Что-то не так с кодом Keras Q-learning Тренажерный зал OpenAI FrozenLake
Может быть, мой вопрос покажется глупым.
Я изучаю алгоритм Q-обучения. Чтобы лучше понять это, я пытаюсь преобразовать код Tenzorflow этого примера FrozenLake в код Keras.
Мой код:
import gym
import numpy as np
import random
from keras.layers import Dense
from keras.models import Sequential
from keras import backend as K
import matplotlib.pyplot as plt
%matplotlib inline
env = gym.make('FrozenLake-v0')
model = Sequential()
model.add(Dense(16, activation='relu', kernel_initializer='uniform', input_shape=(16,)))
model.add(Dense(4, activation='softmax', kernel_initializer='uniform'))
def custom_loss(yTrue, yPred):
return K.sum(K.square(yTrue - yPred))
model.compile(loss=custom_loss, optimizer='sgd')
# Set learning parameters
y = .99
e = 0.1
#create lists to contain total rewards and steps per episode
jList = []
rList = []
num_episodes = 2000
for i in range(num_episodes):
current_state = env.reset()
rAll = 0
d = False
j = 0
while j < 99:
j+=1
current_state_Q_values = model.predict(np.identity(16)[current_state:current_state+1], batch_size=1)
action = np.reshape(np.argmax(current_state_Q_values), (1,))
if np.random.rand(1) < e:
action[0] = env.action_space.sample() #random action
new_state, reward, d, _ = env.step(action[0])
rAll += reward
jList.append(j)
rList.append(rAll)
new_Qs = model.predict(np.identity(16)[new_state:new_state+1], batch_size=1)
max_newQ = np.max(new_Qs)
targetQ = current_state_Q_values
targetQ[0,action[0]] = reward + y*max_newQ
model.fit(np.identity(16)[current_state:current_state+1], targetQ, verbose=0, batch_size=1)
current_state = new_state
if d == True:
#Reduce chance of random action as we train the model.
e = 1./((i/50) + 10)
break
print("Percent of succesful episodes: " + str(sum(rList)/num_episodes) + "%")
Когда я запускаю его, он не работает хорошо: процент успешных эпизодов: 0,052%
plt.plot(rList)
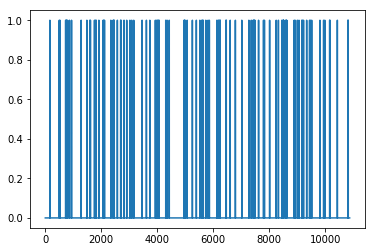
Оригинальный код Tensorflow гораздо лучше: процент успешных эпизодов: 0,352%
plt.plot(rList)
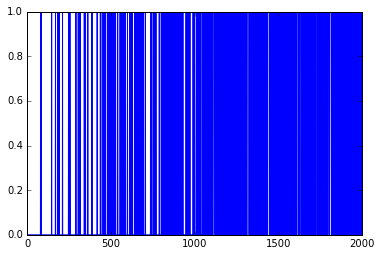
Что я сделал не так?
1 ответ
Помимо установки use_bias=False как @Maldus, упомянутого в комментариях, вы можете попробовать еще раз начать с более высокого значения epsilon (например, 0.5, 0.75)? Уловка может состоять в том, чтобы только уменьшить значение эпсилона, ЕСЛИ вы достигнете цели. т.е. не уменьшайте эпсилон в конце каждого эпизода. Таким образом, ваш игрок может продолжать исследовать карту случайным образом, пока она не начнет сходиться на хорошем маршруте, и тогда будет хорошей идеей уменьшить параметр epsilon.
На самом деле я реализовал аналогичную модель в керасе в этой сущности, используя сверточные слои вместо плотных. Удалось заставить его работать до 2000 эпизодов. Может быть, помочь другим:)