Почему обрабатывать отсортированный массив быстрее, чем несортированный?
Вот фрагмент кода C++, который кажется очень своеобразным. По какой-то странной причине сортировка данных чудесным образом делает код почти в шесть раз быстрее.
#include <algorithm>
#include <ctime>
#include <iostream>
int main()
{
// Generate data
const unsigned arraySize = 32768;
int data[arraySize];
for (unsigned c = 0; c < arraySize; ++c)
data[c] = std::rand() % 256;
// !!! With this, the next loop runs faster
std::sort(data, data + arraySize);
// Test
clock_t start = clock();
long long sum = 0;
for (unsigned i = 0; i < 100000; ++i)
{
// Primary loop
for (unsigned c = 0; c < arraySize; ++c)
{
if (data[c] >= 128)
sum += data[c];
}
}
double elapsedTime = static_cast<double>(clock() - start) / CLOCKS_PER_SEC;
std::cout << elapsedTime << std::endl;
std::cout << "sum = " << sum << std::endl;
}
- Без
std::sort(data, data + arraySize);код выполняется за 11,54 секунды. - С отсортированными данными код запускается за 1,93 секунды.
Сначала я думал, что это может быть просто аномалия языка или компилятора. Поэтому я попробовал это на Java.
import java.util.Arrays;
import java.util.Random;
public class Main
{
public static void main(String[] args)
{
// Generate data
int arraySize = 32768;
int data[] = new int[arraySize];
Random rnd = new Random(0);
for (int c = 0; c < arraySize; ++c)
data[c] = rnd.nextInt() % 256;
// !!! With this, the next loop runs faster
Arrays.sort(data);
// Test
long start = System.nanoTime();
long sum = 0;
for (int i = 0; i < 100000; ++i)
{
// Primary loop
for (int c = 0; c < arraySize; ++c)
{
if (data[c] >= 128)
sum += data[c];
}
}
System.out.println((System.nanoTime() - start) / 1000000000.0);
System.out.println("sum = " + sum);
}
}
С несколько похожим, но менее экстремальным результатом.
Моей первой мыслью было, что сортировка переносит данные в кеш, но потом я подумал, насколько это глупо, потому что массив только что сгенерирован.
- Что здесь происходит?
- Почему обрабатывать отсортированный массив быстрее, чем несортированный?
- Код суммирует некоторые независимые термины, и порядок не должен иметь значения.
31 ответ
Вы являетесь жертвой неудачного предсказания ветвлений.
Что такое отраслевое прогнозирование?
Рассмотрим железнодорожный узел:
 Изображение Mecanismo, через Wikimedia Commons. Используется по лицензии CC-By-SA 3.0.
Изображение Mecanismo, через Wikimedia Commons. Используется по лицензии CC-By-SA 3.0.
Теперь, ради аргумента, предположим, что это еще в 1800-х годах - до дальней связи или радиосвязи.
Вы оператор развязки, и вы слышите прибытие поезда. Вы понятия не имеете, в какую сторону это должно идти. Вы останавливаете поезд, чтобы спросить водителя, в каком направлении они хотят. И тогда вы установите переключатель соответствующим образом.
Поезда тяжелые и имеют большую инерцию. Таким образом, они требуют вечности, чтобы начать и замедлить.
Есть ли способ лучше? Вы угадываете, в каком направлении будет идти поезд!
- Если вы угадали, это продолжается.
- Если вы догадались, капитан остановится, отступит и закричит на вас, чтобы щелкнуть выключателем. Затем он может перезапустить другой путь.
Если вы каждый раз угадаете, поезд никогда не остановится.
Если вы слишком часто угадываете неправильно, поезд будет тратить много времени на остановку, резервное копирование и перезапуск.
Рассмотрим оператор if: на уровне процессора это инструкция перехода:

Вы процессор, и вы видите ветку. Вы понятия не имеете, в какую сторону это пойдет. Чем ты занимаешься? Вы останавливаете выполнение и ждете, пока предыдущие инструкции не будут выполнены. Затем вы продолжаете идти по правильному пути.
Современные процессоры сложны и имеют длинные трубопроводы. Таким образом, им нужно вечно "разогреваться" и "замедляться".
Есть ли способ лучше? Вы угадываете, в каком направлении пойдет филиал!
- Если вы угадали, вы продолжаете выполнять.
- Если вы догадались, вам нужно промыть конвейер и откатиться до ответвления. Затем вы можете перезапустить по другому пути.
Если вы каждый раз угадаете, выполнение никогда не остановится.
Если вы слишком часто угадываете неправильно, вы тратите много времени на остановку, откат и перезапуск.
Это прогноз отрасли. Я признаю, что это не лучшая аналогия, так как поезд мог просто сигнализировать направление с флагом. Но в компьютерах процессор не знает, в каком направлении пойдет ветка, до последнего момента.
Итак, как бы вы стратегически предположили, чтобы минимизировать количество раз, когда поезд должен вернуться назад и пойти по другому пути? Вы смотрите на прошлую историю! Если поезд идет влево 99% времени, значит, вы уехали. Если это чередуется, то вы чередуете свои догадки. Если это происходит в одну сторону каждые 3 раза, вы догадаетесь, то же самое...
Другими словами, вы пытаетесь определить шаблон и следовать ему. Это более или менее то, как работают предсказатели ветвлений.
Большинство приложений имеют хорошо управляемые ветви. Таким образом, современные отраслевые предикторы обычно достигают>90% показателей успешности Но когда они сталкиваются с непредсказуемыми ветвями без распознаваемых шаблонов, предикторы ветвей практически бесполезны.
Дальнейшее чтение: статья "Ветка предиктора" в Википедии.
Как указывалось выше, виновником является следующее if-утверждение:
if (data[c] >= 128)
sum += data[c];
Обратите внимание, что данные равномерно распределены между 0 и 255. Когда данные отсортированы, примерно первая половина итераций не войдет в оператор if. После этого все они введут оператор if.
Это очень удобно для предиктора ветвления, поскольку ветвь последовательно идет в одном и том же направлении много раз. Даже простой насыщающий счетчик будет правильно предсказывать ветвь, за исключением нескольких итераций после переключения направления.
Быстрая визуализация:
T = branch taken
N = branch not taken
data[] = 0, 1, 2, 3, 4, ... 126, 127, 128, 129, 130, ... 250, 251, 252, ...
branch = N N N N N ... N N T T T ... T T T ...
= NNNNNNNNNNNN ... NNNNNNNTTTTTTTTT ... TTTTTTTTTT (easy to predict)
Однако, когда данные являются полностью случайными, предиктор ветвления становится бесполезным, потому что он не может предсказать случайные данные. Таким образом, вероятно, будет около 50% неправильного прогноза. (не лучше, чем случайные догадки)
data[] = 226, 185, 125, 158, 198, 144, 217, 79, 202, 118, 14, 150, 177, 182, 133, ...
branch = T, T, N, T, T, T, T, N, T, N, N, T, T, T, N ...
= TTNTTTTNTNNTTTN ... (completely random - hard to predict)
Так что можно сделать?
Если компилятор не может оптимизировать переход в условный ход, вы можете попробовать некоторые методы, если вы готовы пожертвовать удобочитаемостью для производительности.
Заменить:
if (data[c] >= 128)
sum += data[c];
с:
int t = (data[c] - 128) >> 31;
sum += ~t & data[c];
Это исключает ветвление и заменяет его на некоторые побитовые операции.
(Обратите внимание, что этот хак не является строго эквивалентным исходному оператору if. Но в этом случае он действителен для всех входных значений data[] .)
Тесты: Core i7 920 @ 3,5 ГГц
C++ - Visual Studio 2010 - выпуск x64
// Branch - Random
seconds = 11.777
// Branch - Sorted
seconds = 2.352
// Branchless - Random
seconds = 2.564
// Branchless - Sorted
seconds = 2.587
Java - NetBeans 7.1.1 JDK 7 - x64
// Branch - Random
seconds = 10.93293813
// Branch - Sorted
seconds = 5.643797077
// Branchless - Random
seconds = 3.113581453
// Branchless - Sorted
seconds = 3.186068823
Замечания:
- С Ветвью: есть огромная разница между отсортированными и несортированными данными.
- С помощью Hack: нет никакой разницы между отсортированными и несортированными данными.
- В случае с C++ хак на самом деле медленнее, чем с веткой, когда данные сортируются.
Общее правило заключается в том, чтобы избежать зависящих от данных ветвлений в критических циклах. (например, в этом примере)
Обновить:
GCC 4.6.1 с
-O3или же-ftree-vectorizeна х64 умеет генерировать условный ход. Таким образом, нет никакой разницы между отсортированными и несортированными данными - оба быстры.VC++ 2010 не может генерировать условные ходы для этой ветви даже при
/Ox,Intel Compiler 11 делает что-то чудесное. Он чередует две петли, тем самым поднимая непредсказуемую ветвь на внешнюю петлю. Таким образом, он не только защищен от неправильных прогнозов, но также в два раза быстрее, чем то, что могут генерировать VC++ и GCC! Другими словами, ICC воспользовался тестовым циклом, чтобы победить тест...
Если вы дадите компилятору Intel код без ответвлений, он будет просто векторизовать его... и так же быстро, как и с ветвью (с обменом циклами).
Это говорит о том, что даже зрелые современные компиляторы могут сильно различаться по своей способности оптимизировать код...
Отраслевой прогноз.
С отсортированным массивом, условие data[c] >= 128 первый false для ряда ценностей, то становится true для всех последующих значений. Это легко предсказать. С несортированным массивом вы платите за стоимость ветвления.
Причина, по которой производительность резко улучшается при сортировке данных, заключается в том, что штраф за предсказание ветвлений удален, как прекрасно объяснено в Mysticial.
Теперь, если мы посмотрим на код
if (data[c] >= 128)
sum += data[c];
мы можем обнаружить, что значение этого конкретного if... else... Ветвь должна добавить что-то, когда условие выполнено. Этот тип ветви может быть легко преобразован в оператор условного перемещения, который будет скомпилирован в инструкцию условного перемещения: cmovl в x86 система. Ветвление и, следовательно, потенциальное наказание за предсказание ветвления удаляются
В C таким образом C++ оператор, который будет напрямую (без какой-либо оптимизации) компилироваться в инструкцию условного перемещения в x86 является троичным оператором ... ? ... : ..., Поэтому мы переписываем приведенное выше утверждение в эквивалентное:
sum += data[c] >=128 ? data[c] : 0;
Поддерживая читабельность, мы можем проверить коэффициент ускорения.
Для Intel Core i7 -2600K с частотой 3,4 ГГц и режима выпуска Visual Studio 2010 эталонным тестом является (формат, скопированный из Mysticial):
x86
// Branch - Random
seconds = 8.885
// Branch - Sorted
seconds = 1.528
// Branchless - Random
seconds = 3.716
// Branchless - Sorted
seconds = 3.71
x64
// Branch - Random
seconds = 11.302
// Branch - Sorted
seconds = 1.830
// Branchless - Random
seconds = 2.736
// Branchless - Sorted
seconds = 2.737
Результат надежен в нескольких тестах. Мы получаем значительное ускорение, когда результат ветвления непредсказуем, но мы немного страдаем, когда он предсказуем. Фактически, при использовании условного перемещения производительность остается одинаковой независимо от шаблона данных.
Теперь давайте посмотрим более внимательно, исследуя x86 сборки они генерируют. Для простоты мы используем две функции max1 а также max2,
max1 использует условную ветку if... else ...:
int max1(int a, int b) {
if (a > b)
return a;
else
return b;
}
max2 использует троичный оператор ... ? ... : ...:
int max2(int a, int b) {
return a > b ? a : b;
}
На машине x86-64, GCC -S генерирует сборку ниже.
:max1
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl -4(%rbp), %eax
cmpl -8(%rbp), %eax
jle .L2
movl -4(%rbp), %eax
movl %eax, -12(%rbp)
jmp .L4
.L2:
movl -8(%rbp), %eax
movl %eax, -12(%rbp)
.L4:
movl -12(%rbp), %eax
leave
ret
:max2
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl -4(%rbp), %eax
cmpl %eax, -8(%rbp)
cmovge -8(%rbp), %eax
leave
ret
max2 использует гораздо меньше кода из-за использования инструкции cmovge, Но реальная выгода в том, что max2 не включает в себя переходы по веткам, jmp, что привело бы к значительному снижению производительности, если прогнозируемый результат неверен.
Так почему же условный ход работает лучше?
В типичном x86 Процессор, выполнение инструкции делится на несколько этапов. Грубо говоря, у нас разное оборудование для разных этапов. Поэтому нам не нужно ждать окончания одной инструкции, чтобы начать новую. Это называется конвейерной обработкой.
В случае ветвления следующая инструкция определяется предыдущей, поэтому мы не можем выполнить конвейеризацию. Мы должны либо ждать, либо предсказывать.
В случае условного перемещения выполнение команды условного перемещения делится на несколько этапов, но более ранние этапы, такие как Fetch а также Decode не зависит от результата предыдущей инструкции; только последние этапы нуждаются в результате. Таким образом, мы ждем часть времени выполнения одной инструкции. Вот почему версия условного перемещения медленнее, чем ветвь, когда предсказание легко.
Книга " Компьютерные системы: взгляд программиста", второе издание, объясняет это подробно. Вы можете проверить Раздел 3.6.6 для Условных Инструкций Перемещения, всю Главу 4 для Архитектуры процессора и Раздел 5.11.2 для особого подхода к Штрафам за Предсказание и Неправильное предсказание.
Иногда некоторые современные компиляторы могут оптимизировать наш код для сборки с большей производительностью, иногда некоторые компиляторы не могут (рассматриваемый код использует собственный компилятор Visual Studio). Зная разницу в производительности между ветвлением и условным перемещением, когда он непредсказуем, может помочь нам написать код с лучшей производительностью, когда сценарий становится настолько сложным, что компилятор не может оптимизировать их автоматически.
Если вам интересно еще больше оптимизаций, которые можно сделать с этим кодом, подумайте об этом:
Начиная с оригинального цикла:
for (unsigned i = 0; i < 100000; ++i)
{
for (unsigned j = 0; j < arraySize; ++j)
{
if (data[j] >= 128)
sum += data[j];
}
}
С помощью обмена циклами мы можем смело изменить этот цикл на:
for (unsigned j = 0; j < arraySize; ++j)
{
for (unsigned i = 0; i < 100000; ++i)
{
if (data[j] >= 128)
sum += data[j];
}
}
Затем вы можете увидеть, что if условно является постоянным на протяжении всего выполнения i петля, так что вы можете поднять if из:
for (unsigned j = 0; j < arraySize; ++j)
{
if (data[j] >= 128)
{
for (unsigned i = 0; i < 100000; ++i)
{
sum += data[j];
}
}
}
Затем вы видите, что внутренний цикл можно свернуть в одно отдельное выражение, предполагая, что это допускает модель с плавающей запятой (например, /fp:fast выбрасывается)
for (unsigned j = 0; j < arraySize; ++j)
{
if (data[j] >= 128)
{
sum += data[j] * 100000;
}
}
Это в 100000 раз быстрее, чем раньше
Несомненно, некоторые из нас будут заинтересованы в способах идентификации кода, который проблематичен для предсказателя ветвления ЦП. Инструмент Valgrind cachegrind имеет симулятор предсказания ветвления, включенный с помощью --branch-sim=yes флаг. Рассмотрим примеры из этого вопроса, число внешних циклов уменьшено до 10000 и скомпилировано с g++ Дает эти результаты:
Сортировка:
==32551== Branches: 656,645,130 ( 656,609,208 cond + 35,922 ind)
==32551== Mispredicts: 169,556 ( 169,095 cond + 461 ind)
==32551== Mispred rate: 0.0% ( 0.0% + 1.2% )
Unsorted:
==32555== Branches: 655,996,082 ( 655,960,160 cond + 35,922 ind)
==32555== Mispredicts: 164,073,152 ( 164,072,692 cond + 460 ind)
==32555== Mispred rate: 25.0% ( 25.0% + 1.2% )
Развертывание в построчном выводе, производимом cg_annotate мы видим для рассматриваемой петли:
Сортировка:
Bc Bcm Bi Bim
10,001 4 0 0 for (unsigned i = 0; i < 10000; ++i)
. . . . {
. . . . // primary loop
327,690,000 10,016 0 0 for (unsigned c = 0; c < arraySize; ++c)
. . . . {
327,680,000 10,006 0 0 if (data[c] >= 128)
0 0 0 0 sum += data[c];
. . . . }
. . . . }
Unsorted:
Bc Bcm Bi Bim
10,001 4 0 0 for (unsigned i = 0; i < 10000; ++i)
. . . . {
. . . . // primary loop
327,690,000 10,038 0 0 for (unsigned c = 0; c < arraySize; ++c)
. . . . {
327,680,000 164,050,007 0 0 if (data[c] >= 128)
0 0 0 0 sum += data[c];
. . . . }
. . . . }
Это позволяет легко определить проблемную строку - в несортированной версии if (data[c] >= 128) линия вызывает 164,050,007 ошибочно предсказанных условных переходов (Bcm) в модели предсказателя ветвления в cachegrind, тогда как в отсортированной версии она вызывает только 10,006.
В качестве альтернативы, в Linux вы можете использовать подсистему счетчиков производительности для выполнения той же задачи, но с собственной производительностью с использованием счетчиков ЦП.
perf stat ./sumtest_sorted
Сортировка:
Performance counter stats for './sumtest_sorted':
11808.095776 task-clock # 0.998 CPUs utilized
1,062 context-switches # 0.090 K/sec
14 CPU-migrations # 0.001 K/sec
337 page-faults # 0.029 K/sec
26,487,882,764 cycles # 2.243 GHz
41,025,654,322 instructions # 1.55 insns per cycle
6,558,871,379 branches # 555.455 M/sec
567,204 branch-misses # 0.01% of all branches
11.827228330 seconds time elapsed
Unsorted:
Performance counter stats for './sumtest_unsorted':
28877.954344 task-clock # 0.998 CPUs utilized
2,584 context-switches # 0.089 K/sec
18 CPU-migrations # 0.001 K/sec
335 page-faults # 0.012 K/sec
65,076,127,595 cycles # 2.253 GHz
41,032,528,741 instructions # 0.63 insns per cycle
6,560,579,013 branches # 227.183 M/sec
1,646,394,749 branch-misses # 25.10% of all branches
28.935500947 seconds time elapsed
Он также может делать аннотации исходного кода с разборкой.
perf record -e branch-misses ./sumtest_unsorted
perf annotate -d sumtest_unsorted
Percent | Source code & Disassembly of sumtest_unsorted
------------------------------------------------
...
: sum += data[c];
0.00 : 400a1a: mov -0x14(%rbp),%eax
39.97 : 400a1d: mov %eax,%eax
5.31 : 400a1f: mov -0x20040(%rbp,%rax,4),%eax
4.60 : 400a26: cltq
0.00 : 400a28: add %rax,-0x30(%rbp)
...
Смотрите руководство по производительности для более подробной информации.
Я просто прочитал этот вопрос и его ответы, и я чувствую, что ответ отсутствует.
Обычный способ устранить предсказание ветвления, который, как мне показалось, особенно хорошо работает в управляемых языках, - это поиск в таблице вместо использования ветвления (хотя в этом случае я его не проверял).
Этот подход работает в целом, если:
- Это небольшая таблица, которая, вероятно, будет кэшироваться в процессоре.
- Вы работаете в довольно узком цикле и / или процессор может предварительно загрузить данные
Фон и почему
Пиф, так что, черт возьми, это должно значить?
С точки зрения процессора, ваша память работает медленно. Чтобы компенсировать разницу в скорости, они встроили в ваш процессор пару кэшей (кэш L1/L2), которые компенсируют это. Итак, представьте, что вы делаете свои хорошие вычисления и выясните, что вам нужен кусок памяти. Процессор выполнит операцию загрузки и загрузит часть памяти в кеш, а затем использует кеш для выполнения остальных вычислений. Поскольку память относительно медленная, эта "загрузка" замедлит вашу программу.
Как и предсказание ветвлений, это было оптимизировано в процессорах Pentium: процессор предсказывает, что ему нужно загрузить часть данных, и пытается загрузить их в кеш, прежде чем операция действительно попадет в кеш. Как мы уже видели, предсказание ветвления иногда идет ужасно неправильно - в худшем случае вам нужно вернуться назад и фактически ждать загрузки памяти, которая будет длиться вечно (другими словами: неудачное предсказание ветвления плохо, память загрузка после сбоя предсказания ветки просто ужасна!).
К счастью для нас, если схема доступа к памяти предсказуема, процессор загрузит ее в свой быстрый кеш, и все в порядке.
Первое, что нам нужно знать, это то, что мало? Хотя меньший размер, как правило, лучше, практическое правило заключается в том, чтобы придерживаться таблиц поиска размером <= 4096 байт. В качестве верхнего предела: если ваша таблица поиска больше 64 КБ, то, вероятно, стоит пересмотреть.
Построение стола
Итак, мы выяснили, что можем создать небольшую таблицу. Следующее, что нужно сделать, это установить на место функцию поиска. Функции поиска обычно представляют собой небольшие функции, которые используют несколько основных целочисленных операций (и, или, xor, shift, add, remove и, возможно, умножение). Вы хотите, чтобы ваш ввод был переведен с помощью функции поиска в какой-то "уникальный ключ" в вашей таблице, который затем просто дает вам ответ на всю работу, которую вы хотели, чтобы он делал.
В этом случае: >= 128 означает, что мы можем сохранить значение, < 128 означает, что мы избавимся от него. Самый простой способ сделать это - использовать 'И': если мы сохраняем это, мы И это с 7FFFFFFF; если мы хотим избавиться от него, мы И это с 0. Отметим также, что 128 - это степень 2 - так что мы можем пойти дальше и составить таблицу из 32768/128 целых чисел и заполнить ее одним нулем и большим количеством 7FFFFFFFF годов.
Управляемые языки
Вы можете удивиться, почему это хорошо работает на управляемых языках. В конце концов, управляемые языки проверяют границы массивов с помощью ветки, чтобы убедиться, что вы не ошиблись...
Ну, не совсем...:-)
Была проделана определенная работа по устранению этой ветки для управляемых языков. Например:
for (int i=0; i<array.Length; ++i)
// Use array[i]
В этом случае для компилятора очевидно, что граничное условие никогда не будет выполнено. По крайней мере компилятор Microsoft JIT (но я ожидаю, что Java делает подобные вещи) заметит это и вообще уберет проверку. WOW - это означает, что нет ветви. Точно так же это будет иметь дело с другими очевидными случаями.
Если у вас возникли проблемы с поиском на управляемых языках - ключ должен добавить & 0x[something]FFF к вашей функции поиска, чтобы сделать проверку границ предсказуемой - и смотреть, как она идет быстрее.
Результат этого дела
// Generate data
int arraySize = 32768;
int[] data = new int[arraySize];
Random rnd = new Random(0);
for (int c = 0; c < arraySize; ++c)
data[c] = rnd.Next(256);
//To keep the spirit of the code in-tact I'll make a separate lookup table
// (I assume we cannot modify 'data' or the number of loops)
int[] lookup = new int[256];
for (int c = 0; c < 256; ++c)
lookup[c] = (c >= 128) ? c : 0;
// Test
DateTime startTime = System.DateTime.Now;
long sum = 0;
for (int i = 0; i < 100000; ++i)
{
// Primary loop
for (int j = 0; j < arraySize; ++j)
{
// Here you basically want to use simple operations - so no
// random branches, but things like &, |, *, -, +, etc. are fine.
sum += lookup[data[j]];
}
}
DateTime endTime = System.DateTime.Now;
Console.WriteLine(endTime - startTime);
Console.WriteLine("sum = " + sum);
Console.ReadLine();
Поскольку данные распределяются между 0 и 255 при сортировке массива, около первой половины итераций не войдет в ifзаявление if заявление делится ниже).
if (data[c] >= 128)
sum += data[c];
Вопрос в том, что делает вышеприведенное утверждение не выполненным в некоторых случаях, например, в случае отсортированных данных? Здесь появляется "предсказатель ветви". Предиктор ветвления - это цифровая схема, которая пытается угадать, каким образом ветвь (например, if-then-else структура) пойдет до того, как это станет известно наверняка. Целью предиктора ветвления является улучшение потока в конвейере команд. Предсказатели ветвлений играют решающую роль в достижении высокой эффективности!
Давайте сделаем несколько тестов, чтобы понять это лучше
Производительность if-статирование зависит от того, имеет ли его состояние предсказуемый характер. Если условие всегда истинно или всегда ложно, логика предсказания ветвления в процессоре подберет шаблон. С другой стороны, если шаблон непредсказуем, ifЗаявление будет намного дороже.
Давайте измерим производительность этого цикла с различными условиями:
for (int i = 0; i < max; i++)
if (condition)
sum++;
Вот временные параметры цикла с различными шаблонами истина-ложь:
Condition Pattern Time (ms)
(i & 0×80000000) == 0 T repeated 322
(i & 0xffffffff) == 0 F repeated 276
(i & 1) == 0 TF alternating 760
(i & 3) == 0 TFFFTFFF… 513
(i & 2) == 0 TTFFTTFF… 1675
(i & 4) == 0 TTTTFFFFTTTTFFFF… 1275
(i & 8) == 0 8T 8F 8T 8F … 752
(i & 16) == 0 16T 16F 16T 16F … 490
"Плохой" истинно-ложный паттерн может сделать if- в шесть раз медленнее, чем "хороший" шаблон! Конечно, какой шаблон хорош, а какой плох, зависит от точных инструкций, сгенерированных компилятором, и от конкретного процессора.
Таким образом, нет никаких сомнений в отношении влияния отраслевого прогнозирования на производительность!
Одним из способов избежать ошибок предсказания ветвлений является создание таблицы поиска и индексация ее с использованием данных. Стефан де Брюин обсуждал это в своем ответе.
Но в этом случае мы знаем, что значения находятся в диапазоне [0, 255], и мы заботимся только о значениях>= 128. Это означает, что мы можем легко извлечь единственный бит, который скажет нам, хотим ли мы значение или нет: сдвигая данные справа 7 бит, у нас осталось 0 или 1 бит, и мы хотим добавить значение только тогда, когда у нас есть 1 бит. Давайте назовем этот бит "битом решения".
Используя значение 0/1 бита решения в качестве индекса в массиве, мы можем создать код, который будет одинаково быстрым, независимо от того, отсортированы данные или нет. Наш код всегда будет добавлять значение, но когда бит решения равен 0, мы добавим значение туда, где нам все равно. Вот код:
// Test
clock_t start = clock();
long long a[] = {0, 0};
long long sum;
for (unsigned i = 0; i < 100000; ++i)
{
// Primary loop
for (unsigned c = 0; c < arraySize; ++c)
{
int j = (data[c] >> 7);
a[j] += data[c];
}
}
double elapsedTime = static_cast<double>(clock() - start) / CLOCKS_PER_SEC;
sum = a[1];
Этот код тратит впустую половину добавления, но никогда не имеет ошибки предсказания ветвления. Это значительно быстрее на случайных данных, чем версия с фактическим оператором if.
Но в моем тестировании явная таблица поиска была немного быстрее, чем эта, вероятно, потому что индексирование в таблицу поиска было немного быстрее, чем битовое смещение. Это показывает, как мой код устанавливает и использует таблицу поиска (невообразимо называемую lut для "LookUp Table" в коде). Вот код C++:
// declare and then fill in the lookup table
int lut[256];
for (unsigned c = 0; c < 256; ++c)
lut[c] = (c >= 128) ? c : 0;
// use the lookup table after it is built
for (unsigned i = 0; i < 100000; ++i)
{
// Primary loop
for (unsigned c = 0; c < arraySize; ++c)
{
sum += lut[data[c]];
}
}
В этом случае таблица поиска составляла всего 256 байт, поэтому она хорошо помещалась в кеш, и все было быстро. Этот метод не сработает, если данные будут 24-битными значениями, а нам нужна только половина из них... таблица поиска будет слишком большой, чтобы быть практичной. С другой стороны, мы можем объединить два метода, показанных выше: сначала сдвинуть биты, а затем проиндексировать таблицу поиска. Для 24-битного значения, для которого нам нужно только верхнее половинное значение, мы могли бы сдвинуть данные вправо на 12 бит и оставить 12-битное значение для индекса таблицы. 12-битный индекс таблицы подразумевает таблицу из 4096 значений, что может быть практичным.
РЕДАКТИРОВАТЬ: Одна вещь, которую я забыл вставить.
Техника индексации в массив, вместо использования if оператор, может быть использован для решения, какой указатель использовать. Я увидел библиотеку, в которой реализованы двоичные деревья, и вместо двух именованных указателей (pLeft а также pRight или что-то еще) имел массив указателей длины-2 и использовал технику "решающий бит", чтобы решить, какой из них следовать. Например, вместо:
if (x < node->value)
node = node->pLeft;
else
node = node->pRight;
эта библиотека будет делать что-то вроде:
i = (x < node->value);
node = node->link[i];
Вот ссылка на этот код: Красные черные деревья, вечно сбитые с толку
В отсортированном случае вы можете добиться большего успеха, чем полагаться на успешное предсказание ветвлений или любую хитрость сравнения без ветвей: полностью удалить ветвь.
Действительно, массив разделен в смежной зоне с data < 128 и еще один с data >= 128, Таким образом, вы должны найти точку разделения с помощью дихотомического поиска (используя Lg(arraySize) = 15 сравнения), а затем сделать прямое накопление с этой точки.
Что-то вроде (не проверено)
int i= 0, j, k= arraySize;
while (i < k)
{
j= (i + k) >> 1;
if (data[j] >= 128)
k= j;
else
i= j;
}
sum= 0;
for (; i < arraySize; i++)
sum+= data[i];
или, немного более запутанный
int i, k, j= (i + k) >> 1;
for (i= 0, k= arraySize; i < k; (data[j] >= 128 ? k : i)= j)
j= (i + k) >> 1;
for (sum= 0; i < arraySize; i++)
sum+= data[i];
Еще более быстрый подход, который дает приблизительное решение для сортированных и не отсортированных: sum= 3137536; (при условии действительно равномерного распределения, 16384 выборки с ожидаемым значением 191,5) :-)
Вышеупомянутое поведение происходит из-за предсказания Ветви.
Чтобы понять предсказание ветвления, нужно сначала понять конвейер инструкций:
Любая инструкция разбита на последовательность шагов, так что разные шаги могут выполняться параллельно параллельно. Этот метод известен как конвейер команд и используется для увеличения пропускной способности современных процессоров. Чтобы лучше это понять, посмотрите этот пример в Википедии.
Как правило, современные процессоры имеют довольно длинные конвейеры, но для удобства рассмотрим только эти 4 шага.
- IF - извлечь инструкцию из памяти
- ID - Расшифровать инструкцию
- EX - выполнить инструкцию
- WB - запись обратно в регистр процессора
4-х ступенчатый конвейер в целом по 2 инструкции. 
Возвращаясь к вышеупомянутому вопросу, давайте рассмотрим следующие инструкции:
A) if (data[c] >= 128)
/\
/ \
/ \
true / \ false
/ \
/ \
/ \
/ \
B) sum += data[c]; C) for loop or print().
Без прогнозирования ветвления может произойти следующее:
Чтобы выполнить инструкцию B или инструкцию C, процессор должен будет ждать, пока инструкция A не достигнет стадии EX в конвейере, поскольку решение перейти к инструкции B или инструкции C зависит от результата инструкции A. Таким образом, конвейер будет выглядеть так
когда условие возвращает true: 
Когда условие возвращает ложное: 
В результате ожидания результата инструкции A общее количество циклов ЦП, проведенных в вышеупомянутом случае (без прогнозирования ветвления; как для истинного, так и для ложного), равно 7.
Так что же такое прогноз отрасли?
Предсказатель ветвления попытается угадать, каким образом пойдет ветвь (структура if-then-else), прежде чем это станет известно наверняка. Он не будет ждать, пока инструкция A достигнет стадии EX конвейера, но он угадает решение и перейдет к этой инструкции (B или C в случае нашего примера).
В случае правильного предположения, конвейер выглядит примерно так: 
Если позднее обнаруживается, что предположение было неверным, то частично выполненные инструкции отбрасываются, и конвейер начинается с правильной ветви, что вызывает задержку. Время, которое теряется в случае неправильного прогнозирования ветвления, равно количеству этапов в конвейере от этапа выборки до этапа выполнения. Современные микропроцессоры, как правило, имеют довольно длинные конвейеры, поэтому задержка неверного прогнозирования составляет от 10 до 20 тактов. Чем длиннее конвейер, тем больше потребность в хорошем предсказателе ветвления.
В коде OP первый раз, когда выполняется условие, предсказатель ветвления не имеет никакой информации для обоснования предсказания, поэтому в первый раз он случайным образом выберет следующую инструкцию. Позже в цикле for он может основывать прогноз на истории. Для массива, отсортированного в порядке возрастания, есть три возможности:
- Все элементы меньше 128
- Все элементы больше 128
- Некоторые начинающие новые элементы меньше 128 и позже становятся больше 128
Предположим, что предиктор всегда будет принимать истинную ветвь при первом запуске.
Так что в первом случае он всегда будет принимать истинную ветвь, поскольку исторически все его предсказания верны. Во 2-м случае изначально он будет предсказывать неверно, но после нескольких итераций он будет предсказывать правильно. В третьем случае он изначально будет правильно прогнозировать до тех пор, пока элементы не станут меньше 128. После чего он потерпит неудачу в течение некоторого времени и сам исправится, когда увидит ошибку прогнозирования ветвления в истории.
Во всех этих случаях количество ошибок будет меньше, и в результате всего лишь несколько раз потребуется отменить частично выполненные инструкции и начать заново с правильной ветвью, что приведет к уменьшению циклов ЦП.
Но в случае случайного несортированного массива прогноз должен отбросить частично выполненные инструкции и большую часть времени начинать с правильной ветви, что приведет к большему количеству циклов ЦП по сравнению с отсортированным массивом.
Официальный ответ будет от
- Intel - Предотвращение ошибочных прогнозов отрасли
- Intel - реорганизация филиалов и циклов для предотвращения ошибочных прогнозов
- Научные труды - отраслевое прогнозирование компьютерной архитектуры
- Книги: Дж. Л. Хеннесси, Д. А. Паттерсон: Компьютерная архитектура: количественный подход
- Статьи в научных публикациях: TY Yeh, YN Patt сделал много из них по отраслевым прогнозам.
Вы также можете увидеть из этой прекрасной диаграммы, почему предсказатель ветвления запутывается.

Каждый элемент в исходном коде является случайным значением
data[c] = std::rand() % 256;
поэтому предиктор будет меняться сторонами как std::rand() дуть.
С другой стороны, после сортировки предиктор сначала переходит в состояние строго не принятого, а когда значения изменяются до высокого значения, предиктор за три прогона изменяется полностью от сильно не принятого до строго принятого.
В той же строке (я думаю, что это не было выделено ни одним ответом) хорошо упомянуть, что иногда (особенно в программном обеспечении, где производительность имеет значение - как в ядре Linux) вы можете найти некоторые операторы if, подобные следующему:
if (likely( everything_is_ok ))
{
/* Do something */
}
или аналогично:
if (unlikely(very_improbable_condition))
{
/* Do something */
}
И то и другое likely() а также unlikely() на самом деле макросы, которые определяются с помощью чего-то вроде GCC __builtin_expect чтобы помочь компилятору вставить код прогнозирования в пользу условия с учетом информации, предоставленной пользователем. GCC поддерживает другие встроенные функции, которые могут изменить поведение работающей программы или выдавать низкоуровневые инструкции, такие как очистка кэша и т. Д. См. Эту документацию, в которой рассматриваются доступные встроенные функции GCC.
Обычно такого рода оптимизации в основном встречаются в приложениях реального времени или встроенных системах, где время выполнения имеет значение, и оно критично. Например, если вы проверяете какое-либо условие ошибки, которое происходит только 1/10000000 раз, то почему бы не сообщить об этом компилятору? Таким образом, по умолчанию прогноз ветвления предполагает, что условие ложно.
Часто используемые логические операции в C++ создают много веток в скомпилированной программе. Если эти ветви находятся внутри циклов и их трудно предсказать, они могут значительно замедлить выполнение. Булевы переменные хранятся в виде 8-битных целых чисел со значением 0 за false а также 1 за true,
Булевы переменные переопределены в том смысле, что все операторы, которые имеют логические переменные в качестве входных данных, проверяют, имеют ли входные значения любое другое значение, кроме 0 или же 1, но операторы, которые имеют логические значения в качестве выходных данных, не могут давать никакого другого значения, кроме 0 или же 1, Это делает операции с булевыми переменными в качестве входных данных менее эффективными, чем необходимо. Рассмотрим пример:
bool a, b, c, d;
c = a && b;
d = a || b;
Обычно это реализуется компилятором следующим образом:
bool a, b, c, d;
if (a != 0) {
if (b != 0) {
c = 1;
}
else {
goto CFALSE;
}
}
else {
CFALSE:
c = 0;
}
if (a == 0) {
if (b == 0) {
d = 0;
}
else {
goto DTRUE;
}
}
else {
DTRUE:
d = 1;
}
Этот код далеко не оптимален. Ветви могут занять много времени в случае неправильных прогнозов. Булевы операции можно сделать намного более эффективными, если точно известно, что операнды не имеют других значений, кроме 0 а также 1, Причина, по которой компилятор не делает такого предположения, заключается в том, что переменные могут иметь другие значения, если они неинициализированы или получены из неизвестных источников. Приведенный выше код может быть оптимизирован, если a а также b были инициализированы для допустимых значений или если они получены от операторов, которые производят логический вывод. Оптимизированный код выглядит так:
char a = 0, b = 1, c, d;
c = a & b;
d = a | b;
char используется вместо bool чтобы можно было использовать побитовые операторы (& а также |) вместо логических операторов (&& а также ||). Побитовые операторы - это одиночные инструкции, которые занимают только один такт. Оператор ИЛИ (|) работает даже если a а также b имеют другие значения, чем 0 или же 1, Оператор И (&) и оператор ИСКЛЮЧИТЕЛЬНОЕ ИЛИ (^) может давать противоречивые результаты, если операнды имеют другие значения, чем 0 а также 1,
~ не может быть использован для НЕ. Вместо этого вы можете сделать логическое НЕ для переменной, которая известна как 0 или же 1 XOR'ing это с 1:
bool a, b;
b = !a;
можно оптимизировать для:
char a = 0, b;
b = a ^ 1;
a && b не может быть заменено на a & b если b это выражение, которое не следует оценивать, если a является false (&& не буду оценивать b, & будут). Точно так же, a || b не может быть заменено на a | b если b это выражение, которое не следует оценивать, если a является true,
Использование побитовых операторов более выгодно, если операнды являются переменными, чем если операнды являются сравнениями:
bool a; double x, y, z;
a = x > y && z < 5.0;
является оптимальным в большинстве случаев (если вы не ожидаете && выражение для генерации многих ветвлений
Это уж точно!...
Предсказание ветвлений замедляет работу логики из-за переключения, которое происходит в вашем коде! Как будто вы идете по прямой улице или улице с большим количеством поворотов, наверняка прямая будет сделана быстрее!...
Если массив отсортирован, ваше условие ложно на первом шаге: data[c] >= 128, затем становится истинной ценностью на весь путь до конца улицы. Вот так вы быстрее доберетесь до конца логики. С другой стороны, используя несортированный массив, вам нужно много переворачивать и обрабатывать, что наверняка сделает ваш код медленнее...
Посмотрите на изображение, которое я создал для вас ниже. Какая улица будет закончена быстрее?

Таким образом, программно предсказание ветвлений приводит к замедлению процесса...
Также, в конце концов, хорошо знать, что у нас есть два вида предсказаний ветвлений, каждый из которых по-разному повлияет на ваш код:
1. Статический
2. Динамический

Предсказание статических переходов используется микропроцессором при первом обнаружении условного перехода, а динамическое прогнозирование ветвления используется для успешного выполнения кода условного перехода.
Чтобы эффективно написать свой код, чтобы воспользоваться этими правилами, при написании операторов if-else или switch сначала проверьте наиболее распространенные случаи и постепенно переходите к наименьшим. Циклы не обязательно требуют какого-либо специального упорядочения кода для статического предсказания ветвления, поскольку обычно используется только условие итератора цикла.
На этот вопрос уже много раз отвечали превосходно. Тем не менее, я хотел бы обратить внимание группы на еще один интересный анализ.
Недавно этот пример (измененный очень незначительно) также использовался для демонстрации того, как фрагмент кода может быть профилирован в самой программе в Windows. Попутно автор также показывает, как использовать результаты, чтобы определить, где код проводит большую часть своего времени как в отсортированном, так и в несортированном случае. Наконец, в этой части также показано, как использовать малоизвестную функцию HAL (Уровень аппаратной абстракции), чтобы определить, насколько часто происходит неправильное предсказание ветвления в несортированном случае.
Ссылка находится здесь: http://www.geoffchappell.com/studies/windows/km/ntoskrnl/api/ex/profile/demo.htm
Как и то, что уже было упомянуто другими, то, что скрывается за тайной, - это предсказатель отрасли.
Я не пытаюсь что-то добавить, а объясняю концепцию по-другому. Существует краткое введение в вики, которое содержит текст и диаграмму. Мне нравится объяснение ниже, которое использует диаграмму для интуитивного развития Предиктора ветвей.
В компьютерной архитектуре предиктор ветвления - это цифровая схема, которая пытается угадать, каким образом пойдет ветвь (например, структура if-then-else), прежде чем это станет известно наверняка. Целью предиктора ветвления является улучшение потока в конвейере команд. Предсказатели ветвлений играют решающую роль в достижении высокой эффективной производительности во многих современных конвейерных микропроцессорных архитектурах, таких как x86.
Двустороннее ветвление обычно реализуется с помощью инструкции условного перехода. Условный переход может быть либо "не взят" и продолжен с первой ветвью кода, которая следует сразу после условного перехода, либо его можно "взять" и перейти в другое место в памяти программ, где находится вторая ветвь кода. сохраняются. Точно неизвестно, будет ли выполнен условный переход или нет, пока условие не будет вычислено и условный переход не пройдет этап выполнения в конвейере команд (см. Рис. 1).

На основе описанного сценария я написал демонстрационную анимацию, чтобы показать, как выполняются инструкции в конвейере в различных ситуациях.
- Без предсказателя отрасли.
Без предсказания перехода процессор должен был бы ждать, пока инструкция условного перехода не пройдет этап выполнения, прежде чем следующая команда сможет перейти на этап выборки в конвейере.
В примере содержатся три инструкции, а первая - это инструкция условного перехода. Последние две инструкции могут идти в конвейер, пока не будет выполнена команда условного перехода.

Для выполнения 3-х инструкций потребуется 9 тактов.
- Используйте Branch Predictor и не делайте условный переход. Давайте предположим, что прогноз не принимает условный переход.

Для выполнения 3-х инструкций потребуется 7 тактов.
- Используйте Branch Predictor и сделайте условный прыжок. Давайте предположим, что прогноз не принимает условный переход.
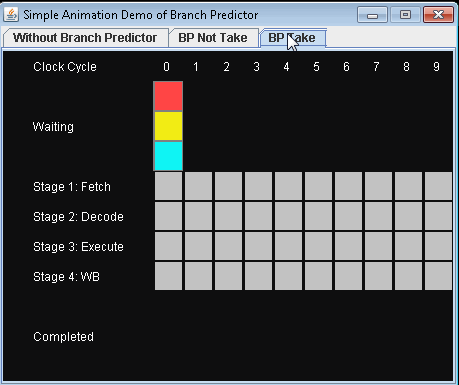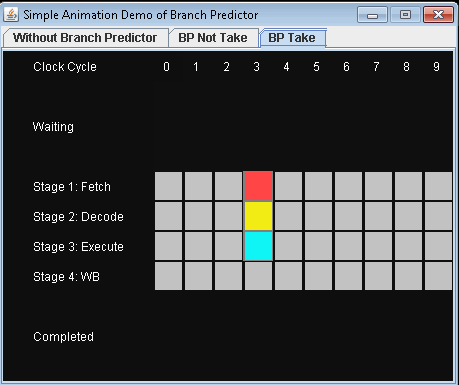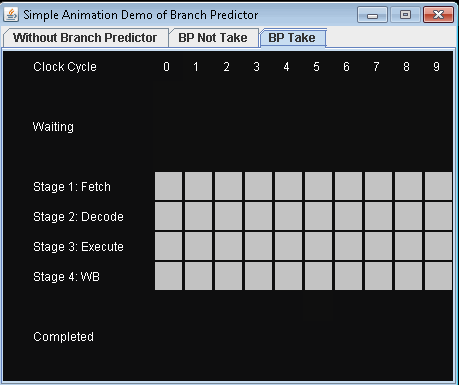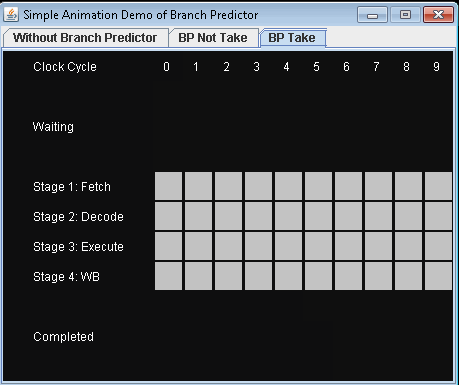
Для выполнения 3-х инструкций потребуется 9 тактов.
Время, которое теряется в случае неправильного прогнозирования ветвления, равно количеству этапов в конвейере от этапа выборки до этапа выполнения. Современные микропроцессоры, как правило, имеют довольно длинные конвейеры, поэтому задержка неверного прогнозирования составляет от 10 до 20 тактов. В результате, увеличение длины конвейера увеличивает потребность в более продвинутом предикторе ветвления.
Как видите, у нас нет причин не использовать Branch Predictor.
Это довольно простая демонстрация, которая разъясняет самую основную часть Branch Predictor. Если эти картинки раздражают, пожалуйста, удалите их из ответа, и посетители также могут получить демо из git
Выгода предсказания ветвлений!
Важно понимать, что неправильное прогнозирование веток не замедляет работу программ. Стоимость пропущенного прогноза такая же, как если бы прогноз ветвления не существовал, и вы подождали, пока оценка выражения решит, какой код запустить (дальнейшее объяснение в следующем абзаце).
if (expression)
{
// Run 1
} else {
// Run 2
}
Всякий раз, когда есть if-else \ switch оператор, выражение должно быть оценено, чтобы определить, какой блок должен быть выполнен. В коде сборки, сгенерированном компилятором, вставляются инструкции условного перехода.
Команда ветвления может заставить компьютер начать выполнение другой последовательности команд и, таким образом, отклониться от своего поведения по умолчанию при выполнении команд по порядку (то есть, если выражение ложно, программа пропускает код if блок) в зависимости от некоторого условия, которое является оценкой выражения в нашем случае.
При этом компилятор пытается предсказать результат до его фактической оценки. Он будет получать инструкции от if блок, и если выражение окажется правдой, то замечательно! Мы получили время, необходимое для его оценки, и добились прогресса в коде; если нет, то мы выполняем неправильный код, конвейер сбрасывается и запускается правильный блок.
Визуализация:
Допустим, вам нужно выбрать маршрут 1 или маршрут 2. В ожидании вашего партнера, чтобы проверить карту, вы остановились на ## и ждали, или вы можете просто выбрать маршрут 1 и, если вам повезло (маршрут 1 является правильным маршрутом), тогда здорово, что вам не нужно было ждать, пока ваш партнер проверит карту (вы сэкономили время, которое потребовалось бы ему, чтобы проверить карту), иначе вы просто вернетесь назад.
В то время как промывка трубопроводов очень быстрая, в настоящее время эта игра стоит того. Прогнозировать отсортированные данные или данные, которые изменяются медленно, всегда проще и лучше, чем прогнозировать быстрые изменения.
O Route 1 /-------------------------------
/|\ /
| ---------##/
/ \ \
\
Route 2 \--------------------------------
В ARM ветвление не требуется, поскольку каждая инструкция имеет 4-битное поле условия, которое тестируется с нулевой стоимостью. Это устраняет необходимость в коротких ветвях, и не будет никакого предсказания ветвлений. Поэтому отсортированная версия будет работать медленнее, чем несортированная версия в ARM, из-за дополнительных издержек сортировки. Внутренний цикл будет выглядеть примерно так:
MOV R0, #0 // R0 = sum = 0
MOV R1, #0 // R1 = c = 0
ADR R2, data // R2 = addr of data array (put this instruction outside outer loop)
.inner_loop // Inner loop branch label
LDRB R3, [R2, R1] // R3 = data[c]
CMP R3, #128 // compare R3 to 128
ADDGE R0, R0, R3 // if R3 >= 128, then sum += data[c] -- no branch needed!
ADD R1, R1, #1 // c++
CMP R1, #arraySize // compare c to arraySize
BLT inner_loop // Branch to inner_loop if c < arraySize
Это про предсказание ветвлений. Что это?
Предсказатель ветвей - это одна из древних технологий повышения производительности, которая все еще находит применение в современных архитектурах. Хотя простые методы прогнозирования обеспечивают быстрый поиск и эффективность энергопотребления, они страдают от высокой степени неверного прогнозирования.
С другой стороны, сложные предсказания ветвления - либо нейронные, либо варианты двухуровневого предсказания ветвления - обеспечивают лучшую точность предсказания, но они потребляют больше энергии, а сложность возрастает экспоненциально.
В дополнение к этому, в сложных методах прогнозирования время, затрачиваемое на прогнозирование ветвей, само по себе очень велико - в диапазоне от 2 до 5 циклов - что сравнимо со временем выполнения фактических ветвей.
Прогнозирование ветвлений - это, по сути, проблема оптимизации (минимизации), в которой основное внимание уделяется достижению минимально возможного числа пропусков, низкого энергопотребления и низкой сложности с минимальными ресурсами.
На самом деле существует три вида ветвей:
Пересылка условных переходов - в зависимости от времени выполнения ПК (программный счетчик) изменяется, чтобы указывать на адрес пересылки в потоке команд.
Обратные условные ветви - ПК изменяется, чтобы указывать в обратном направлении в потоке команд. Ветвление основано на некотором условии, таком как ветвление назад к началу цикла программы, когда тест в конце цикла указывает, что цикл должен быть выполнен снова.
Безусловные переходы - это включает переходы, вызовы процедур и возвраты, которые не имеют особых условий. Например, команда безусловного перехода может быть закодирована на ассемблере как просто "jmp", и поток команд должен быть немедленно направлен в целевое местоположение, на которое указывает инструкция перехода, тогда как условный переход, который может быть закодирован как "jmpne" будет перенаправлять поток команд только в том случае, если результат сравнения двух значений в предыдущих инструкциях "сравнения" показывает, что значения не равны. (Схема сегментированной адресации, используемая архитектурой x86, добавляет дополнительную сложность, поскольку переходы могут быть "ближними" (внутри сегмента) или "дальними" (вне сегмента). Каждый тип по-разному влияет на алгоритмы прогнозирования ветвлений.)
Статическое / динамическое предсказание ветвления: Статическое предсказание ветвления используется микропроцессором при первом обнаружении условного перехода, а динамическое предсказание ветвления используется для последующих выполнений кода условного перехода.
Рекомендации:
Помимо того, что предсказание ветвления может замедлить вас, у отсортированного массива есть еще одно преимущество:
Вы можете иметь условие остановки вместо простой проверки значения, таким образом вы только зацикливаетесь на соответствующих данных и игнорируете остальные.
Прогноз ветвления будет пропущен только один раз.
// sort backwards (higher values first)
std::sort(data, data + arraySize, std::greater<int>());
for (unsigned c = 0; c < arraySize; ++c) {
if (data[c] < 128) {
break;
}
sum += data[c];
}
Сортированные массивы обрабатываются быстрее, чем несортированный массив, из-за явлений, называемых предсказанием ветвлений.
Предиктор ветвления - это цифровая схема (в компьютерной архитектуре), которая пытается предсказать, как пойдет ветвь, улучшая поток в конвейере команд. Схема / компьютер предсказывает следующий шаг и выполняет его.
Неправильный прогноз приводит к возврату к предыдущему шагу и выполнению с другим прогнозом. Если предположить, что прогноз верен, код перейдет к следующему шагу. Неправильный прогноз приводит к повторению одного и того же шага, пока не произойдет правильный прогноз.
Ответ на ваш вопрос очень прост.
В несортированном массиве компьютер делает несколько прогнозов, что повышает вероятность возникновения ошибок. В то время как в отсортированном виде компьютер делает меньше прогнозов, что снижает вероятность ошибок. Создание большего прогноза требует больше времени.
Сортированный массив: прямая дорога
____________________________________________________________________________________
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
TTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTT
Несортированный массив: Кривая дорога
______ ________
| |__|
Прогноз ветвления: угадать / предсказать, какая дорога прямая и следовать по ней без проверки
___________________________________________ Straight road
|_________________________________________|Longer road
Хотя обе дороги достигают одного и того же пункта назначения, прямая дорога короче, а другая длиннее. Если тогда вы выберете другой по ошибке, пути назад не будет, и поэтому вы потеряете дополнительное время, если выберете более длинную дорогу. Это похоже на то, что происходит на компьютере, и я надеюсь, что это помогло вам лучше понять.
Обновление: после того, что сказал @Simon_Weaver, я хочу добавить еще один факт: "он не делает меньше прогнозов - он делает меньше неправильных прогнозов. Он все еще должен предсказывать каждый раз в цикле".
Я пробовал тот же код с MATLAB 2011b с моим MacBook Pro (Intel i7, 64 бит, 2,4 ГГц) для следующего кода MATLAB:
% Processing time with Sorted data vs unsorted data
%==========================================================================
% Generate data
arraySize = 32768
sum = 0;
% Generate random integer data from range 0 to 255
data = randi(256, arraySize, 1);
%Sort the data
data1= sort(data); % data1= data when no sorting done
%Start a stopwatch timer to measure the execution time
tic;
for i=1:100000
for j=1:arraySize
if data1(j)>=128
sum=sum + data1(j);
end
end
end
toc;
ExeTimeWithSorting = toc - tic;
Результаты для приведенного выше кода MATLAB следующие:
a: Elapsed time (without sorting) = 3479.880861 seconds.
b: Elapsed time (with sorting ) = 2377.873098 seconds.
Результаты кода C, как в @GManNickG, я получаю:
a: Elapsed time (without sorting) = 19.8761 sec.
b: Elapsed time (with sorting ) = 7.37778 sec.
Исходя из этого, похоже, что MATLAB почти в 175 раз медленнее, чем реализация C без сортировки и в 350 раз медленнее с сортировкой. Другими словами, эффект (предсказания ветвления) составляет 1,46x для реализации MATLAB и 2,7x для реализации C.
Предположение другими ответами о том, что нужно сортировать данные, неверно.
Следующий код сортирует не весь массив, а только его 200-элементные сегменты и, следовательно, работает быстрее всего.
Сортировка только разделов k-элемента завершает предварительную обработку в линейное время, а не n.log(n),
#include <algorithm>
#include <ctime>
#include <iostream>
int main() {
int data[32768]; const int l = sizeof data / sizeof data[0];
for (unsigned c = 0; c < l; ++c)
data[c] = std::rand() % 256;
// sort 200-element segments, not the whole array
for (unsigned c = 0; c + 200 <= l; c += 200)
std::sort(&data[c], &data[c + 200]);
clock_t start = clock();
long long sum = 0;
for (unsigned i = 0; i < 100000; ++i) {
for (unsigned c = 0; c < sizeof data / sizeof(int); ++c) {
if (data[c] >= 128)
sum += data[c];
}
}
std::cout << static_cast<double>(clock() - start) / CLOCKS_PER_SEC << std::endl;
std::cout << "sum = " << sum << std::endl;
}
Это также "доказывает", что это не имеет никакого отношения к каким-либо алгоритмическим проблемам, таким как порядок сортировки, и это действительно предсказание ветвлений.
Ответ Бьярна Страуструпа на этот вопрос:
Это похоже на вопрос на собеседовании. Это правда? Как бы вы узнали? Ответить на вопросы об эффективности без предварительного измерения - плохая идея, поэтому важно знать, как это делать.
Итак, я попробовал с вектором из миллиона целых чисел и получил:
Already sorted 32995 milliseconds
Shuffled 125944 milliseconds
Already sorted 18610 milliseconds
Shuffled 133304 milliseconds
Already sorted 17942 milliseconds
Shuffled 107858 milliseconds
Я запускал это несколько раз, чтобы убедиться. Да, феномен реальный. Мой ключевой код был:
void run(vector<int>& v, const string& label)
{
auto t0 = system_clock::now();
sort(v.begin(), v.end());
auto t1 = system_clock::now();
cout << label
<< duration_cast<microseconds>(t1 — t0).count()
<< " milliseconds\n";
}
void tst()
{
vector<int> v(1'000'000);
iota(v.begin(), v.end(), 0);
run(v, "already sorted ");
std::shuffle(v.begin(), v.end(), std::mt19937{ std::random_device{}() });
run(v, "shuffled ");
}
По крайней мере, такое явление реально с этим компилятором, стандартной библиотекой и настройками оптимизатора. Различные реализации могут давать и дают разные ответы. Фактически, кто-то провел более систематическое исследование (его можно найти при быстром поиске в Интернете), и большинство реализаций демонстрируют этот эффект.
Одна из причин - предсказание ветвления: ключевая операция в алгоритме сортировки “if(v[i] < pivot]) …”или эквивалент. Для отсортированной последовательности этот тест всегда верен, тогда как для случайной последовательности выбранная ветвь изменяется случайным образом.
Другая причина в том, что когда вектор уже отсортирован, нам никогда не нужно перемещать элементы в их правильное положение. Эффект от этих мелких деталей в пять или шесть раз, что мы видели.
Быстрая сортировка (и сортировка в целом) - это сложное исследование, которое привлекло некоторые из величайших умов информатики. Хорошая функция сортировки - это результат выбора хорошего алгоритма и уделения внимания производительности оборудования при его реализации.
Если вы хотите писать эффективный код, вам нужно немного знать об архитектуре машины.
Этот вопрос коренится в моделях прогнозирования переходов на процессорах. Я бы рекомендовал прочитать эту статью:
Когда вы отсортировали элементы, IR может не беспокоиться о том, чтобы снова и снова извлекать все инструкции ЦП, он извлекает их из кеша.
Один из способов избежать ошибок прогнозирования ветвления - создать таблицу поиска и проиндексировать ее с использованием данных. Стефан де Брейн обсудил это в своем ответе.
Но в этом случае мы знаем, что значения находятся в диапазоне [0, 255], и нас интересуют только значения>= 128. Это означает, что мы можем легко извлечь один бит, который скажет нам, хотим ли мы значение или нет: путем сдвига данные в правые 7 бит, у нас остается 0 бит или 1 бит, и мы хотим добавить значение только тогда, когда у нас есть 1 бит. Назовем этот бит "бит решения".
Используя значение 0/1 бита решения в качестве индекса в массиве, мы можем сделать код, который будет одинаково быстрым независимо от того, отсортированы данные или нет. Наш код всегда будет добавлять значение, но когда бит решения равен 0, мы добавим значение туда, где нас не волнует. Вот код:
// Контрольная работа
clock_t start = clock();
long long a[] = {0, 0};
long long sum;
for (unsigned i = 0; i < 100000; ++i)
{
// Primary loop
for (unsigned c = 0; c < arraySize; ++c)
{
int j = (data[c] >> 7);
a[j] += data[c];
}
}
double elapsedTime = static_cast<double>(clock() - start) / CLOCKS_PER_SEC;
sum = a[1];
Этот код тратит впустую половину добавлений, но никогда не приводит к ошибке предсказания ветвления. Это намного быстрее для случайных данных, чем версия с фактическим оператором if.
Но в моем тестировании явная таблица поиска была немного быстрее, чем эта, вероятно, потому, что индексация в таблице поиска была немного быстрее, чем сдвиг бит. Это показывает, как мой код настраивает и использует справочную таблицу (в коде невообразимо названную lut для "LookUp Table"). Вот код C++:
// Объявить, а затем заполнить таблицу поиска
int lut[256];
for (unsigned c = 0; c < 256; ++c)
lut[c] = (c >= 128) ? c : 0;
// Use the lookup table after it is built
for (unsigned i = 0; i < 100000; ++i)
{
// Primary loop
for (unsigned c = 0; c < arraySize; ++c)
{
sum += lut[data[c]];
}
}
В этом случае таблица поиска была всего 256 байтов, поэтому она хорошо помещалась в кеш, и все было быстро. Этот метод не сработал бы, если бы данные были 24-битными значениями, а нам нужна была бы только половина из них... таблица поиска была бы слишком большой, чтобы ее можно было использовать на практике. С другой стороны, мы можем комбинировать две техники, показанные выше: сначала сдвинуть биты, а затем проиндексировать таблицу поиска. Для 24-битного значения, которое нам нужна только верхняя половина значения, мы потенциально могли бы сдвинуть данные вправо на 12 бит и оставить 12-битное значение для индекса таблицы. 12-битный табличный индекс подразумевает таблицу из 4096 значений, что может быть практичным.
Метод индексации в массиве вместо использования оператора if может использоваться для решения, какой указатель использовать. Я видел библиотеку, в которой реализованы бинарные деревья, и вместо двух именованных указателей (pLeft и pRight или что-то еще) имел массив указателей длиной 2 и использовал технику "бит решения", чтобы решить, за каким из них следовать. Например, вместо:
if (x < node->value)
node = node->pLeft;
else
node = node->pRight;
this library would do something like:
i = (x < node->value);
node = node->link[i];
Это хорошее решение, и, возможно, оно сработает.
Эта концепция называется предсказанием ветвления.
Предсказание ветвления - это метод оптимизации, который предсказывает путь, по которому код пойдет до того, как он станет известен с уверенностью. Это важно, потому что во время выполнения кода машина предварительно выбирает несколько операторов кода и сохраняет их в конвейере.
Проблема возникает при условном ветвлении, где есть два возможных пути или части кода, которые могут быть выполнены.
Когда предсказание сбылось, техника оптимизации сработала.
Если предсказание оказалось ложным, то, чтобы объяснить это простым способом, оператор кода, хранящийся в конвейере, оказывается неверным, и фактический код должен быть полностью перезагружен, что занимает много времени.
Как подсказывает здравый смысл, предсказания чего-то отсортированного намного точнее, чем предсказания чего-то несортированного.
Визуализация предсказания ветвления:
отсортировано
 несортировано
несортировано
Это называется предсказанием ветвления . Без предсказания ветвления процессору пришлось бы ждать, пока команда условного перехода не пройдет стадию выполнения, прежде чем следующая инструкция сможет войти в стадию выборки в конвейере. Предиктор перехода пытается избежать этой траты времени, пытаясь угадать, будет ли условный переход скорее всего выполнен или нет. Затем выбирается и предположительно выполняется наиболее вероятная ветвь. Если позже обнаруживается, что предположение было неверным, то выполняется предположительное выполнение с задержкой.
data[c] >= 128
Получите дополнительную помощь по этой ссылке: Прогнозирование множественных ветвей для суперскаляра с широкими проблемами
Почему обработка отсортированного массива выполняется быстрее, чем обработка несортированного массива?
Пример из кода:
// CPP program to demonstrate processing
// time of sorted and unsorted array
#include <iostream>
#include <algorithm>
#include <ctime>
using namespace std;
const int N = 100001;
int main()
{
int arr[N];
// Assign random values to array
for (int i=0; i<N; i++)
arr[i] = rand()%N;
// for loop for unsorted array
int count = 0;
double start = clock();
for (int i=0; i<N; i++)
if (arr[i] < N/2)
count++;
double end = clock();
cout << "Time for unsorted array :: "
<< ((end - start)/CLOCKS_PER_SEC)
<< endl;
sort(arr, arr+N);
// for loop for sorted array
count = 0;
start = clock();
for (int i=0; i<N; i++)
if (arr[i] < N/2)
count++;
end = clock();
cout << "Time for sorted array :: "
<< ((end - start)/CLOCKS_PER_SEC)
<< endl;
return 0;
}
Срок исполнения:
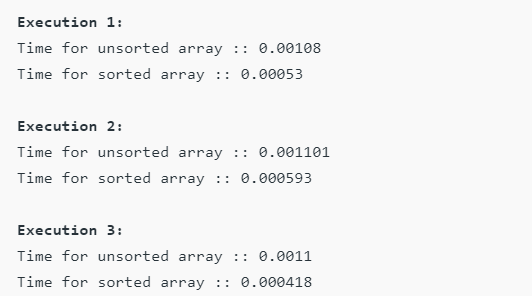
Заключение:
Обратите внимание, что время, затрачиваемое на обработку отсортированного массива, меньше по сравнению с несортированным. Причиной этой оптимизации для отсортированных массивов является предсказание ветвлений.
Что такое предсказание ветвления?
Прогнозирование ветвлений в компьютерной архитектуре фокусируется на определении того, будет ли выполнено условное ветвление (переход) в конвейере инструкций программы или нет. Поскольку они должны угадать адресное поле для выборки до того, как будет выполнена текущая инструкция, все конвейерные процессоры тем или иным образом выполняют предсказание ветвления.
Как предсказание ветвления неприменимо в приведенном выше случае?
Условие if проверяет, что arr [i] <5000, но если вы наблюдаете в случае отсортированного массива, после передачи числа 5000 условие всегда ложно, а до этого всегда истинно. ЦП распознает этот шаблон и сможет правильно предсказать, какая инструкция будет выполняться следующей после условного перехода, вместо того, чтобы иногда перематывать назад после неправильного предположения.
Работа алгоритма прогнозирования ветвлений:
Прогнозирование ветвлений работает по шаблону, которому следует алгоритм, или, в основном, по истории, как он выполнялся на предыдущих шагах. Если предположение верное, то ЦП продолжает выполнение, а если что-то пойдет не так, ЦП должен очистить конвейер, откатиться к ветви и перезапустить с начала.
Пример 2. Представьте себе телефонную книгу.
Все имена отсортированы. Ищите в книге «Джонсона». Бьюсь об заклад, это займет у вас меньше 3 минут. Как вы знаете, где находится буква J в алфавите, теперь представьте, что у вас есть те же 60000 имен и телефонных номеров - несортированные в одном типе книги, все перемешано. нет особого приказа, а теперь найди Джонсона в книге. Бьюсь об заклад, это займет у вас несколько часов! Это может быть страница 3 или страница 349; никогда не знаешь где это.
Возможно, вам не стоит сортировать данные, так как диапазон выходных значений ограничен. Гораздо быстрее вычислить, сколько раз встречается каждое значение.
например, у вас есть 20 данных между 0..3, тогда вы можете зарезервировать 3 счетчика. В итоге у вас может получиться:{0: 10x, 1: 8x, 2: 2x}
Чтобы преобразовать этот массив обратно в линейный массив, просто выведите 10x 0, 8x 1, 2x 2.
Если значения не равны 0..2, но все еще ограничены, вы все равно можете рассмотреть этот метод. Сортировка всегда идет медленно! Другое преимущество: это небольшой код, его легко читать и тестировать, в нем меньше ошибок.