Удалить комментарии HTML с помощью Regex, в Javascript
У меня есть некрасивый HTML, сгенерированный из Word, из которого я хочу удалить все комментарии HTML.
HTML выглядит так:
<!--[if gte mso 9]><xml> <o:OfficeDocumentSettings> <o:RelyOnVML/> <o:AllowPNG/> </o:OfficeDocumentSettings> </xml><![endif]--><!--[if gte mso 9]><xml> <w:WordDocument> <w:View>Normal</w:View> <w:Zoom>0</w:Zoom> <w:TrackMoves/> <w:TrackFormatting/> <w:HyphenationZone>21</w:HyphenationZone> <w:PunctuationKerning/> <w:ValidateAgainstSchemas/> <w:SaveIfXMLInvalid>false</w:SaveIfXMLInvalid> <w:IgnoreMixedContent>false</w:IgnoreMixedContent> <w:AlwaysShowPlaceholderText>false</w:AlwaysShowPlaceholderText> <w:DoNotPromoteQF/> <w:LidThemeOther>NO-BOK</w:LidThemeOther> <w:LidThemeAsian>X-NONE</w:LidThemeAsian> <w:LidThemeComplexScript>X-NONE</w:LidThemeComplexScript> <w:Compatibility> <w:BreakWrappedTables/> <w:SnapToGridInCell/> <w:WrapTextWithPunct/> <w:UseAsianBreakRules/> <w:DontGrowAutofit/> <w:SplitPgBreakAndParaMark/> <w:EnableOpenTypeKerning/> <w:DontFlipMirrorIndents/> <w:OverrideTableStyleHps/> </w:Compatibility> <m:mathPr> <m:mathFont m:val="Cambria Math"/> <m:brkBin m:val="before"/> <m:brkBinSub m:val="--"/> <m:smallFrac m:val="off"/> <m:dispDef/> <m:lMargin m:val="0"/> <m:rMargin m:val="0"/> <m:defJc m:val="centerGroup"/> <m:wrapIndent m:val="1440"/> <m:intLim m:val="subSup"/> <m:naryLim m:val="undOvr"/> </m:mathPr></w:WordDocument> </xml><![endif]-->
... и регулярное выражение, которое я использую это
html = html.replace(/<!--(.*?)-->/gm, "")
Но, похоже, совпадения нет, строка неизменна.
Чего мне не хватает?
4 ответа
Регулярное выражение /<!--[\s\S]*?-->/g должно сработать.
Вы собираетесь уничтожить экранированные текстовые блоки в блоках CDATA.
Например
<script><!-- notACommentHere() --></script>
и буквальный текст в отформатированных кодовых блоках
<xmp>I'm demoing HTML <!-- comments --></xmp>
<textarea><!-- Not a comment either --></textarea>
РЕДАКТИРОВАТЬ:
Это также не помешает появлению новых комментариев, как в
<!-<!-- A comment -->- not comment text -->
который после одного раунда этого регулярного выражения станет
<!-- not comment text -->
Если это проблема, вы можете сбежать < которые не являются частью комментария или тега (сложно понять правильно) или вы можете зацикливаться и заменять, как указано выше, пока строка не уляжется.
Вот регулярное выражение, которое будет соответствовать комментариям, включая псевдо-комментарии и незакрытые комментарии согласно спецификации HTML-5. Раздел CDATA строго разрешен только в иностранном XML. Это переносит те же предостережения, что и выше.
var COMMENT_PSEUDO_COMMENT_OR_LT_BANG = new RegExp(
'<!--[\\s\\S]*?(?:-->)?'
+ '<!---+>?' // A comment with no body
+ '|<!(?![dD][oO][cC][tT][yY][pP][eE]|\\[CDATA\\[)[^>]*>?'
+ '|<[?][^>]*>?', // A pseudo-comment
'g');
Это основано на ответе Ауриэль Перлманн, он поддерживает все случаи (однострочные, многострочные, незавершенные и вложенные комментарии):
/(<!--.*?-->)|(<!--[\S\s]+?-->)|(<!--[\S\s]*?$)/g
https://regex101.com/r/az8Lu6/1
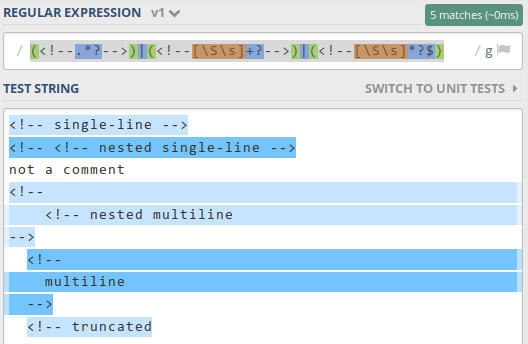
Это работает также для мультилинии - (<!--.*?-->)|(<!--[\w\W\n\s]+?-->)

Вы должны использовать /s модификатор
html = html.replace (/<!--.*?-->/sg, "")
Протестировано в Perl:
use strict;
use warnings;
my $str = 'hello <!--[if gte mso 9]><xml> <o:OfficeDocumentSettings> <o:RelyOnVML/> <o:AllowPNG/> </o:OfficeDocumentSettings> </xml><![endif]--><!--[if gte mso 9]><xml> <w:WordDocument> <w:View>Normal</w:View> <w:Zoom>0</w:Zoom> <w:TrackMoves/> <w:TrackFormatting/> <w:HyphenationZone>21</w:HyphenationZone> <w:PunctuationKerning/> <w:ValidateAgainstSchemas/> <w:SaveIfXMLInvalid>false</w:SaveIfXMLInvalid> <w:IgnoreMixedContent>false</w:IgnoreMixedContent> <w:AlwaysShowPlaceholderText>false</w:AlwaysShowPlaceholderText> <w:DoNotPromoteQF/> <w:LidThemeOther>NO-BOK</w:LidThemeOther> <w:LidThemeAsian>X-NONE</w:LidThemeAsian> <w:LidThemeComplexScript>X-NONE</w:LidThemeComplexScript> <w:Compatibility> <w:BreakWrappedTables/> <w:SnapToGridInCell/> <w:WrapTextWithPunct/> <w:UseAsianBreakRules/> <w:DontGrowAutofit/> <w:SplitPgBreakAndParaMark/> <w:EnableOpenTypeKerning/> <w:DontFlipMirrorIndents/> <w:OverrideTableStyleHps/> </w:Compatibility> <m:mathPr> <m:mathFont m:val="Cambria Math"/> <m:brkBin m:val="before"/> <m:brkBinSub m:val="--"/> <m:smallFrac m:val="off"/> <m:dispDef/> <m:lMargin m:val="0"/> <m:rMargin m:val="0"/> <m:defJc m:val="centerGroup"/> <m:wrapIndent m:val="1440"/> <m:intLim m:val="subSup"/> <m:naryLim m:val="undOvr"/> </m:mathPr></w:WordDocument> </xml><![endif]-->world!';
$str =~ s/<!--.*?-->//sg;
print $str;
Выход:hello world!
Недавно мне нужно было сделать именно это (т.е. удалить все комментарии из файла HTML). Некоторые вещи, которые эти другие ответы не принимают во внимание;
- В html-файле могут быть встроенные css и JS, которые, ну, я хотел удалить хотя бы
- Синтаксис комментария внутри строки или регулярного выражения полностью допустим. (Мой шаблон исключения строк / регулярных выражений основан на: /questions/25587311/alternativa-regulyarnomu-vyirazheniyu-sopostavit-vse-ekzemplyaryi-ne-v-kavyichkah/25587331#25587331)
TL; DR: (мне просто нужно регулярное выражение, которое удаляет все комментарии, пожалуйста)
/\\\/|\/\s*(?:\\\/|[^\/\*\n])+\/|\\"|"(?:\\"|[^"])*"|\\'|'(?:\\'|[^'])*'|\\`|`(?:\\`|[^`])*`|(\/\/[\s\S]*?$|(?:<!--|\/\s*\*)\s*[\s\S]*?\s*(?:-->|\*\s*\/))/gm
А вот простая демонстрация: https://www.regexr.com/5fjlu
Я не ненавижу читать, покажите мне остальное:
Мне также нужно было выполнить различные другие сопоставления, которые учитывали допустимые строки, содержащие вещи, которые в противном случае выглядят как допустимые цели. Итак, я создал класс для разнообразных применений.
class StringAwareRegExp extends RegExp {
static get [Symbol.species]() { return RegExp; }
constructor(regex, flags){
if(regex instanceof RegExp) regex = StringAwareRegExp.prototype.regExpToInnerRegexString(regex);
regex = super(`${StringAwareRegExp.prototype.disqualifyStringsRegExp}(${regex})`, flags);
return regex;
}
stringReplace(sourceString, replaceString = ''){
return sourceString.replace(this, (match, group1) => { return group1 === undefined ? match : replaceString; });
}
}
StringAwareRegExp.prototype.regExpToInnerRegexString = function(regExp){ return regExp.toString().replace(/^\/|\/[gimsuy]*$/g, ''); };
Object.defineProperty(StringAwareRegExp.prototype, 'disqualifyStringsRegExp', {
get: function(){
return StringAwareRegExp.prototype.regExpToInnerRegexString(/\\\/|\/\s*(?:\\\/|[^\/\*\n])+\/|\\"|"(?:\\"|[^"])*"|\\'|'(?:\\'|[^'])*'|\\`|`(?:\\`|[^`])*`|/);
}
});
Исходя из этого, я создал еще два класса, чтобы отточить 2 основных типа совпадений, которые мне нужны:
class CommentRegExp extends StringAwareRegExp {
constructor(regex, flags){
if(regex instanceof RegExp) regex = StringAwareRegExp.prototype.regExpToInnerRegexString(regex);
return super(`\\/\\/${regex}$|(?:<!--|\\/\\s*\\*)\\s*${regex}\\s*(?:-->|\\*\\s*\\/)`, flags);
}
}
class StatementRegExp extends StringAwareRegExp {
constructor(regex, flags){
if(regex instanceof RegExp) regex = StringAwareRegExp.prototype.regExpToInnerRegexString(regex);
return super(`${regex}\\s*;?\\s*?`, flags);
}
}
И, наконец (какой бы полезной оно ни было), регулярное выражение, созданное из этого:
const allCommentsRegex = new CommentRegExp(/[\s\S]*?/, 'gm');
const enableBabelRegex = new CommentRegExp(/enable-?_?\s?babel/, 'gmi');
const disableBabelRegex = new CommentRegExp(/disable-?_?\s?babel/, 'gmi');
const includeRegex = new CommentRegExp(/\s*(?:includes?|imports?|requires?)\s+(.+?)/, 'gm');
const importRegex = new StatementRegExp(/import\s+(?:(?:\w+|{(?:\s*\w\s*,?\s*)+})\s+from)?\s*['"`](.+?)['"`]/, 'gm');
const requireRegex = new StatementRegExp(/(?:var|let|const)\s+(?:(?:\w+|{(?:\s*\w\s*,?\s*)+}))\s*=\s*require\s*\(\s*['"`](.+?)['"`]\s*\)/, 'gm');
const atImportRegex = new StatementRegExp(/@import\s*['"`](.+?)['"`]/, 'gm');
И, наконец, если кто-то хочет увидеть его в использовании. Вот проект, в котором я его использовал (.. Мои личные проекты всегда WIP..): https://github.com/fatlard1993/page-compiler
const regex = /<!--(.*?)-->/gm;
const str = `You will be able to see this text. <!-- You will not be able to see this text. --> You can even comment out things in <!-- the middle of --> a sentence. <!-- Or you can comment out a large number of lines. --> <div class="example-class"> <!-- Another --> thing you can do is put comments after closing tags, to help you find where a particular element ends. <br> (This can be helpful if you have a lot of nested elements.) </div> <!-- /.example-class -->`;
const subst = ``;
// The substituted value will be contained in the result variable
const result = str.replace(regex, subst);
console.log('Substitution result: ', result);html = html.replace("(?s)<!--\\[if(.*?)\\[endif\\] *-->", "")