Зачем кому-то использовать set вместо unordered_set?
C++0x представляет unordered_set который доступен в boost и много других мест. Я понимаю, что unordered_set хэш-таблица с O(1) сложность поиска. С другой стороны, set это не что иное, как дерево с log(n) сложность поиска. Зачем кому-то использовать set вместо unordered_set ? т.е. есть ли необходимость в set больше?
14 ответов
Когда для кого-то, кто хочет перебрать элементы набора, порядок имеет значение.
Неупорядоченные наборы должны платить за среднее время доступа O(1) несколькими способами:
setиспользует меньше памяти, чемunordered_setхранить одинаковое количество элементов.- Для небольшого количества элементов, поиск в
setможет быть быстрее, чем поиск вunordered_set, - Хотя многие операции выполняются быстрее в среднем
unordered_setони часто гарантированно имеют лучшие сложности в худшем случае дляset(напримерinsert). - Тот
setСортировка элементов полезна, если вы хотите получить к ним доступ по порядку. - Можно лексикографически сравнивать разные
setс<,<=,>а также>=,unordered_setНе требуется поддерживать эти операции.
Всякий раз, когда вы предпочитаете дерево хеш-таблице.
Например, в худшем случае хеш-таблицы имеют значение "O(n)". O(1) - средний случай. Деревья в худшем случае "O (log n)".
Используйте набор, когда:
- Нам нужны упорядоченные данные (отдельные элементы).
- Мы должны были бы распечатать / получить доступ к данным (в отсортированном порядке).
- Нам нужен предшественник / преемник элементов.
Используйте unordered_set, когда:
- Нам нужно сохранить набор отдельных элементов, и упорядочение не требуется.
- Нам нужен доступ с одним элементом, то есть без обхода.
Примеры:
задавать:
Вход: 1, 8, 2, 5, 3, 9
Выход: 1, 2, 3, 5, 8, 9
Unordered_set:
Вход: 1, 8, 2, 5, 3, 9
Вывод: 9 3 1 8 2 5 (возможно, этот порядок зависит от хеш-функции)
Главное отличие:

Примечание:(в некоторых случаях set удобнее) например с помощью vector как ключ
set<vector<int>> s;
s.insert({1, 2});
s.insert({1, 3});
s.insert({1, 2});
for(const auto& vec:s)
cout<<vec<<endl; // I have override << for vector
// 1 2
// 1 3
Причина по которой vector<int> может быть в качестве ключа set так как vector переопределение operator<,
Но если вы используете unordered_set<vector<int>> Вы должны создать хеш-функцию для vector<int>, потому что вектор не имеет хэш-функции, поэтому вы должны определить одну из них:
struct VectorHash {
size_t operator()(const std::vector<int>& v) const {
std::hash<int> hasher;
size_t seed = 0;
for (int i : v) {
seed ^= hasher(i) + 0x9e3779b9 + (seed<<6) + (seed>>2);
}
return seed;
}
};
vector<vector<int>> two(){
//unordered_set<vector<int>> s; // error vector<int> doesn't have hash function
unordered_set<vector<int>, VectorHash> s;
s.insert({1, 2});
s.insert({1, 3});
s.insert({1, 2});
for(const auto& vec:s)
cout<<vec<<endl;
// 1 2
// 1 3
}
Вы можете видеть это в некоторых случаях unordered_set сложнее.
В основном цитируется с: https://www.geeksforgeeks.org/set-vs-unordered_set-c-stl/ /questions/23828724/c-unorderedset-vektorov/23828728#23828728
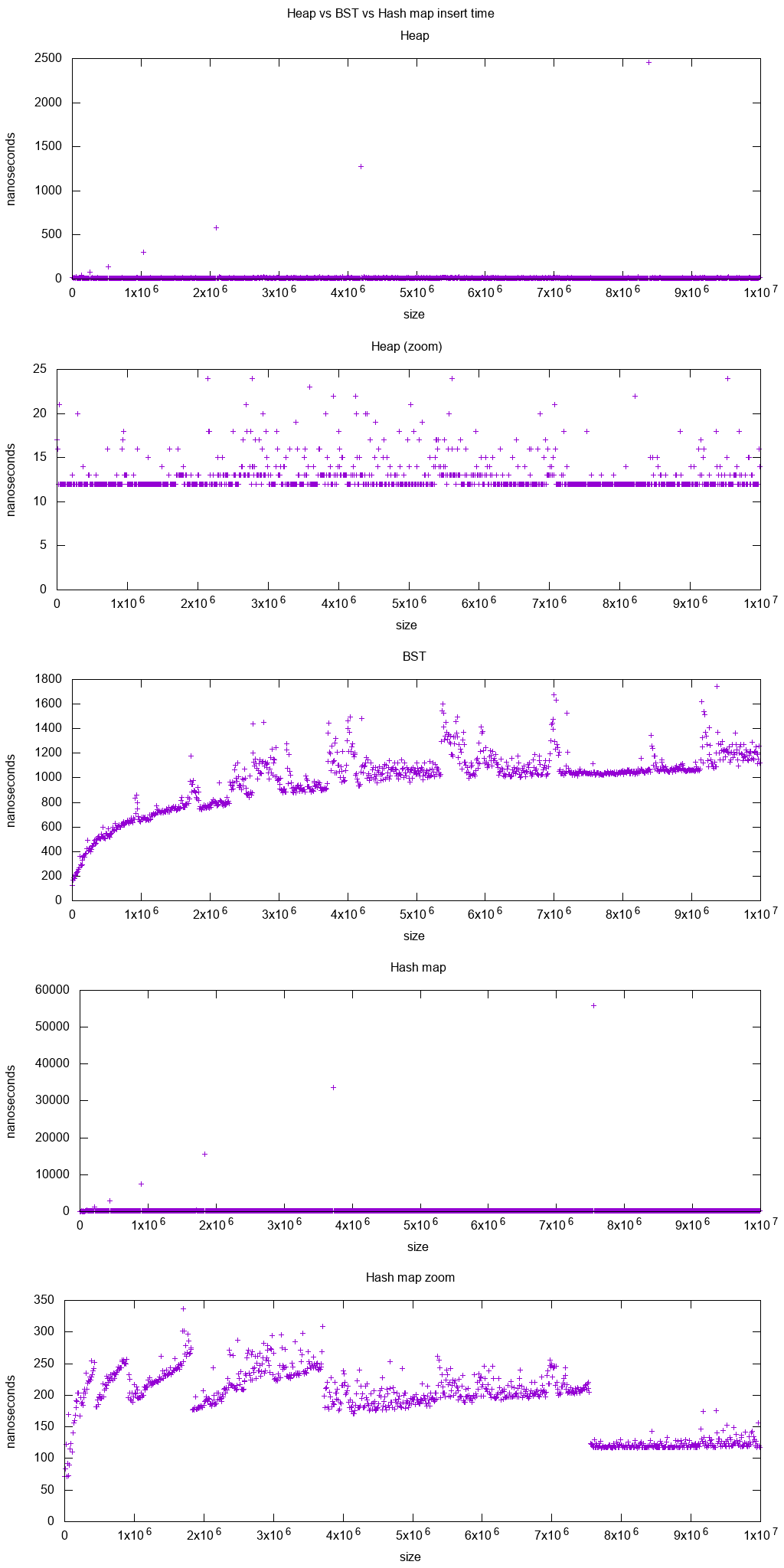
g++6.4 stdlibC++ упорядоченный и неупорядоченный набор тестов
Я проверил эту доминирующую реализацию Linux C++, чтобы увидеть разницу.
Полная информация о тестировании и анализ были даны на: Какова основная структура данных набора STL в C++? и я не буду повторять их здесь.
Как краткое резюме:
график ясно показывает, что в этих условиях вставка хэш-карты всегда выполнялась намного быстрее, когда в ней более 100 тыс. элементов, и разница увеличивается с увеличением количества элементов.
Стоимость этого повышения скорости заключается в том, что вы не можете эффективно перемещаться по порядку.
кривые ясно показывают, что упорядочены
std::setна основе BST иstd::unordered_setосновано на hashmap. В справочном ответе я также подтвердил, что с помощью GDB пошагово отлаживаем код.
Результаты показаны ниже. "BST" означает "протестирован с std::set и "карта хеша" означает "проверено с std::unordered_set, "Куча" предназначена для std::priority_queue который я проанализировал в: куча против дерева двоичного поиска (BST)
Подобный вопрос для map против unordered_map: Есть ли преимущество использования map перед unordered_map в случае тривиальных ключей?
Хотя этот ответ может быть запоздалым на 10 лет, стоит отметить, что std::unordered_set также имеет недостатки безопасности.
Если хеш-функция предсказуема (обычно это так, если она не применяет контрмеры, такие как рандомизированная соль), злоумышленники могут вручную обрабатывать данные, которые вызывают коллизии хешей и заставляют все вставки и поиски занимать время O(n).
Это можно использовать для очень эффективных и элегантных атак типа "отказ в обслуживании".
Многие (большинство?) Реализации языков, которые используют хэш-карты внутри компании, столкнулись с этим:
Потому что std::set является частью стандарта C++, а unordered_set - нет. C++0x НЕ является стандартом и не является Boost. Для многих из нас мобильность важна, и это означает, что нужно придерживаться стандарта.
Извините, еще одна вещь, которую стоит отметить в отсортированном объекте:
Если вы хотите диапазон данных в контейнере, например: вы сохранили время в наборе, и вы хотите время с 2013-01-01 по 2014-01-01.
Для unordered_set это невозможно.
Конечно, этот пример будет более убедительным для случаев использования между map и unordered_map.
Рассмотрим алгоритмы стреловидности. Эти алгоритмы полностью потерпят неудачу с хеш-таблицами, но прекрасно работают со сбалансированными деревьями. Чтобы дать вам конкретный пример алгоритма разметки, рассмотрим алгоритм Fortune. http://en.wikipedia.org/wiki/Fortune%27s_algorithm
Еще одна вещь, в дополнение к тому, что уже упоминали другие люди. В то время как ожидаемая амортизируемая сложность для вставки элемента в unordered_set равна O(1), время от времени потребуется O(n), потому что хеш-таблицу необходимо реструктурировать (нужно изменить количество сегментов) - даже при "хорошая" хеш-функция. Точно так же, как вставка элемента в вектор время от времени требует O(n), потому что базовый массив должен быть перераспределен.
Вставка в набор всегда занимает не более O(log n). Это может быть предпочтительнее в некоторых приложениях.
Я бы сказал, что удобно иметь отношения в отношениях, если вы хотите преобразовать их в другой формат.
Также возможно, что хотя доступ к нему происходит быстрее, время для создания индекса или памяти, используемой при его создании и / или доступе к нему, больше.
Вот практическая причина, которую я не видел в списке ... при неправильном использовании в ошибочном коде неупорядоченные наборы могут привести к тому, что код будет вести себя по-разному на разных машинах. Это связано с тем, что порядок, в котором значения хранятся, не согласован на разных машинах.
Если (неправильно) написан код, основанный на порядке хранения, результатом будет то, что программа будет вести себя непоследовательно на разных машинах. На практике это может произойти, если неупорядоченный набор является частью реализации функции / метода, возвращающего список значений. Клиент этой функции может не осознавать, что используется неупорядоченный набор, и может не осознавать, что порядок возвращенного списка не гарантированно будет согласованным / переносимым.
Таким образом, неупорядоченные множества более неумолимы для программиста, чем упорядоченные. Они вводят этот дополнительный механизм для запутывания поведения кода, что может привести к отнимающим много времени / сбивающим с толку ошибкам, поскольку они могут не воспроизводиться на разных машинах.
Если вы хотите, чтобы вещи сортировались, вы бы использовали set вместо unordered_set. unordered_set используется сверх установленного, когда сохраненный порядок не имеет значения.
Помимо порядка и производительности, есть еще одна причина использовать set, а не неупорядоченный набор: set можно использовать для построения «набора кортежей» при реализации сложных структур данных, но неупорядоченный набор этого не поддерживает.