Как построить график, чтобы описать характеристики плотности набора данных?
У меня есть наборы данных, которые состоят из 263 пользователей. Он имеет следующую структуру фрейма данных:
userID bookmarkID tagID value
1 52 101 1
1 114 154 1
2 127 14 1
4 114 4 1
Для каждого пользователя я вычисляю значение переменной, представляющей частоту, по следующему уравнению: count() / (количество bookmarkIDs * количество tagIDs). Я получил эти значения: числа от 1 до 265 - это просто идентификаторы пользователей, а пользователи не заказано.
1 2 3 4 5 6
0.0003716331 0.0005655286 0.0001777376 0.0003070012 0.0019389552 0.0002746853
...
...
259 260 261 262 263 264
0.0003393172 0.0006463184 0.0002100535 0.0002100535 0.0001777376 0.0004685808
265
0.0001777376
Используя следующие R коды:
#each user: number of tensor elements which >0 / (num of tags* number of items)
d.file <-
"E:/My_Projects/Bitbucket/TylerRecommender/src/test/resources/DAI_LAbor/p-core of level 12/dataFilePathBeforeTensorDecompositionForTraining80percent.txt"
df<-read.table(d.file,sep="\t",header=T)
itemsize<-length(unique(df$bookmarkID))
tagsize<-length(unique(df$tagID))
itemtagmatrixsize<-itemsize*tagsize
userid.bag<-df$userID
user.tas.count<-table(userid.bag)
dens.tas<-density(user.tas.count/itemtagmatrixsize)
plot(dens.tas, col="red")
d.file2 <-
"E:/My_Projects/Bitbucket/TylerRecommender/src/test/resources/DAI_LAbor/p-core of level 12/~sample_tensor_afterDecomposition_Condensed.example.txt"
df2<-read.table(d.file2,sep="\t",header=T)
lines(density(table(df2$userID)/itemtagmatrixsize), col="blue")
Теперь моя проблема в том, как я могу построить график, чтобы лучше описать распределение частот пользователей?
Я использую функцию оценки плотности ядра () в R, чтобы построить распределение вероятностей значений частоты. (Является ли эта встреча моей целью?)
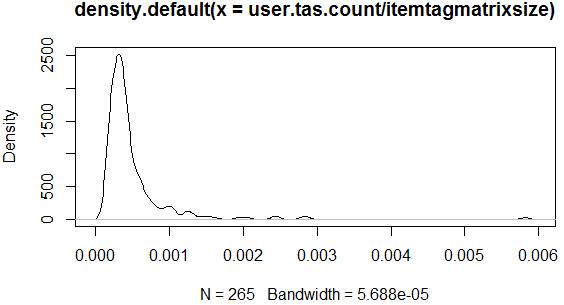
Однако у меня есть другой набор данных, который имеет гораздо более высокие значения частоты, чем предыдущий (синий) на следующем графике, в котором красная линия связана с предыдущим набором данных: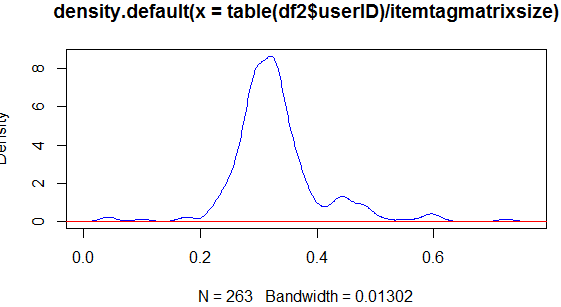
Но красная линия для первого набора данных стала абсолютно плоской, что не имеет смысла. Это почему? Это из-за выбранной по умолчанию пропускной способности? Можно ли построить их на одном графике и сделать их нормальными? Спасибо!