OverflowError, поскольку я пытаюсь использовать алгоритм итерации значения с mdptoolbox
Я установил простое MDP для платы, которая имеет 4 возможных состояния и 4 возможных действия. Настройка доски и вознаграждения выглядит следующим образом:
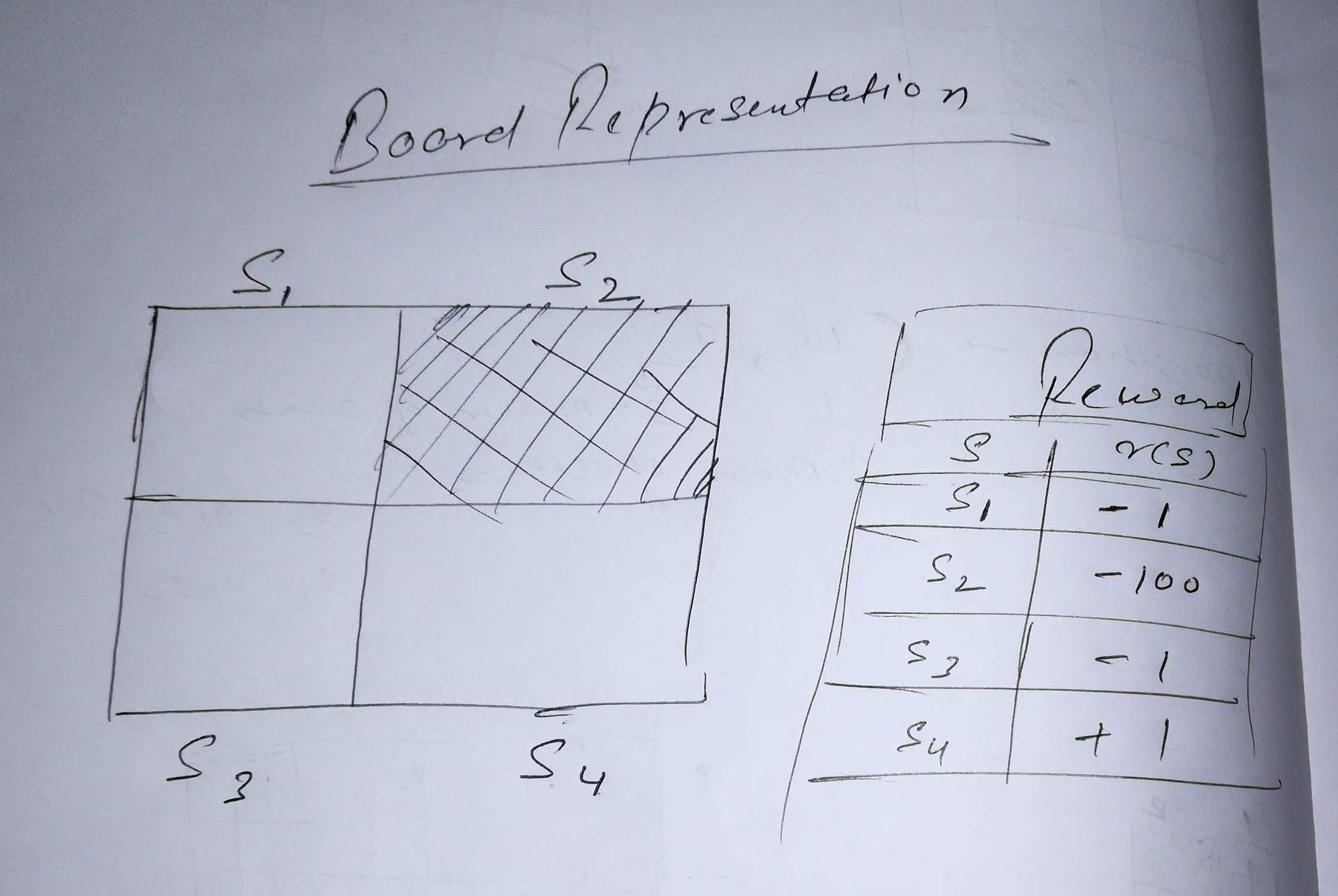
Вот S4 является целевым состоянием и S2 это поглощающее состояние. Я определил матрицы вероятности перехода и матрицу вознаграждения в коде, который я написал, чтобы получить функцию оптимального значения для этого MDP. Но когда я запускаю код, я получаю сообщение об ошибке: OverflowError: cannot convert float infinity to integer, Я не мог понять причину этого.
import mdptoolbox
import numpy as np
transitions = np.array([
# action 1 (Right)
[
[0.1, 0.7, 0.1, 0.1],
[0.3, 0.3, 0.3, 0.1],
[0.1, 0.2, 0.2, 0.5],
[0.1, 0.1, 0.1, 0.7]
],
# action 2 (Down)
[
[0.1, 0.4, 0.4, 0.1],
[0.3, 0.3, 0.3, 0.1],
[0.4, 0.1, 0.4, 0.1],
[0.1, 0.1, 0.1, 0.7]
],
# action 3 (Left)
[
[0.4, 0.3, 0.2, 0.1],
[0.2, 0.2, 0.4, 0.2],
[0.5, 0.1, 0.3, 0.1],
[0.1, 0.1, 0.1, 0.7]
],
# action 4 (Top)
[
[0.1, 0.4, 0.4, 0.1],
[0.3, 0.3, 0.3, 0.1],
[0.4, 0.1, 0.4, 0.1],
[0.1, 0.1, 0.1, 0.7]
]
])
rewards = np.array([
[-1, -100, -1, 1],
[-1, -100, -1, 1],
[-1, -100, -1, 1],
[1, 1, 1, 1]
])
vi = mdptoolbox.mdp.ValueIteration(transitions, rewards, discount=0.5)
vi.setVerbose()
vi.run()
print("Value function:")
print(vi.V)
print("Policy function")
print(vi.policy)
Если я изменю значение discount в 1 от 0.5 работает нормально. Что может быть причиной того, что итерация значения не работает со значением скидки 0.5 или любые другие десятичные значения?
Обновление: похоже, что есть какая-то проблема с моей матрицей вознаграждений. Я не смог написать это так, как задумал. Потому что, если я изменю некоторые значения в матрице наград, ошибка исчезнет.
1 ответ
Так что оказалось, что матрица вознаграждений, которую я определил, была неверной. В соответствии с матрицей вознаграждения, определенной на рисунке выше, она должна быть (S,A) как указано в документации, где каждая строка соответствует состоянию, начиная с S1 до тех пор S4 и каждый столбец соответствует действию, начиная с A1 до тех пор A4, Новая награда Матриса выглядит следующим образом:
#(S,A)
rewards = np.array([
[-1, -1, -1, -1],
[-100, -100, -100, -100],
[-1, -1, -1, -1],
[1, 1, 1, 1]
])
Это прекрасно работает с этим. Но я все еще не уверен, что происходило внутри, что привело к ошибке переполнения.