.RegularExpressions.Regex.Replace(html, "<[/]?(font|span|xml|del|ins|[ovwxp]:\w+)[^>]*?>", "", System.Text.RegularExpressions.RegexOptions.IgnoreCase)
' then run another pass over the html (twice), removing unwanted attributes
html = System.Text.RegularExpressions.Regex.Replace(html, "<([^>]*)(?:class|lang|style|size|face|[ovwxp]:\w+)=(?:'[^']*'|""[^""]*""|[^\s>]+)([^>]*)>", "<$1$2>", System.Text.RegularExpressions.RegexOptions.IgnoreCase)
html = System.Text.RegularExpressions.Regex.Replace(html, "<([^>]*)(?:class|lang|style|size|face|[ovwxp]:\w+)=(?:'[^']*'|""[^""]*""|[^\s>]+)([^>]*)>", "<$1$2>", System.Text.RegularExpressions.RegexOptions.IgnoreCase)
Return html
End Function
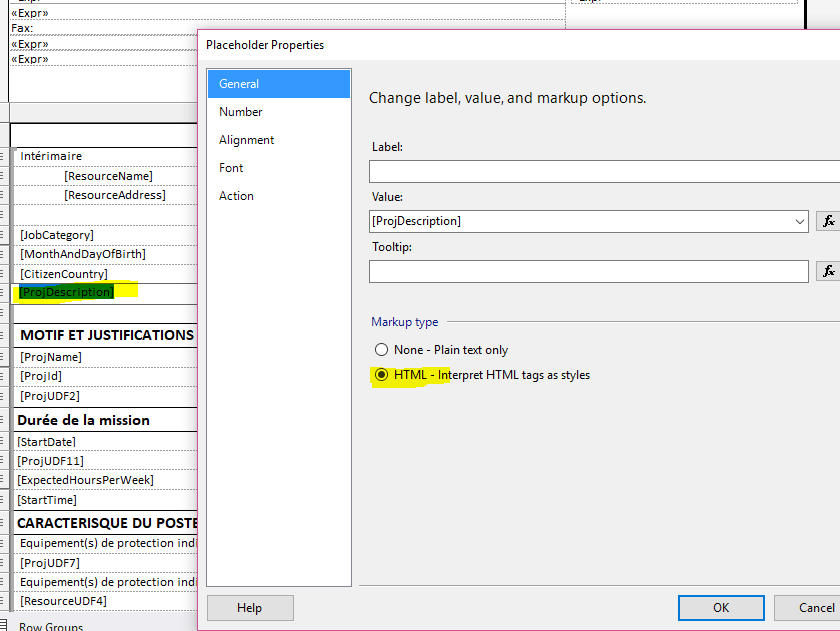
Я использую это в отчете службы отчетов SQL Server (SSRS), и мне нужно очистить строки перед тем, как отобразить их в текстовом поле.
Есть ли лучший способ удаления подобных вещей?
редактировать: я видел этот пост Удалить комментарии HTML с помощью Regex, в Javascript
Но принятый ответ не работал в моей ситуации.
1 ответ
Вы должны попробовать установить свойство PlaceHolder в HTML. Это решило мою проблему.