Создание кривой для данных xy, где X является категоричным
У меня есть набор данных о поведении при погружении с помеченными животными, и я изо всех сил стараюсь подогнать кривую к данным, я думаю, главным образом потому, что переменная X в этом случае является категориальной, а не непрерывными данными. Позвольте мне дать немного фона:
Мой набор данных содержит 184 наблюдения 14 переменных:
tagID ddmmyy Hour.GMT.Hour.Local. X0 X3 X10 X20 X50 X100 X150 X200 X300 X400
1 122097 250912 0 9 0.0 0.0 0.3 12.0 15.3 59.6 12.8 0.0 0 0
2 122097 260912 0 9 0.0 2.4 6.9 5.5 13.7 66.5 5.0 0.0 0 0
3 122097 260912 6 15 0.0 1.9 3.6 4.1 12.7 39.3 34.6 3.8 0 0
4 122097 260912 12 21 0.0 0.2 5.5 8.0 18.1 61.4 6.7 0.0 0 0
5 122097 280912 6 15 2.4 9.3 6.0 3.4 7.6 21.1 50.3 0.0 0 0
6 122097 290912 18 3 0.0 0.2 1.6 6.4 41.4 50.4 0.0 0.0 0 0
Переменные, которые меня интересуют: X0:X400, Это контейнеры глубины, и значения представляют процент от общего времени за этот период дня, которое животное провело в этом контейнере глубины. Итак, в первой строке он провел 0% своего времени между 0-3 метрами, 59,6% своего времени между 100-150 метрами и т. Д. Получив небольшую помощь из некоторых ответов на мой последний вопрос здесь о stackru, я вычислил среднее время, проведенное этим животным в% глубины
diving.means <- colMeans(diving[, -(1:4)])
lowerIntervalBound <- gsub("X", "", names(diving)[-(1:4)])
lowInts <- as.numeric(lowerIntervalBound)
plot(x=factor(lowInts), y=diving.means, xlab="Depth Bin (Meters—Lower Bound)", ylab="% Time Spent")
который предоставил мне этот сюжет:
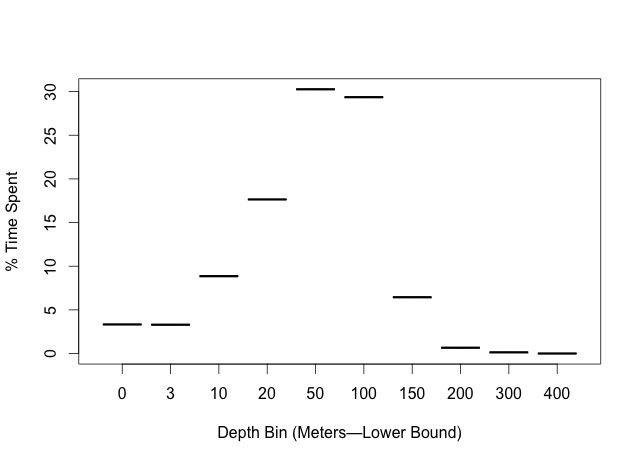
К сожалению, поскольку мои данные являются средними значениями (одно значение), а не частотами, я не мог понять, как отобразить их в виде гистограммы... Это ни здесь, ни там, так как я могу легко просто ввести их как значения и сделать желаемый сюжет в случае необходимости.. но это делает аналитическую хитрость пока.
Теперь у меня есть несколько животных и разные временные корзины, которые я хотел бы сравнить. В конце концов, я разработаю систему для взвешивания времени, проведенного в корзинах, чтобы получить среднюю глубину для статистического сравнения, а сейчас я просто хочу сравнить их визуально, качественно, а также подготовить графики, которые я могу использовать в презентациях и, в конечном итоге, публикации. Я хотел бы создать кривую плотности, представляющую мою "гистограмму", и затем построить эти кривые из нескольких сценариев на одном графике для сравнения. Тем не менее, я не могу заставить эту работу с density() функция, так как у меня нет данных о частоте. Я вроде уже рассчитал плотности, как% времени, потраченного на каждую ячейку... но они не представлены в необработанном формате в моем наборе данных как частоты категорий, из которых я могу затем сделать гистограммы и кривые плотности.
Вот как выглядят мои данные:
> diving.means
X0 X3 X10 X20 X50 X100 X300 X400 X150 X200
3.330978261 3.299456522 8.857608696 17.646195652 30.261413043 29.356521739 6.445108696 0.664130435 0.135869565 0.001630435
или же:
> df<-data.frame(lowInts, diving.means)
> df
lowInts diving.means
X0 0 3.330978261
X3 3 3.299456522
X10 10 8.857608696
X20 20 17.646195652
X50 50 30.261413043
X100 100 29.356521739
X150 150 6.445108696
X200 200 0.664130435
X300 300 0.135869565
X400 400 0.001630435
И то, что я хотел бы создать, - это что-то, что выглядит примерно так (вытащил это случайно из публикации - оси не связаны с моими данными):
а затем сможете выделить кривые и построить их вместе.
Спасибо за любую помощь, вы можете предоставить!
2 ответа
У вас уже есть частоты, так hist не может быть использован. Ты можешь использовать plot со сплайн-интерполяцией по плотности:
df <- read.table(text=" lowInts diving.means
X0 0 3.330978261
X3 3 3.299456522
X10 10 8.857608696
X20 20 17.646195652
X50 50 30.261413043
X100 100 29.356521739
X150 150 6.445108696
X200 200 0.664130435
X300 300 0.135869565
X400 400 0.001630435")
require(splines)
dens <-predict(interpSpline(df[,1], df[,2]))
plot(df[,1], df[,2], type="s", ylim=c(0,40))
lines(dens, col="red",lwd=2)

Я думаю, что функция шага это то, что вы хотите.
Вы могли бы использовать stepfun создать эту функцию.
Я бы работал в длинном формате, а затем вы могли бы создать пошаговые функции для медианы или среднего
# assuming your data is called `diving`
library(data.table)
DTlong <- reshape(data.table(diving), varying = list(5:14), direction = 'long',
times = c(0,3,10,20,50,100,150,200,300,400),
v.names = 'time.spent', timevar = 'hours')
DTsummary <- DTlong[,c(mean.d = mean(time.spent),
setattr(as.list(fivenum(time.spent)), 'names',c('min','lhinge','median','uhinge','max'))),
by=list(hours, midhours, upperhours)]
Base R step fun
f.median <- DTsummary[, stepfun(hours, c(0,median))]
f.uhinge <- DTsummary[, stepfun(hours, c(0,uhinge))]
f.lhinge <- DTsummary[, stepfun(hours, c(0,lhinge))]
plot(f.median, main = 'median time spent', xlim = c(0,500), do.points = FALSE)

используя ggplot2
ggplot(DTsummary, aes(x = hours)) + geom_step(aes(y = median))
