Есть ли преимущество использования map перед unordered_map в случае тривиальных ключей?
Недавний разговор о unordered_map в C++ заставил меня понять, что я должен использовать unordered_map для большинства случаев, когда я использовал map раньше, из-за эффективности поиска (амортизированный O(1) против O (log n)). В большинстве случаев я использую карту, которую я использую либо intили std::strings как ключи, поэтому у меня нет проблем с определением хеш-функции. Чем больше я думал об этом, тем больше осознавал, что не могу найти причину использования std::map в случае простых типов над unordered_map - Я посмотрел на интерфейсы и не обнаружил каких-либо существенных различий, которые могли бы повлиять на мой код.
Отсюда вопрос - есть ли реальная причина использовать std::map над unordered map в случае простых типов, таких как int а также std::string?
Я спрашиваю со строгой точки зрения программирования - я знаю, что это не полностью считается стандартом, и что это может создать проблемы с портированием.
Также я ожидаю, что один из правильных ответов может быть "он более эффективен для небольших наборов данных" из-за меньших издержек (это правда?) - поэтому я бы хотел ограничить вопрос случаями, когда количество ключей нетривиален (>1 024).
Изменить: да , я забыл очевидное (спасибо GMan!) - да, карты, конечно, упорядочены - я знаю это, и ищу по другим причинам.
15 ответов
Не забывайте mapДержите свои элементы в порядке. Если вы не можете отказаться от этого, очевидно, вы не можете использовать unordered_map,
Что еще нужно иметь в виду, что unordered_mapОбычно используют больше памяти. map просто есть несколько указателей на ведение домашнего хозяйства, а затем память для каждого объекта. Наоборот, unordered_mapимеет большой массив (в некоторых реализациях он может быть довольно большим), а затем дополнительную память для каждого объекта. Если вам нужно учитывать память, map лучше доказать, потому что ему не хватает большого массива.
Итак, если вам нужен чистый поиск-поиск, я бы сказал, unordered_map это путь Но всегда есть компромиссы, и если вы не можете их себе позволить, то вы не можете их использовать.
Только из личного опыта я обнаружил огромное улучшение производительности (измеряемой, конечно) при использовании unordered_map вместо map в таблице поиска основного объекта.
С другой стороны, я обнаружил, что при многократном вставлении и удалении элементов было намного медленнее. Это отлично подходит для относительно статичной коллекции элементов, но если вы делаете тонны вставок и удалений, хэширование + сегментирование, похоже, складываются. (Обратите внимание, это было в течение многих итераций.)
Если вы хотите сравнить скорость вашего std::map а также std::unordered_map реализации, вы могли бы использовать проект sparsehash от Google, который имеет программу time_hash_map для их синхронизации. Например, с gcc 4.4.2 в системе Linux x86_64
$ ./time_hash_map
TR1 UNORDERED_MAP (4 byte objects, 10000000 iterations):
map_grow 126.1 ns (27427396 hashes, 40000000 copies) 290.9 MB
map_predict/grow 67.4 ns (10000000 hashes, 40000000 copies) 232.8 MB
map_replace 22.3 ns (37427396 hashes, 40000000 copies)
map_fetch 16.3 ns (37427396 hashes, 40000000 copies)
map_fetch_empty 9.8 ns (10000000 hashes, 0 copies)
map_remove 49.1 ns (37427396 hashes, 40000000 copies)
map_toggle 86.1 ns (20000000 hashes, 40000000 copies)
STANDARD MAP (4 byte objects, 10000000 iterations):
map_grow 225.3 ns ( 0 hashes, 20000000 copies) 462.4 MB
map_predict/grow 225.1 ns ( 0 hashes, 20000000 copies) 462.6 MB
map_replace 151.2 ns ( 0 hashes, 20000000 copies)
map_fetch 156.0 ns ( 0 hashes, 20000000 copies)
map_fetch_empty 1.4 ns ( 0 hashes, 0 copies)
map_remove 141.0 ns ( 0 hashes, 20000000 copies)
map_toggle 67.3 ns ( 0 hashes, 20000000 copies)
Я бы повторил примерно ту же мысль, которую сделал GMan: в зависимости от типа использования, std::map может быть (и часто) быстрее, чем std::tr1::unordered_map (используя реализацию, включенную в VS 2008 SP1).
Есть несколько усложняющих факторов, которые нужно иметь в виду. Например, в std::map, вы сравниваете ключи, что означает, что вы только когда-либо просматриваете достаточно начала ключа, чтобы различать правую и левую ветви дерева. По моему опыту, почти единственный раз, когда вы смотрите на весь ключ, это если вы используете что-то вроде int, которое вы можете сравнить в одной инструкции. С более типичным типом ключа, таким как std::string, вы часто сравниваете только несколько символов или около того.
Приличная хеш-функция, напротив, всегда смотрит на весь ключ. Таким образом, даже если поиск в таблице имеет постоянную сложность, сам хеш имеет примерно линейную сложность (хотя по длине ключа, а не по количеству элементов). С длинными струнами в качестве ключей, std::map может закончить поиск до unordered_map даже начал бы свой поиск.
Во-вторых, хотя есть несколько методов изменения размера хеш-таблиц, большинство из них довольно медленные - до такой степени, что если поиск не происходит значительно чаще, чем вставки и удаления, std::map часто будет быстрее, чем std::unordered_map,
Конечно, как я уже упоминал в комментарии к вашему предыдущему вопросу, вы также можете использовать таблицу деревьев. Это имеет как преимущества, так и недостатки. С одной стороны, он ограничивает наихудший случай деревом. Это также позволяет быстро вставлять и удалять, потому что (по крайней мере, когда я это сделал) я использовал таблицу фиксированного размера. Исключение всех размеров таблицы позволяет вам сохранять хэш-таблицу намного проще и, как правило, быстрее.
Еще один момент: требования к хешированию и древовидным картам разные. Хеширование, очевидно, требует хеш-функции и сравнения на равенство, где упорядоченные карты требуют сравнения меньше, чем. Конечно, гибрид, о котором я говорил, требует и того, и другого. Конечно, для обычного случая использования строки в качестве ключа это на самом деле не проблема, но некоторые типы ключей лучше упорядочивают, чем хэшируют (или наоборот).
Я был заинтригован ответом @Jerry Coffin, который предположил, что упорядоченная карта будет демонстрировать увеличение производительности на длинных строках, после некоторого эксперимента (который можно загрузить из pastebin), я обнаружил, что это, похоже, справедливо только для коллекций случайных строк, когда карта инициализируется с помощью отсортированного словаря (который содержит слова со значительным количеством префиксов с перекрытием), это правило нарушается, предположительно из-за увеличенной глубины дерева, необходимой для получения значения. Результаты показаны ниже, 1-й числовой столбец - время вставки, 2-й - время выборки.
g++ -g -O3 --std=c++0x -c -o stdtests.o stdtests.cpp
g++ -o stdtests stdtests.o
gmurphy@interloper:HashTests$ ./stdtests
# 1st number column is insert time, 2nd is fetch time
** Integer Keys **
unordered: 137 15
ordered: 168 81
** Random String Keys **
unordered: 55 50
ordered: 33 31
** Real Words Keys **
unordered: 278 76
ordered: 516 298
Существенные различия, которые не были должным образом упомянуты здесь:
mapсохраняет итераторы для всех элементов стабильными, в C++17 вы даже можете перемещать элементы из одногоmapс другой, без признания недействительными итераторов к ним (и при правильной реализации без какого-либо потенциального распределения).mapсроки для отдельных операций, как правило, более согласованы, поскольку они никогда не требуют больших выделений.unordered_mapс помощьюstd::hashкак реализовано в libstdC++, уязвимо для DoS, если подается с ненадежным вводом (он использует MurmurHash2 с постоянным начальным числом - не то, чтобы начальное заполнение действительно помогло, см. https://emboss.github.io/blog/2012/12/14/breaking-murmur-hash-flooding-dos-reloaded/).- Упорядочение обеспечивает эффективный поиск по диапазону, например, перебирает все элементы с ключом>= 42.
В большинстве языков неупорядоченная карта (словари, основанные на хэше) являются картой по умолчанию, однако в C++ вы получаете упорядоченную карту в качестве карты по умолчанию. Как это случилось? Некоторые люди ошибочно полагают, что комитет C++ принял это решение в своей уникальной мудрости, но правда, к сожалению, более ужасна.
Широко распространено мнение, что в C++ по умолчанию используется упорядоченная карта, поскольку параметров их реализации не так уж много. С другой стороны, реализациям на основе хешей есть о чем поговорить. Таким образом, чтобы избежать тупиков в стандартизации, они просто ладили с упорядоченной картой. Приблизительно в 2005 году многие языки уже имели хорошие реализации реализации на основе хеша, поэтому комитету было легче принимать новые std::unordered_map, В идеальном мире std::map было бы неупорядоченным, и мы бы std::ordered_map как отдельный тип.
Ниже два графика должны говорить сами за себя ( источник):
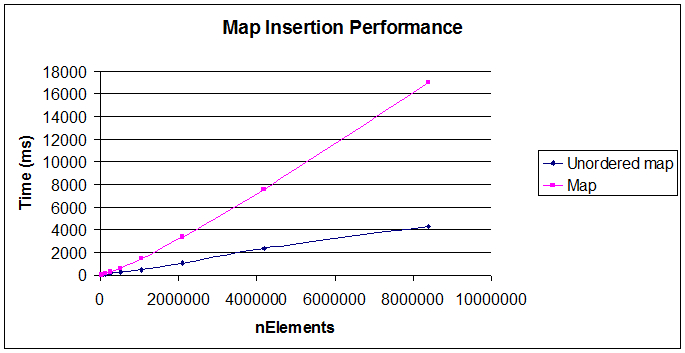
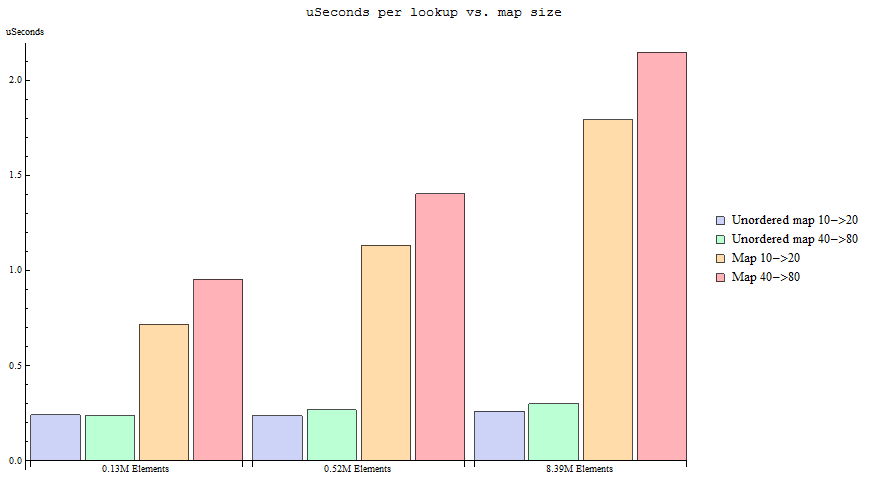
Резюме
Предполагая, что заказ не важен:
- Если вы собираетесь создать большую таблицу один раз и выполнять много запросов, используйте
std::unordered_map - Если вы собираетесь создать небольшую таблицу (может содержать менее 100 элементов) и выполнять множество запросов, используйте
std::map, Это потому, что читает на немO(log n), - Если вы собираетесь много менять таблицу, возможно,
std::mapхороший вариант. - Если вы сомневаетесь, просто используйте
std::unordered_map,
Я хотел бы просто отметить, что... есть много видов unordered_map s.
Посмотрите статью в Википедии на хэш-карте. В зависимости от того, какая реализация была использована, характеристики с точки зрения поиска, вставки и удаления могут значительно отличаться.
И это то, что беспокоит меня больше всего с добавлением unordered_map в STL: им придется выбирать конкретную реализацию, так как я сомневаюсь, что они пойдут вниз Policy дорога, и поэтому мы застряли с реализацией для среднего использования и ничего для других случаев...
Например, некоторые хеш-карты имеют линейную перефразировку, где вместо перефразирования всей хеш-карты за раз, часть перефразируется при каждой вставке, что помогает амортизировать стоимость.
Другой пример: некоторые хеш-карты используют простой список узлов для корзины, другие используют карту, другие не используют узлы, но находят ближайший слот, и, наконец, некоторые используют список узлов, но переупорядочивают его так, чтобы последний доступный элемент находится на фронте (как кеширование).
Так что на данный момент я предпочитаю std::map или возможно loki::AssocVector (для замороженных наборов данных).
Не поймите меня неправильно, я бы хотел использовать std::unordered_map и я могу в будущем, но трудно "доверять" переносимости такого контейнера, когда вы думаете обо всех способах его реализации и различных результатах, которые в результате этого.
Я думаю, что на этот вопрос частично дан ответ, поскольку не было предоставлено никакой информации о производительности с типами int в качестве ключей. Я провел собственный анализ и обнаружил, что std :: map может превзойти (по скорости) std :: unordered_map во многих практических ситуациях при использовании целых чисел в качестве ключей.
Целочисленный тест
Сценарий тестирования состоял в заполнении карт последовательными и случайными ключами и значениями строк с длинами в диапазоне [17:119], кратными 17. Тесты выполнялись с количеством элементов в диапазоне [10:100000000] в степени 10. .
Labels:
Map64: std::map<uint64_t,std::string>
Map32: std::map<uint32_t,std::string>
uMap64: std::unordered_map<uint64_t,std::string>
uMap32: std::unordered_map<uint32_t,std::string>
Вставка
Labels:
Sequencial Key Insert: maps were constructed with keys in the range [0-ElementCount]
Random Key Insert: maps were constructed with random keys in the full range of the type
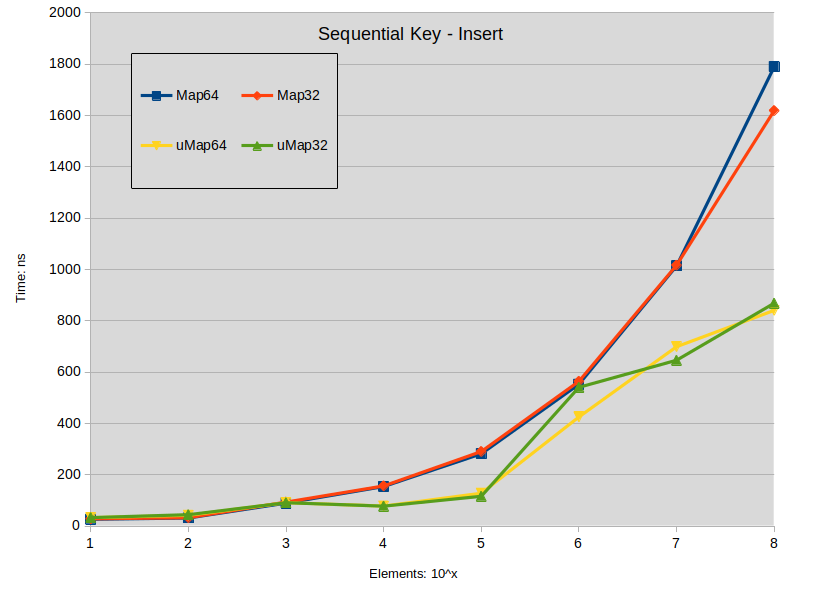
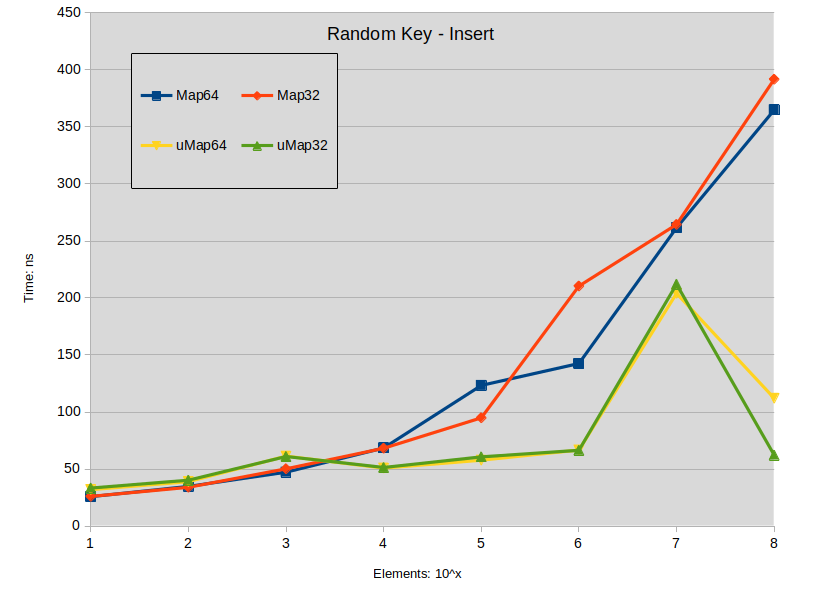
Вывод по прошивке :
- Вставка ключей распространения в std :: map имеет тенденцию превосходить std :: unordered_map, когда размер карты меньше 10000 элементов.
- Вставка плотных ключей в std :: map не приводит к разнице в производительности с std :: unordered_map менее 1000 элементов.
- Во всех остальных случаях std :: unordered_map работает быстрее.
Погляди
Labels:
Sequential Key - Seq. Search: Search is performed in the dense map (keys are sequential). All searched keys exists in the map.
Random Key - Rand. Search: Search is performed in the sparse map (keys are random). All searched keys exists in the map.
(label names can be miss leading, sorry about that)
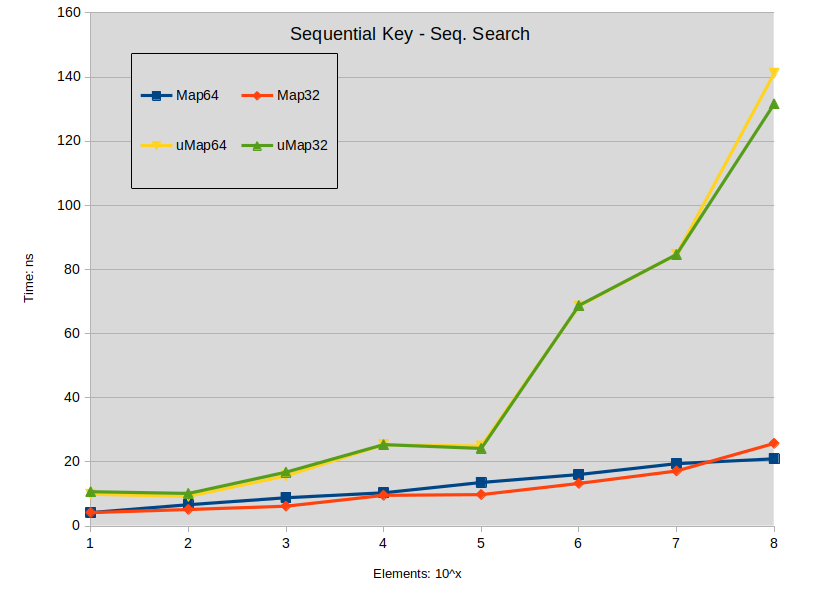
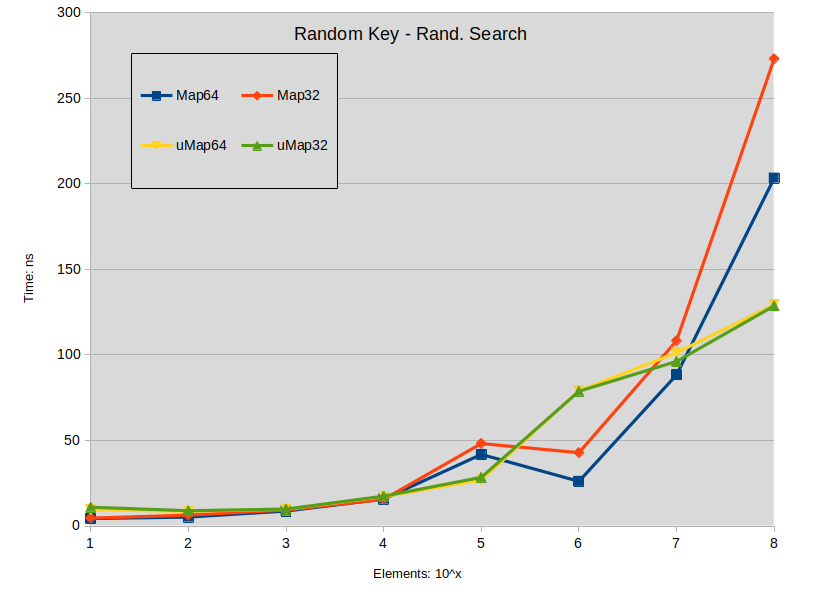
Заключение по поиску :
- Поиск по расширению std :: map имеет тенденцию немного превосходить std :: unordered_map, когда размер карты меньше 1000000 элементов.
- Поиск по плотному std :: map превосходит std :: unordered_map
Не удалось найти
Labels:
Sequential Key - Rand. Search: Search is performed in the dense map. Most keys do not exists in the map.
Random Key - Seq. Search: Search is performed in the sparse map. Most keys do not exists in the map.
(label names can be miss leading, sorry about that)
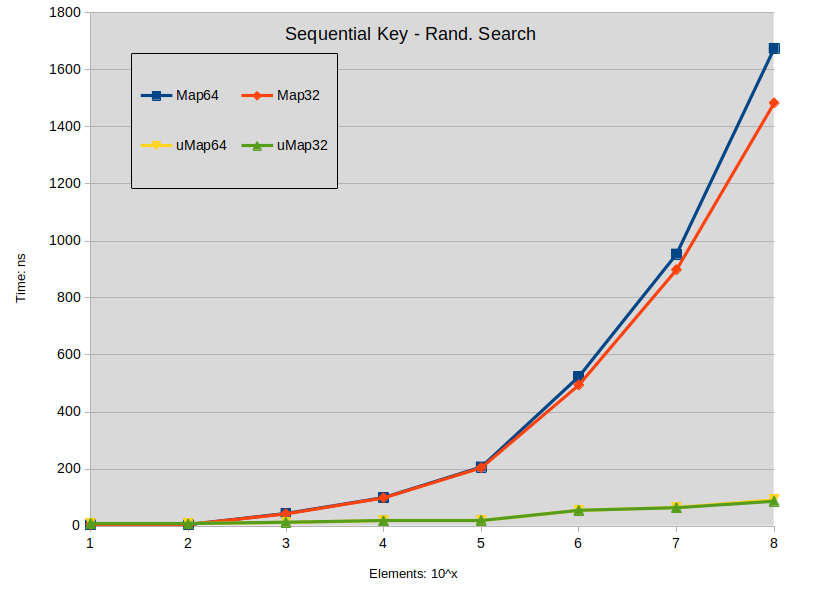
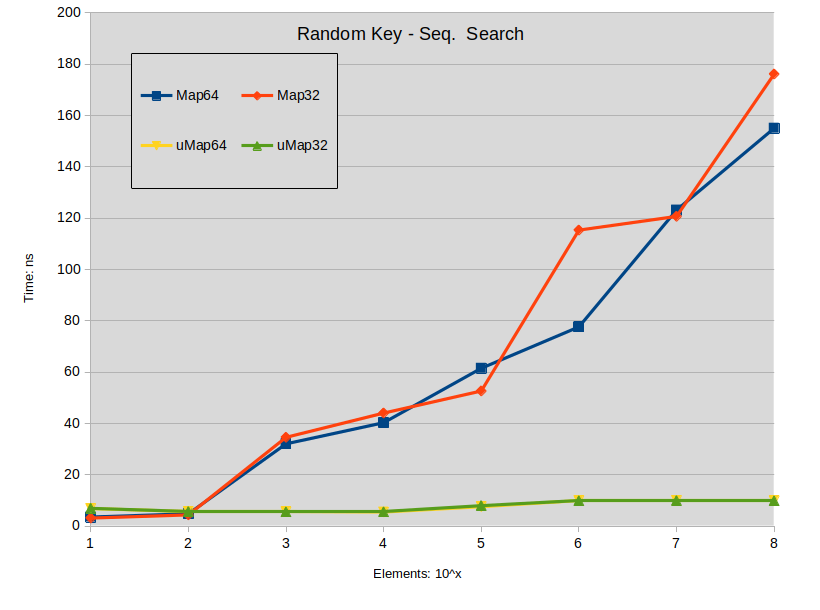
Заключение о неудачном поиске :
- Промах при поиске оказывает большое влияние на std :: map.
Общий вывод
Даже когда требуется скорость, std :: map для целочисленных ключей по-прежнему может быть лучшим вариантом во многих ситуациях. В качестве практического примера у меня есть словарь, в котором поиск никогда не завершается неудачно, и, хотя ключи имеют разреженное распределение, он будет работать хуже с той же скоростью, что и std :: unordered_map, поскольку количество моих элементов меньше 1 КБ. И объем памяти значительно меньше.
Строковый тест
Для справки я представляю здесь тайминги для строковых [строковых] карт. Строки ключей формируются из случайного значения uint64_t. Строки значений такие же, как и в других тестах.
Labels:
MapString: std::map<std::string,std::string>
uMapString: std::unordered_map<std::string,std::string>
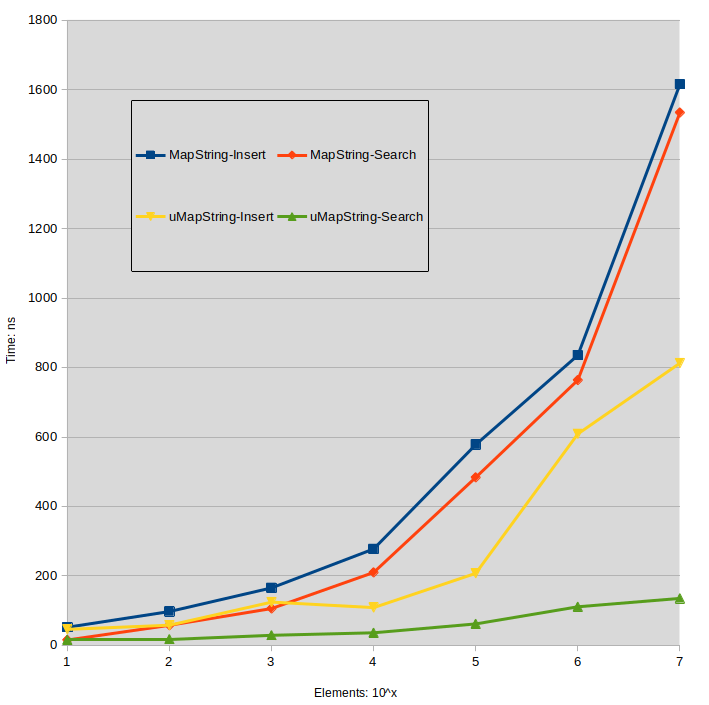
Платформа оценки
ОС: Linux - OpenSuse Tumbleweed
Компилятор: g ++ (SUSE Linux) 11.2.1 20210816
Процессор: Intel (R) Core (TM) i9-9900 CPU @ 3,10 ГГц
Оперативная память: 64 ГБ
Причины были приведены в других ответах; здесь другое.
Операции std:: map (сбалансированное двоичное дерево) амортизируются O(log n) и наихудшим O(log n). Операции std::unordered_map (hash table) амортизируются O(1) и наихудшим O(n).
На практике это проявляется в том, что хэш-таблица "икает" время от времени с помощью операции O (n), что может или не может быть тем, что ваше приложение может терпеть. Если он не может это терпеть, вы бы предпочли std:: map вместо std:: unordered_map.
Хеш-таблицы имеют более высокие константы, чем обычные реализации карт, которые становятся значимыми для небольших контейнеров. Максимальный размер составляет 10, 100, а может, даже 1000 или больше? Константы такие же, как и всегда, но O(log n) близко к O(k). (Помните, логарифмическая сложность все еще действительно хороша.)
Что делает хорошую хеш-функцию зависит от характеристик ваших данных; поэтому, если я не планирую смотреть на пользовательскую хеш-функцию (но, конечно, могу передумать позже, и легко, так как я набираю чертовски близко ко всему), и даже если для многих источников данных выбраны значения по умолчанию, я нахожу упорядоченные природа карты, чтобы быть достаточно помощи изначально, что я все еще по умолчанию для отображения, а не хэш-таблицы в этом случае.
Кроме того, вам не нужно даже думать о написании хеш-функции для других (обычно UDT) типов, а просто написать op<(что вы в любом случае хотите).
Недавно я сделал тест, который делает 50000 слияния и сортировки. Это означает, что если строковые ключи совпадают, объедините байтовую строку. И окончательный вывод должен быть отсортирован. Так что это включает поиск каждой вставки.
Для map Реализация требует 200 мс, чтобы закончить работу. Для unordered_map + mapтребуется 70 мс для unordered_map вставка и 80 мс для map вставки. Таким образом, гибридная реализация на 50 мс быстрее.
Мы должны дважды подумать, прежде чем использовать map, Если вам нужно только отсортировать данные в конечном результате вашей программы, лучше использовать гибридное решение.
Небольшое дополнение ко всему вышеперечисленному:
Лучше использовать mapкогда вам нужно получить элементы по диапазону, так как они отсортированы, и вы можете просто перебирать их от одной границы к другой.
если компилируете проект с помощью Visual Studio 2010 - забудьте про unordered_map для строк. Если вы используете более современную студию вроде 2017 - то unordered_map намного быстрее, чем заказанная карта.
Используя неупорядоченную карту, вы объявляете, что нигде в вашем коде вы не полагаетесь на упорядоченную карту. Эта дополнительная контекстная информация в некоторых случаях может помочь понять, как эта карта фактически используется в программе. Ясность может быть важнее, поскольку производительность является побочным эффектом.
Конечно, ни один компилятор не остановит вас от использования неупорядоченной карты, когда вам нужна упорядоченная, но это слишком маловероятно, чтобы читатель мог полагаться на то, что это не просто ошибка.
От: http://www.cplusplus.com/reference/map/map/
"Внутренне элементы в карте всегда сортируются по ее ключу в соответствии с определенным критерием строгого слабого упорядочения, указанным его внутренним объектом сравнения (типа" Сравнить ").
Контейнеры map обычно медленнее, чем контейнеры unordered_map, для доступа к отдельным элементам по их ключу, но они допускают прямую итерацию для подмножеств в зависимости от их порядка ".