Как найти високосный год программно в C
Я создал программу, используя C, чтобы определить, является ли введенный год високосным или нет. Но, к сожалению, это не работает хорошо. В нем говорится, что год является високосным, а предыдущий год не является високосным.
#include<stdio.h>
#include<conio.h>
int yearr(int year);
void main(void)
{
int year;
printf("Enter a year:");
scanf("%d",&year);
if(!yearr(year))
{
printf("It is a leap year.");
}
else
{
printf("It is not a leap year");
}
getch();
}
int yearr(int year)
{
if((year%4==0)&&(year/4!=0))
return 1;
else
return 0;
}
Прочитав комментарии, я отредактировал кодировку следующим образом:
#include<stdio.h>
#include<conio.h>
int yearr(int year);
void main(void)
{
int year;
printf("Enter a year:");
scanf("%d",&year);
if(!yearr(year))
{
printf("It is a leap year.");
}
else
{
printf("It is not a leap year");
}
getch();
}
int yearr(int year)
{
if((year%4==0)
{
if(year%400==0)
return 1;
if(year%100==0)
return 0;
}
else
return 0;
}
15 ответов
Ваша логика определения високосного года неверна. Это должно начать вас (из Википедии):
if year modulo 400 is 0
then is_leap_year
else if year modulo 100 is 0
then not_leap_year
else if year modulo 4 is 0
then is_leap_year
else
not_leap_year
x modulo y означает остаток x деленное на y, Например, 12 по модулю 5 равно 2.
Наиболее эффективный тест високосного года:
if ((year & 3) == 0 && ((year % 25) != 0 || (year & 15) == 0))
{
/* leap year */
}
Этот код действителен в C, C++, C#, Java и многих других C-подобных языках. В коде используется одно выражение TRUE/FALSE, которое состоит из трех отдельных тестов:
- 4-й год теста:
year & 3 - 100-й год теста:
year % 25 - 400-й год теста:
year & 15
Полное обсуждение того, как работает этот код, приведено ниже, но сначала необходимо обсудить алгоритм Википедии:
Алгоритм Википедии НЕ УКАЗАН / НЕОБХОДИМО
Википедия опубликовала алгоритм псевдокода (см.: Википедия: високосный год - алгоритм), который подвергался постоянному редактированию, мнению и вандализму.
НЕ ИСПОЛЬЗУЙТЕ АЛГОРИТМ ВИКИПЕДИИ!
Один из самых старых (и неэффективных) алгоритмов Википедии выглядит следующим образом:
if year modulo 400 is 0 then
is_leap_year
else if year modulo 100 is 0 then
not_leap_year
else if year modulo 4 is 0 then
is_leap_year
else
not_leap_year
Вышеприведенный алгоритм неэффективен, потому что он всегда выполняет тесты для 400-го и 100-го года, даже в те годы, которые быстро не пройдут "тест 4-го года" (тест по модулю 4), что составляет 75% времени! Переупорядочив алгоритм для выполнения теста 4-го года, мы значительно ускоряем процесс.
"НАИБОЛЕЕ ЭФФЕКТИВНЫЙ" АЛГОРИТМ ПСЕВДО-КОДА
Я предоставил википедию следующий алгоритм (более одного раза):
if year is not divisible by 4 then not leap year
else if year is not divisible by 100 then leap year
else if year is divisible by 400 then leap year
else not leap year
Этот "наиболее эффективный" псевдокод просто меняет порядок тестов, поэтому сначала выполняется деление на 4, а затем менее часто встречающиеся тесты. Поскольку "год" не делится на четыре 75% времени, алгоритм заканчивается после одного теста в трех из четырех случаев.
ПРИМЕЧАНИЕ: я боролся с различными редакторами Википедии, чтобы улучшить опубликованный там алгоритм, утверждая, что многие начинающие и профессиональные программисты быстро приходят на страницу Википедии (из-за списков лучших поисковых систем) и внедряют псевдокод Википедии без каких-либо дополнительных исследований. Редакторы Википедии отвергли и удалили все попытки, которые я предпринял, чтобы улучшить, комментировать или даже просто сносить опубликованный алгоритм. Очевидно, они считают, что поиск эффективности - это проблема программиста. Это может быть правдой, но многие программисты слишком спешат, чтобы провести тщательное исследование!
ОБСУЖДЕНИЕ "НАИБОЛЕЕ ЭФФЕКТИВНОГО" ЛИСТОВОГО ТЕСТА
Побитовое И вместо модуля:
Я заменил две операции по модулю в алгоритме Википедии на операции побитового И. Почему и как?
Выполнение вычисления по модулю требует деления. При программировании ПК часто не задумываются об этом, но при программировании 8-битных микроконтроллеров, встроенных в небольшие устройства, вы можете обнаружить, что функция деления не может быть выполнена процессором по умолчанию. В таких процессорах деление является трудным процессом, включающим в себя повторяющиеся циклы, сдвиг битов и операции сложения / вычитания, которые выполняются очень медленно. Это очень желательно избегать.
Оказывается, что по модулю степеней двух можно поочередно достичь с помощью операции побитового И (см.: Википедия: Операция по модулю - Проблемы производительности):
x% 2 ^ n == x & (2 ^ n - 1)
Многие оптимизирующие компиляторы преобразуют такие операции по модулю в побитовое И для вас, но менее продвинутые компиляторы для меньших и менее популярных процессоров могут этого не делать. Побитовое И - это отдельная инструкция на каждом процессоре.
Заменив modulo 4 а также modulo 400 тесты с & 3 а также & 15 (см. ниже: "Факторинг для уменьшения математики") мы можем гарантировать, что самый быстрый код получится без использования гораздо более медленной операции деления.
Не существует степени двойки, равной 100. Таким образом, мы вынуждены продолжать использовать операцию по модулю для теста 100-го года, однако 100 заменяется на 25 (см. Ниже).
Факторинг для упрощения математики:
Помимо использования побитового И для замены операций по модулю, вы можете отметить два дополнительных спора между алгоритмом Википедии и оптимизированным выражением:
modulo 100заменяетсяmodulo 25modulo 400заменяется& 15
100-й год теста использует modulo 25 вместо modulo 100, Мы можем сделать это, потому что коэффициент 100 равен 2 x 2 x 5 x 5. Поскольку тест 4-го года уже проверяет факторы 4, мы можем исключить этот коэффициент из 100, оставив 25. Эта оптимизация, вероятно, незначительна почти для каждой реализации ЦП (как 100, так и 25 вписываются в 8 бит).
400-й год теста использует & 15 что эквивалентно modulo 16, Опять же, мы можем сделать это, потому что 400 факторов до 2 x 2 x 2 x 2 x 5 x 5. Мы можем исключить фактор 25, который проверяется тестом 100-го года, оставляя 16. Мы не можем дополнительно уменьшить 16, потому что 8 фактор 200, поэтому устранение любых других факторов приведет к нежелательному положительному результату в течение 200-го года.
400-летняя оптимизация очень важна для 8-битных процессоров, во-первых, потому что она избегает деления; но, что более важно, потому что значение 400 - это 9-битное число, с которым гораздо сложнее работать в 8-битном процессоре.
Логические операторы И / ИЛИ короткого замыкания:
Последней и наиболее важной используемой оптимизацией являются логические операторы короткого замыкания И ('&&') и ИЛИ ('||') (см. Википедия: оценка короткого замыкания), которые реализованы в большинстве языков, подобных С, Операторы короткого замыкания названы так, потому что они не удосуживаются оценить выражение на правой стороне, если выражение на левой стороне, само по себе, определяет результат операции.
Например: если 2003 год, то year & 3 == 0 ложно Невозможно, чтобы тесты в правой части логического И могли сделать результат верным, поэтому ничего другого не оценивается.
При первом выполнении теста 4-го года, только тест 4-го года (простое побитовое И) оценивается три четверти (75 процентов) времени. Это значительно ускоряет выполнение программы, особенно потому, что позволяет избежать деления, необходимого для теста на 100-й год (операция по модулю 25).
ЗАМЕТКА О РАЗМЕЩЕНИИ РОДИТЕЛЕЙ
Один комментатор чувствовал, что в моем коде неуместно заключены круглые скобки, и предложил перегруппировать подвыражения вокруг логического оператора AND (вместо логического ИЛИ) следующим образом:
if (((year & 3) == 0 && (year % 25) != 0) || (year & 15) == 0) { /* LY */ }
Выше неверно. Логический оператор И имеет более высокий приоритет, чем логический ИЛИ, и будет оцениваться первым с новыми скобками или без них. Скобки вокруг логических аргументов AND не имеют никакого эффекта. Это может привести к полному исключению подгрупп:
if ((year & 3) == 0 && (year % 25) != 0 || (year & 15) == 0) { /* LY */ }
Но в обоих вышеупомянутых случаях правая часть логического ИЛИ (критерий 400-го года) оценивается почти каждый раз (т. Е. Годы, не делимые на 4 и 100). Таким образом, полезная оптимизация была ошибочно исключена.
Скобки в моем исходном коде реализуют наиболее оптимизированное решение:
if ((year & 3) == 0 && ((year % 25) != 0 || (year & 15) == 0)) { /* LY */ }
Здесь логическое ИЛИ оценивается только по годам, кратным 4 (из-за короткого замыкания И). Правая часть логического ИЛИ оценивается только на годы, кратные 4 и 100 (из-за короткого замыкания ИЛИ).
ПРИМЕЧАНИЕ ДЛЯ ПРОГРАММИСТОВ C/C++
Программисты C/C++ могут счесть это выражение более оптимизированным:
if (!(year & 3) && ((year % 25) || !(year & 15))) { /* LY */ }
Это не более оптимизировано! Пока явное == 0 а также != 0 тесты удалены, они становятся неявными и все еще выполняются. Хуже того, код больше не действует в строго типизированных языках, таких как C#, где year & 3 оценивает int, но логическое И (&&), ИЛИ ЖЕ (||) и не (!) операторы требуют bool аргументы.
Многие ответы говорят о производительности. Ни один не показывает никаких измерений. Хорошая цитата из документации gcc по __builtin_expect говорит это:
Как известно, программисты плохо умеют предсказывать, как на самом деле работают их программы.
В большинстве реализаций используется короткое замыкание && а также ||в качестве инструмента оптимизации и далее предписываем "правильный" порядок проверок делимости для "наилучшей" производительности. Стоит отметить, что короткое замыкание не обязательно является функцией оптимизации.
Согласитесь, некоторые проверки могут дать окончательный ответ (например, год не кратен 4) и сделать последующие тесты бесполезными. Кажется разумным немедленно вернуться к этому моменту, вместо того чтобы продолжать ненужные вычисления. С другой стороны, при раннем возврате появляются ветви, и это может снизить производительность. (См. Этот легендарный пост.) Очень трудно угадать компромисс между ошибочными предсказаниями ветвления и ненужными вычислениями. В самом деле, это зависит от оборудования, входных данных, точных инструкций сборки, выдаваемых компилятором (которые могут меняться от одной версии к другой) и т. Д.
В продолжении будут показаны измерения, полученные в http://quick-bench.com/. Во всех случаях мы измеряем время, затрачиваемое на проверку того, сохраняется ли каждое значение вstd::array<int, 65536>високосный год или нет. Значения псевдослучайны, равномерно распределены в интервале [-400, 399]. Точнее, они генерируются следующим кодом:
auto const years = [](){
std::uniform_int_distribution<int> uniform_dist(-400, 399);
std::mt19937 rng;
std::array<int, 65536> years;
for (auto& year : years)
year = uniform_dist(rng);
return years;
}();
Даже по возможности не заменяю % с & (например year & 3 == 0 вместо того year % 4 == 0). Я доверяю компилятору (GCC-9.2 at-O3) сделает это за меня. (Оно делает.)
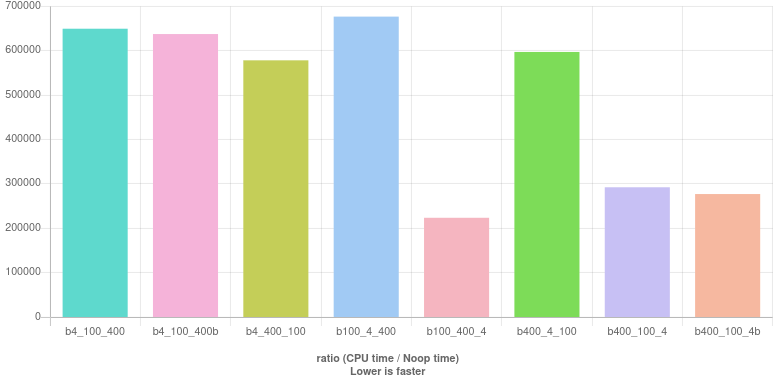
4-100-400 тестов
Проверки високосных лет обычно составляются с помощью трех тестов на делимость: year % 4 == 0, year % 100 != 0 а также year % 400 == 0. Ниже приводится список реализаций, охватывающий все возможные порядки, в которых могут появляться эти проверки. Каждая реализация снабжена соответствующей меткой. (Некоторые заказы допускают две разные реализации, и в этом случае второй получает суффиксb.) Они есть:
b4_100_400 : year % 4 == 0 && (year % 100 != 0 || year % 400 == 0)
b4_100_400b : (year % 4 == 0 && year % 100 != 0) || year % 400 == 0
b4_400_100 : year % 4 == 0 && (year % 400 == 0 || year % 100 != 0)
b100_4_400 : (year % 100 != 0 && year % 4 == 0) || year % 400 == 0
b100_400_4 : (year % 100 != 0 || year % 400 == 0) && year % 4 == 0
b400_4_100 : year % 400 == 0 || (year % 4 == 0 && year % 100 != 0)
b400_100_4 : year % 400 == 0 || (year % 100 != 0 && year % 4 == 0)
b400_100_4b : (year % 400 == 0 || year % 100 != 0) && year % 4 == 0
Результаты показаны ниже. (Смотрите их вживую.)
Вопреки тому, что многие советуют, проверка делимости на 4первое, похоже, не лучший вариант. Напротив, по крайней мере, в этих измерениях три первых бара входят в пятерку худших. Лучшее
b100_400_4 : (year % 100 != 0 || year % 400 == 0) && year % 4 == 0
4-25-16 тестов
Другой предоставленный совет (который, должен признаться, я считаю хорошим) - заменить year % 100 != 0 с year % 25 != 0. Это не влияет на корректность, так как мы также проверяемyear % 4 == 0. (Если число кратно4 то делимость на 100 эквивалентно делимости на 25.) По аналогии, year % 400 == 0 можно заменить на year % 16 == 0 из-за наличия проверки делимости на 25.
Как и в предыдущем разделе, у нас есть 8 реализаций, использующих проверки делимости 4-25-16:
b4_25_16 : year % 4 == 0 && (year % 25 != 0 || year % 16 == 0)
b4_25_16b : (year % 4 == 0 && year % 25 != 0) || year % 16 == 0
b4_16_25 : year % 4 == 0 && (year % 16 == 0 || year % 25 != 0)
b25_4_16 : (year % 25 != 0 && year % 4 == 0) || year % 16 == 0
b25_16_4 : (year % 25 != 0 || year % 16 == 0) && year % 4 == 0
b16_4_25 : year % 16 == 0 || (year % 4 == 0 && year % 25 != 0)
b16_25_4 : year % 16 == 0 || (year % 25 != 0 && year % 4 == 0)
b16_25_4b : (year % 16 == 0 || year % 25 != 0) && year % 4 == 0
Результаты ( здесь):
Опять же, проверяя делимость на 4сначала не выглядит хорошей идеей. В этом раунде пост
b25_16_4 : (year % 25 != 0 || year % 16 == 0) && year % 4 == 0
4-100-400 тестов (без ветвления)
Как упоминалось ранее, ветвление может снизить производительность. В частности, короткое замыкание может быть контрпродуктивным. В этом случае классический трюк заменяет логические операторы&& а также || со своими побитовыми аналогами & а также |. Реализации становятся:
nb4_100_400 : (year % 4 == 0) & ((year % 100 != 0) | (year % 400 == 0))
nb4_100_400b : ((year % 4 == 0) & (year % 100 != 0)) | (year % 400 == 0)
nb4_400_100 : (year % 4 == 0) & ((year % 400 == 0) | (year % 100 != 0))
nb100_4_400 : ((year % 100 != 0) & (year % 4 == 0)) | (year % 400 == 0)
nb100_400_4 : ((year % 100 != 0) | (year % 400 == 0)) & (year % 4 == 0)
nb400_4_100 : (year % 400 == 0) | ((year % 4 == 0) & (year % 100 != 0))
nb400_100_4 : (year % 400 == 0) | ((year % 100 != 0) & (year % 4 == 0))
nb400_100_4b : ((year % 400 == 0) | (year % 100 != 0)) & (year % 4 == 0)
Результаты ( здесь):
Примечательной особенностью является то, что изменение производительности не так ярко выражено, как в случае ветвления, и затрудняет определение победителя. Выбираем это:
nb100_400_4 : ((year % 100 != 0) | (year % 400 == 0)) & (year % 4 == 0)
4-25-16 тестов (без ветвления)
В завершение упражнения рассмотрим случай отсутствия ветвления с тестами на делимость 4-25-16:
nb4_25_16 : (year % 4 == 0) & ((year % 25 != 0) | (year % 16 == 0))
nb4_25_16b : ((year % 4 == 0) & (year % 25 != 0)) | (year % 16 == 0)
nb4_16_25 : (year % 4 == 0) & ((year % 16 == 0) | (year % 25 != 0))
nb25_4_16 : ((year % 25 != 0) & (year % 4 == 0)) | (year % 16 == 0)
nb25_16_4 : ((year % 25 != 0) | (year % 16 == 0)) & (year % 4 == 0)
nb16_4_25 : (year % 16 == 0) | ((year % 4 == 0) & (year % 25 != 0))
nb16_25_4 : (year % 16 == 0) | ((year % 25 != 0) & (year % 4 == 0))
nb16_25_4b : ((year % 16 == 0) | (year % 25 != 0)) & (year % 4 == 0)
Результаты ( здесь):
Опять же, сложно определить лучших, и мы выбираем вот этого:
nb25_16_4 : ((year % 25 != 0) | (year % 16 == 0)) & (year % 4 == 0)
Лига чемпионов
Пришло время выбрать лучшее из каждого предыдущего раздела и сравнить их:
b100_400_4 : (year % 100 != 0 || year % 400 == 0) && year % 4 == 0
b25_16_4 : (year % 25 != 0 || year % 16 == 0) && year % 4 == 0
nb100_400_4 : ((year % 100 != 0) | (year % 400 == 0)) & (year % 4 == 0)
nb25_16_4 : ((year % 25 != 0) | (year % 16 == 0)) & (year % 4 == 0)
Результаты ( здесь):
Эта диаграмма предполагает, что короткое замыкание действительно является оптимизацией, но делится на 4должна проверяться последней, а не первой. Для лучшей производительности следует проверить делимость на100первый. Это довольно удивительно! В конце концов, последнего теста никогда не бывает достаточно, чтобы решить, високосный год или нет, и последующего теста (либо400 или по 4) всегда требуется.
Также удивительно то, что для версий ветвления, использующих более простые делители 25 а также 16 не лучше, чем использование более интуитивно понятного 100 а также 400. Я могу предложить свою "теорию", которая также частично объясняет, почему тестирование100 сначала лучше, чем тестирование 4. Как отмечали многие, проверка делимости на4 разбивает выполнение на (25%, 75%) частей, тогда как тест на 100разбивает его на (1%, 99%). Не имеет значения, что после последней проверки выполнение должно перейти к другому тесту, потому что, по крайней мере, предсказатель ветвления с большей вероятностью правильно угадывает, в какой путь двигаться. Точно так же проверка делимости на25разбивает выполнение на (4%, 96%), что является более сложной задачей для предсказателя ветвления, чем (1%, 99%). Похоже, что лучше минимизировать энтропию распределения, помогая предсказателю ветвления, чем максимизировать вероятность досрочного возврата.
Для версий без ветвления упрощенные делители обеспечивают лучшую производительность. В этом случае предсказатель ветвления не играет никакой роли и, следовательно, чем проще, тем лучше. Как правило, компилятор может выполнять лучшую оптимизацию с меньшими числами.
Это все?
Мы ударились о стену и узнали, что
b100_400_4 : (year % 100 != 0 || year % 400 == 0) && year % 4 == 0
самая эффективная проверка для високосных лет? Точно нет. Например, у нас нет смешанных операторов ветвления&& или || без ветвящихся & а также |. Возможно... Давайте посмотрим и сравним вышесказанное с двумя другими реализациями. Первый - это
m100_400_4 : (year % 100 != 0 || year % 400 == 0) & (year % 4 == 0)
(Обратите внимание на сочетание ветвления || и без ветвления & операторов.) Второй - непонятный "хак":
bool b;
auto n = 0xc28f5c29 * year;
auto m = n + 0x051eb850;
m = (m << 30 | m >> 2);
if (m <= 0x28f5c28)
b = n % 16 == 0;
else
b = n % 4 == 0;
return b
Последний работает? Да, это так. Вместо того, чтобы давать математическое доказательство, я предлагаю сравнить код, выданный для вышеупомянутого, с кодом для этого более читаемого источника:
bool b;
if (year % 100 == 0)
b = year % 16 == 0;
else
b = year % 4 == 0;
return b;
в обозревателе компилятора. Они почти идентичны, с той лишь разницей, что используетсяadd инструкция, когда другой использует lea. Это должно убедить вас в том, что код взлома работает (пока работает другой).
Результаты тестов ( здесь):
Подождите, я слышал, вы говорите, почему бы не использовать более читаемый код на картинке выше? Что ж, я попробовал и усвоил еще один урок. Когда этот код вставляется в цикл тестирования, компилятор смотрел на исходный код в целом и решил выдать другой код, чем когда он видит источник изолированно. Спектакль был хуже. Иди разберись!
И сейчас? Это все?
Я не знаю! Есть много вещей, которые мы могли бы изучить. В последнем разделе, например, была показана еще одна версия с использованиемifзаявление, скорее, что короткое замыкание. Это может быть способом повысить производительность. Мы также можем попробовать тернарный оператор?.
Имейте в виду, что все измерения и выводы были основаны на GCC-9.2. С другим компилятором и / или версией все может измениться. Например, GCC версии 9.1 представил новый улучшенный алгоритм проверки делимости. Следовательно, более старые версии имеют разные характеристики, и компромисс между ненужным вычислением и ошибочным предсказанием перехода, вероятно, изменился.
Мы можем однозначно сделать следующие выводы:
- Не задумывайтесь. Предпочитайте ясный код трудным для понимания оптимизациям. В конце концов, вручную созданный фрагмент кода может оказаться не самым эффективным вариантом при обновлении компилятора. Как сказал David Bowling в комментарии: "Нет смысла возиться с таким фрагментом кода, если только он не является узким местом производительности".
- Гадать сложно и лучше измерить.
- Измерять сложно, но лучше, чем гадать.
- Короткое замыкание / разветвление может быть полезно для производительности, но это зависит от многих вещей, в том числе от того, насколько код помогает предсказателю ветвления.
- Код, создаваемый для отдельного фрагмента, может отличаться, если он где-то встроен.
int isLeapYear(int year)
{
return (year % 400 == 0) || ( ( year % 100 != 0) && (year % 4 == 0 ));
}
Хотя логика, которая сначала делит на 400, безупречна, она не так эффективна в вычислительном отношении, как сначала деление на 4. Вы можете сделать это с помощью логики:
#define LEAPYEAR(y) ((y % 4) == 0 && ((y % 100) != 0 || (y % 400) == 0))
Это делит на 4 для каждого значения, но для 3/4 из них тестирование заканчивается там. Для 1/4, прошедшей первый тест, она делится на 100, исключая значения 24/25; для оставшихся 1 из 100 он тоже делится на 400 и дает окончательный ответ. Конечно, это не огромная экономия.
Это может быть правильным решением. Алгоритм, указанный в Википедии, неверен.
-(BOOL)isLeapYear: (int)year{
if(year%4==0){
if(year%100!=0){
return YES;
}
else if(year%400!=0){
return YES;
}
else return NO;
}
else return NO;
}
Из статьи Википедии о високосном году:
if (year modulo 4 is 0) and (year modulo 100 is not 0) or (year modulo 400 is 0)
then is_leap_year
else
not_leap_year
Проблема с вашим кодом в том, что вы возвращаете ненулевое значение из yearr если вы думаете, что это високосный год. Так что вам не нужно ! в вашем заявлении if.
http://www.wwu.edu/depts/skywise/leapyear.html
Правила високосного года
Каждый год существует високосный год, число которого делится на четыре, за исключением лет, которые делятся на 100 и не делятся на 400. Вторая часть правила влияет на вековые годы. Например; 1600 и 2000 годы являются високосными, а 1700, 1800 и 1900 годы - нет. Это означает, что три раза из каждых четырехсот лет есть восемь лет между високосными годами.
if(year%400 ==0 || (year%100 != 0 && year%4 == 0))
{
printf("Year %d is a leap year",year);
}
else
{
printf("Year %d is not a leap year",year);
}
Измените это как выше. Также прочитайте это.
I used this code:
#include <stdio.h>
int main()
{
int yr;
printf ("Enter a year \n");
scanf ("%d", &yr);
if (yr%400 == 0)
printf("\n LEAP YEAR.");
else if (yr%4==0 && yr%100!=0)
printf("\n LEAP YEAR.");
else
printf ("\n NOT LEAP YEAR.");
}
#включают
пустота главная (недействительная)
{
в год;
printf ("Введите год, чтобы проверить, является ли он високосным годом \ n");
зсапЕ ("%d",& год);
if (год%400==0) /* почему мод 400 * /
printf ("% d - високосный год \ n", год);
иначе если (год%100==0) /* Почему мод 100 * /
printf ("% d не является високосным годом \ n", год);
иначе, если (год%4==0)
printf("%d - високосный год \ n", год);
еще
printf ("% d не является високосным годом \ n", год);
}
Вот еще 2 решения, которые, кажется, превзошли предыдущие в тесте https://quick-bench.com/.
У этого есть тест, но он компилируется в безветвленный код с помощью clang:
int isleap3(int year) {
unsigned y = year + 16000;
return (y % 100) ? !(y % 4) : !(y % 16);
}
В нем используется одна операция по модулю и нет тестов, и он компилируется всего в 2 умножения:
static unsigned char const leaptest[400] = {
1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,
0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,
0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,
0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,
0,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,
0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,
0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,
0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,
0,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,
0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,
0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,
0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,
0,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,
0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,
0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,
0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,
};
int isleap4(int year) {
unsigned y = year + 16000;
return leaptest[y % 400];
}
isleap3: # @isleap3
add edi, 16000
imul eax, edi, -1030792151
ror eax, 2
cmp eax, 42949673
mov eax, 15
mov ecx, 3
cmovb ecx, eax
xor eax, eax
test ecx, edi
sete al
ret
isleap4: # @isleap4
add edi, 16000
imul rax, rdi, 1374389535
shr rax, 39
imul eax, eax, 400
sub edi, eax
movzx eax, byte ptr [rdi + leaptest]
ret
leaptest:
.asciz "\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\000\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\000\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\000\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000\000\001\000\000"
Вот результаты тестов:
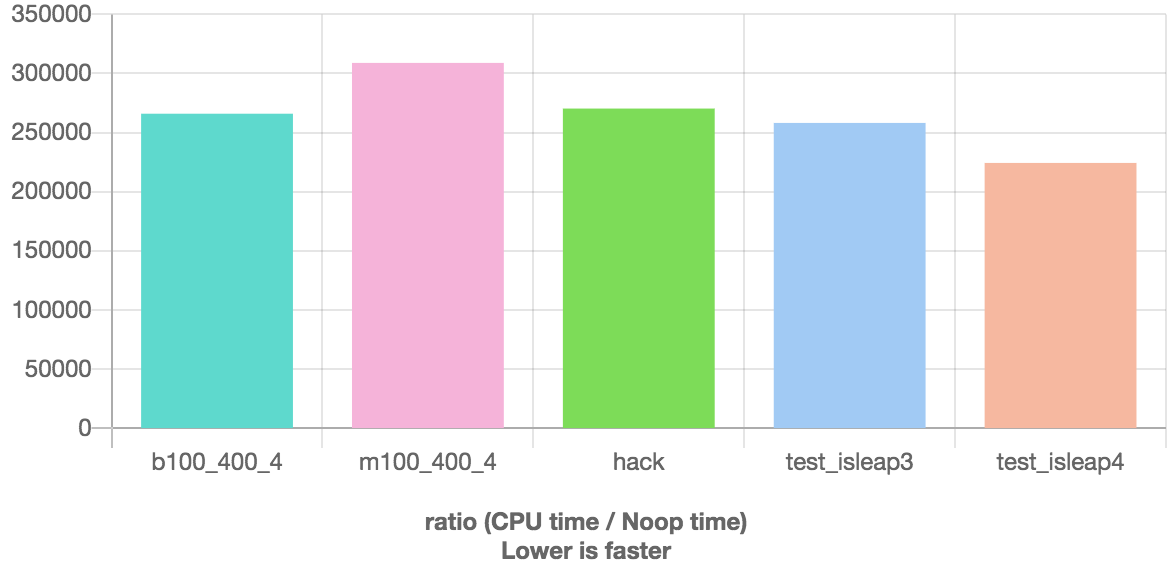
Как и другие уже упоминали условие для високосного года не является правильным. Должно:
int yearr(int year)
{
if(((year%4 == 0) && (year%100 !=0)) || (year%400==0))
return 1;
else
return 0;
}
Прочитайте здесь, как проверить високосный год в Си.
Ответ Кевина дает оптимальный 8-тестовый тест (с использованием XOR с использованием констант), но если вы ищете что-то более читабельное, попробуйте этот 9-тестовый тест.
year % 4 == 0 && !((year % 100 == 0) ^ (year % 400 == 0))
Таблица правды для (year % 100 == 0) ^ (year % 400 == 0)
(year % 100 == 0) ^ (year % 400 == 0)
100 doesnt divide year . F
only 100 divides year . T
100 and 400 divides year . F
Сейчас !(year % 100 == 0) ^ (year % 400 == 0) дает то, что вы хотите.
Рассчитать максимальный / последний день месяца: 1..12, год: 1..3999
maxDays = month == 2 ?
28 + ((year & 3) == 0 && ((year % 25) != 0 || (year & 15) == 0)) :
30 + ((month & 1) ^ (month > 7));
#define is_leap(A) !((A) & 3)
Просто убедитесь, что вы не вводите отрицательный год:)