Как получить дополнительную колонку в карте тепла
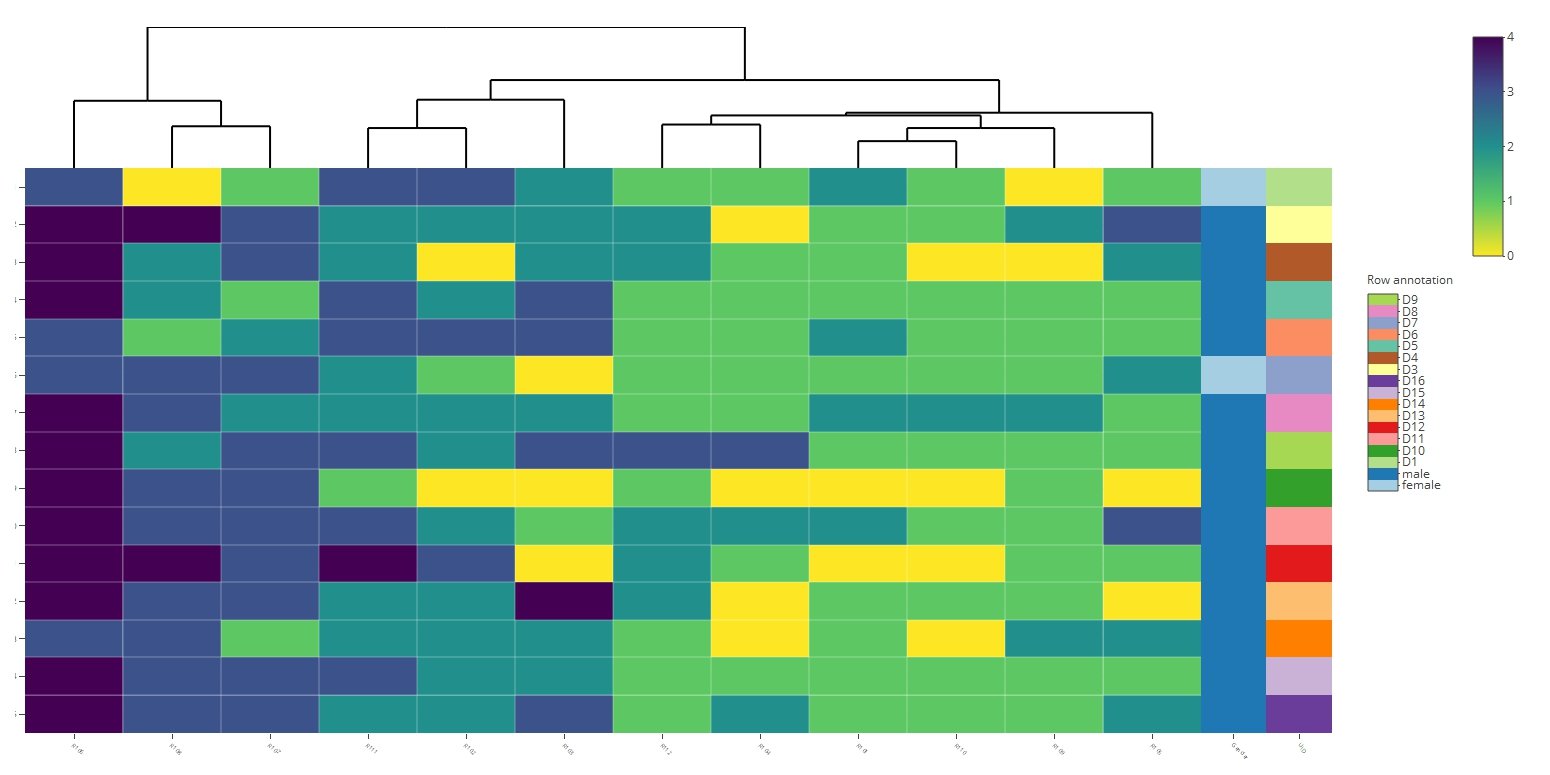
Я использую тепловую карту для получения кластерных тепловых карт ответов от нескольких оценщиков по ряду вопросов, оцененных с использованием одной и той же шкалы Лейкерта (статус производительности ECOG). Тепловая карта получается хорошо (хотя использование иерархической кластеризации на порядковых данных, как это, может быть не лучшим). Я хотел бы отобразить дополнительный столбец в тепловой карте, в котором есть информация о цветовой кодировке дополнительной переменной, например, Возраст. Пример тепловой карты, которую я создал с помощью пакета, прилагается. Колонна синего цвета содержит информацию о поле пациента, но она не имеет цветовой кодировки. Я хотел бы знать, можно ли сделать то же самое. Также приветствовал бы любые входные данные относительно правильной методологии кластеризации, которая будет использоваться для порядковых данных.
Оригинальная ссылка на карту 
Код используется здесь:
library(heatmaply)
data4 <- structure(list(UID = c("D1", "D3", "D4", "D5", "D6", "D7", "D8",
"D9", "D10", "D11", "D12", "D13", "D14", "D15", "D16"), R101 = c(2,
1, 1, 1, 2, 1, 2, 1, 0, 2, 0, 1, 1, 1, 1), R102 = c(3, 2, 0,
2, 3, 1, 2, 2, 0, 2, 3, 2, 2, 2, 2), R103 = c(2, 2, 2, 3, 3,
0, 2, 3, 0, 1, 0, 4, 2, 2, 3), R104 = c(1, 0, 1, 1, 1, 1, 1,
3, 0, 2, 1, 0, 0, 1, 2), R105 = c(1, 3, 2, 1, 1, 2, 1, 1, 0,
3, 1, 0, 2, 1, 2), R106 = c(3, 4, 4, 4, 3, 3, 4, 4, 4, 4, 4,
4, 3, 4, 4), R107 = c(1, 3, 3, 1, 2, 3, 2, 3, 3, 3, 3, 3, 1,
3, 3), R108 = c(0, 4, 2, 2, 1, 3, 3, 2, 3, 3, 4, 3, 3, 3, 3),
R109 = c(0, 2, 0, 1, 1, 1, 2, 1, 1, 1, 1, 1, 2, 1, 1), R110 = c(1,
1, 0, 1, 1, 1, 2, 1, 0, 1, 0, 1, 0, 1, 1), R111 = c(3, 2,
2, 3, 3, 2, 2, 3, 1, 3, 4, 2, 2, 3, 2), R112 = c(1, 2, 2,
1, 1, 1, 1, 3, 1, 2, 2, 2, 1, 1, 1), Gender = structure(c(2L,
1L, 1L, 1L, 1L, 2L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L), .Label = c("male",
"female"), class = "factor")), .Names = c("UID", "R101",
"R102", "R103", "R104", "R105", "R106", "R107", "R108", "R109",
"R110", "R111", "R112", "Gender"), row.names = c(NA, -15L), class = c("tbl_df",
"tbl", "data.frame"))
p <-heatmaply(data4[1:13],fontsize_row = 8,fontsize_col = 6,Rowv =F,grid_gap = 0.5,colors = viridis(n = 256, alpha = 1, begin = 1,end = 0, option = "viridis"),branches_lwd = 0.2,row_side_colors =as.factor( data4$Gender))
p
1 ответ
Код создает цветовую аннотацию для обоих факторов. Однако при наличии достаточного количества уровней цветовая схема по умолчанию становится радугой, которую сложно различить. Возможно, вам придется попытаться настроить тепловую карту или установить другую row_side_palette в heatmaply,
Вы также можете передать row_side_colors как data.frame а не вектор, чтобы гарантировать, что они названы правильно в именах строк и hovertext.
Посмотрите код ниже, который включает в себя несколько мелких настроек.
heatmaply(
data4[, setdiff(colnames(data4), c("Gender", "UID"))],
plot_method = "plotly",
fontsize_row = 8,
fontsize_col = 6,
Rowv = FALSE,
grid_gap = 0.5,
colors = viridis(n = 256, alpha = 1, begin = 1,end = 0, option = "viridis"),
branches_lwd = 0.2,
row_side_colors = data4[, c("Gender", "UID")])