Оценка обобщения текста - BLEU против ROUGE
С результатами двух разных систем сводок (sys1 и sys2) и одними и теми же справочными сводками я оценил их как BLEU, так и ROUGE. Проблема в том, что все показатели ROUGE для sys1 были выше, чем для sys2 (ROUGE-1, ROUGE-2, ROUGE-3, ROUGE-4, ROUGE-L, ROUGE-SU4, ...), но показатель BLEU для sys1 был меньше чем оценка BLEU sys2 (довольно много).
Итак, мой вопрос: и ROUGE, и BLEU основаны на n-граммах, чтобы измерить сходство между сводками систем и сводками людей. Так почему же существуют различия в результатах оценки? И в чем главное отличие ROUGE от BLEU для объяснения этой проблемы?
Любые советы и предложения будут с благодарностью! Спасибо!
2 ответа
В общем:
Bleu измеряет точность: сколько слов (и / или n-грамм) в сгенерированных машиной сводках появилось в справочниках человека.
Меры Руж напоминают: сколько слов (и / или н-граммов) в справочных резюме человека появилось в сгенерированных машиной резюме.
Естественно - эти результаты дополняют друг друга, как это часто бывает в случае точности с отзывом. Если у вас много слов из результатов системы, появившихся в человеческих ссылках, у вас будет высокий Bleu, и если у вас будет много слов из ссылок человека, появившихся в системных результатах, у вас будет высокий Руж.
В вашем случае может показаться, что sys1 имеет более высокий Rouge, чем sys2, поскольку в результатах в sys1 постоянно было больше слов из человеческих ссылок, чем в результатах sys2. Однако, поскольку ваш показатель Bleu показал, что sys1 имеет более низкий уровень отзыва, чем sys2, это предполагает, что не так много слов из ваших результатов sys1 появилось в человеческих ссылках в отношении sys2.
Это может произойти, например, если ваш sys1 выводит результаты, которые содержат слова из ссылок (поднимая Руж), но также и много слов, которые ссылки не включали (понижая Bleu). sys2, как кажется, дает результаты, для которых большинство выводимых слов действительно появляется в человеческих ссылках (поднимая Голубой), но также пропускает много слов из своих результатов, которые действительно появляются в человеческих ссылках.
Кстати, есть нечто, называемое штрафом за краткость, что очень важно и уже добавлено в стандартные реализации Bleu. Это наказывает системные результаты, которые короче, чем общая длина ссылки (подробнее об этом здесь). Это дополняет поведение метрики n-граммы, которое в действительности штрафует дольше, чем контрольные результаты, поскольку знаменатель растет, чем дольше результат системы.
Вы также можете реализовать нечто подобное для Rouge, но на этот раз система штрафует результаты, которые длиннее, чем общая эталонная длина, что в противном случае позволило бы им получить искусственно более высокие оценки Rouge (так как чем длиннее результат, тем выше вероятность того, что вы попадете в некоторые слово появляется в ссылках). В Rouge мы делим на длину человеческих ссылок, поэтому нам потребовалось бы дополнительное наказание за более длинные системные результаты, которые могли бы искусственно повысить их оценку Rouge.
Наконец, вы можете использовать меру F1, чтобы метрики работали вместе: F1 = 2 * (Bleu * Rouge) / (Bleu + Rouge)
И ROUGE, и BLEU основаны на n-граммах для измерения сходства между сводками систем и сводками людей. Так почему же существуют различия в результатах оценки? И в чем главное отличие ROUGE от BLEU для объяснения этой проблемы?
Существуют как точность ROUGE-n, так и отзыв точности ROUGE-n. оригинальная реализация ROUGE из статьи, в которой был представлен ROUGE {3}, вычисляет оба, а также итоговый результат F1.
С http://text-analytics101.rxnlp.com/2017/01/how-rouge-works-for-evaluation-of.html ( зеркало):
Руж вспоминает:
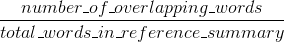
ROUGE точность:
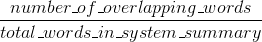
(Исходная реализация ROUGE из статьи, в которой был представлен ROUGE {1}, может выполнять еще несколько вещей, таких как остановка.)
Точность и отзыв ROUGE-n легко интерпретировать, в отличие от BLEU (см. Интерпретация результатов ROUGE).
Разница между точностью ROUGE-n и BLEU заключается в том, что BLEU вводит термин штрафа за краткость, а также вычисляет совпадение n-грамм для нескольких размеров n-грамм (в отличие от ROUGE-n, где есть только один выбранный n-грамм) размер). Переполнение стека не поддерживает LaTeX, поэтому я не буду вдаваться в дополнительные формулы для сравнения с BLEU. {2} четко объясняет BLEU.
Рекомендации:
- {1} Линь, Чин-Тис. "Rouge: пакет для автоматической оценки резюме". В тексте обобщение ветвится: Материалы семинара ACL-04, вып. 8. 2004 г. https://scholar.google.com/scholar?cluster=2397172516759442154&hl=en&as_sdt=0,5; http://anthology.aclweb.org/W/W04/W04-1013.pdf
- {2} Каллисон-Берч, Крис, Майлз Осборн и Филипп Коэн. "Переоценка роли блю в исследованиях машинного перевода". В EACL, вып. 6, с. 249-256. 2006. https://scholar.google.com/scholar?cluster=8900239586727494087&hl=en&as_sdt=0,5;
ROGUE и BLEU представляют собой набор показателей, применимых к задаче создания текстового резюме. Первоначально BLEU был нужен для машинного перевода, но он идеально подходит для задачи сводки текста.
Лучше всего понять концепции на примерах. Во-первых, нам нужно иметь сводного кандидата (сводку, созданную машинным обучением), например:
кот был найден под кроватью
И резюме по золотому стандарту (обычно создается человеком):
кот был под кроватью
Найдем точность и отзыв для случая униграммы (каждого слова). Мы используем слова в качестве показателей.
Сводка по машинному обучению состоит из 7 слов (mlsw=7), сводка по золотому стандарту состоит из 6 слов (gssw=6), а количество перекрывающихся слов снова равно 6 (ow=6).
Отзыв для машинного обучения будет: ow/gssw=6/6=1 Точность машинного обучения будет: ow/mlsw=6/7=0,86.
Точно так же мы можем вычислить точность и вспомнить оценки для сгруппированных униграмм, биграмм, n-грамм...
Мы знаем, что для ROGUE используются как отзыв, так и точность, а также оценка F1, которая является их средним гармоническим.
Для BLEU он также использует точность, сочетающуюся с отзывом, но использует среднее геометрическое и штраф за краткость.
Незначительные различия, но важно отметить, что они оба используют точность и отзыв.