dplyr обобщить с помощью промежуточных итогов
Одна из замечательных особенностей сводных таблиц в Excel заключается в том, что они предоставляют промежуточные итоги автоматически. Во-первых, я хотел бы знать, есть ли в dplyr что-нибудь, что может сделать это. Если нет, то как проще всего это сделать?
В приведенном ниже примере я показываю среднее смещение по количеству цилиндров и карбюраторов. Для каждой группы цилиндров (4,6,8) я хотел бы увидеть среднее смещение для группы (или общее смещение, или любую другую сводную статистику).
library(dplyr)
mtcars %>% group_by(cyl,carb) %>% summarize(mean(disp))
cyl carb mean(disp)
1 4 1 91.38
2 4 2 116.60
3 6 1 241.50
4 6 4 163.80
5 6 6 145.00
6 8 2 345.50
7 8 3 275.80
8 8 4 405.50
9 8 8 301.00
6 ответов
data.table Это очень неуклюже, но это один из способов:
library(data.table)
DT <- data.table(mtcars)
rbind(
DT[,.(mean(disp)), by=.(cyl,carb)],
DT[,.(mean(disp), carb=NA), by=.(cyl) ],
DT[,.(mean(disp), cyl=NA), by=.(carb)]
)[order(cyl,carb)]
Это дает
cyl carb V1
1: 4 1 91.3800
2: 4 2 116.6000
3: 4 NA 105.1364
4: 6 1 241.5000
5: 6 4 163.8000
6: 6 6 145.0000
7: 6 NA 183.3143
8: 8 2 345.5000
9: 8 3 275.8000
10: 8 4 405.5000
11: 8 8 301.0000
12: 8 NA 353.1000
13: NA 1 134.2714
14: NA 2 208.1600
15: NA 3 275.8000
16: NA 4 308.8200
17: NA 6 145.0000
18: NA 8 301.0000
Я бы предпочел увидеть результаты в чем-то вроде R table, но не знаю каких-либо функций для этого.
dplyr @akrun нашел этот аналогичный код
bind_rows(
mtcars %>%
group_by(cyl, carb) %>%
summarise(Mean= mean(disp)),
mtcars %>%
group_by(cyl) %>%
summarise(carb=NA, Mean=mean(disp)),
mtcars %>%
group_by(carb) %>%
summarise(cyl=NA, Mean=mean(disp))
) %>% arrange(cyl, carb)
Мы могли бы обернуть повторяющиеся операции в функцию
library(lazyeval)
f1 <- function(df, grp, Var, func){
FUN <- match.fun(func)
df %>%
group_by_(.dots=grp) %>%
summarise_(interp(~FUN(v), v=as.name(Var)))
}
m1 <- f1(mtcars, c('carb', 'cyl'), 'disp', 'mean')
m2 <- f1(mtcars, 'carb', 'disp', 'mean')
m3 <- f1(mtcars, 'cyl', 'disp', 'mean')
bind_rows(list(m1, m2, m3)) %>%
arrange(cyl, carb) %>%
rename(Mean=`FUN(disp)`)
carb cyl Mean
1 1 4 91.3800
2 2 4 116.6000
3 NA 4 105.1364
4 1 6 241.5000
5 4 6 163.8000
6 6 6 145.0000
7 NA 6 183.3143
8 2 8 345.5000
9 3 8 275.8000
10 4 8 405.5000
11 8 8 301.0000
12 NA 8 353.1000
13 1 NA 134.2714
14 2 NA 208.1600
15 3 NA 275.8000
16 4 NA 308.8200
17 6 NA 145.0000
18 8 NA 301.0000
Любой из этих вариантов можно сделать немного менее уродливым с помощью data.table's rbindlist с fill:
rbindlist(list(
mtcars %>% group_by(cyl) %>% summarise(mean(disp)),
mtcars %>% group_by(carb) %>% summarise(mean(disp)),
mtcars %>% group_by(cyl,carb) %>% summarise(mean(disp))
),fill=TRUE) %>% arrange(cyl,carb)
rbindlist(list(
DT[,mean(disp),by=.(cyl,carb)],
DT[,mean(disp),by=.(cyl)],
DT[,mean(disp),by=.(carb)]
),fill=TRUE)[order(cyl,carb)]
Также возможно, просто объединяя результаты двух групп:
cyl_carb <- mtcars %>% group_by(cyl,carb) %>% summarize(mean(disp))
cyl <- mtcars %>% group_by(cyl) %>% summarize(mean(disp))
joined <- full_join(cyl_carb, cyl)
result <- arrange(joined, cyl)
result
дает:
Source: local data frame [12 x 3]
Groups: cyl [3]
cyl carb mean(disp)
(dbl) (dbl) (dbl)
1 4 1 91.3800
2 4 2 116.6000
3 4 NA 105.1364
4 6 1 241.5000
5 6 4 163.8000
6 6 6 145.0000
7 6 NA 183.3143
8 8 2 345.5000
9 8 3 275.8000
10 8 4 405.5000
11 8 8 301.0000
12 8 NA 353.1000
или с дополнительным столбцом:
cyl_carb <- mtcars %>% group_by(cyl,carb) %>% summarize(mean(disp))
cyl <- mtcars %>% group_by(cyl) %>% summarize(mean.cyl = mean(disp))
joined <- full_join(cyl_carb, cyl)
joined
дает:
Source: local data frame [9 x 4]
Groups: cyl [?]
cyl carb mean(disp) mean.cyl
(dbl) (dbl) (dbl) (dbl)
1 4 1 91.38 105.1364
2 4 2 116.60 105.1364
3 6 1 241.50 183.3143
4 6 4 163.80 183.3143
5 6 6 145.00 183.3143
6 8 2 345.50 353.1000
7 8 3 275.80 353.1000
8 8 4 405.50 353.1000
9 8 8 301.00 353.1000
Что-то похожее table с addmargins (хотя на самом деле data.frame)
library(dplyr)
library(reshape2)
out <- bind_cols(
mtcars %>% group_by(cyl, carb) %>%
summarise(mu = mean(disp)) %>%
dcast(cyl ~ carb),
(mtcars %>% group_by(cyl) %>% summarise(Total=mean(disp)))[,2]
)
margin <- t((mtcars %>% group_by(carb) %>% summarise(Total=mean(disp)))[,2])
rbind(out, c(NA, margin, mean(mtcars$disp))) %>%
`rownames<-`(c(paste("cyl", c(4,6,8)), "Total")) # add some row names
# cyl 1 2 3 4 6 8 Total
# cyl 4 4 91.3800 116.60 NA NA NA NA 105.1364
# cyl 6 6 241.5000 NA NA 163.80 145 NA 183.3143
# cyl 8 8 NA 345.50 275.8 405.50 NA 301 353.1000
# Total NA 134.2714 208.16 275.8 308.82 145 301 230.7219
Нижний ряд - поля столбцов, столбцы с именами 1:8 - углеводы, а Total - поляризованные поля.
Вот простой однострочник, создающий поля в рамках data_frame:
library(plyr)
library(dplyr)
# Margins without labels
mtcars %>%
group_by(cyl,carb) %>%
summarize(Mean_Disp=mean(disp)) %>%
do(plyr::rbind.fill(., data_frame(cyl=first(.$cyl), Mean_Disp=sum(.$Mean_Disp, na.rm=T))))
выход:
Source: local data frame [12 x 3]
Groups: cyl [3]
cyl carb Mean_Disp
<dbl> <dbl> <dbl>
1 4 1 91.38
2 4 2 116.60
3 4 NA 207.98
4 6 1 241.50
5 6 4 163.80
6 6 6 145.00
7 6 NA 550.30
8 8 2 345.50
9 8 3 275.80
10 8 4 405.50
11 8 8 301.00
12 8 NA 1327.80
Вы также можете добавить ярлыки для сводной статистики, например:
mtcars %>%
group_by(cyl,carb) %>%
summarize(Mean_Disp=mean(disp)) %>%
do(plyr::rbind.fill(., data_frame(cyl=first(.$cyl), carb=c("Total", "Mean"), Mean_Disp=c(sum(.$Mean_Disp, na.rm=T), mean(.$Mean_Disp, na.rm=T)))))
выход:
Source: local data frame [15 x 3]
Groups: cyl [3]
cyl carb Mean_Disp
<dbl> <chr> <dbl>
1 4 1 91.38
2 4 2 116.60
3 4 Total 207.98
4 4 Mean 103.99
5 6 1 241.50
6 6 4 163.80
7 6 6 145.00
8 6 Total 550.30
9 6 Mean 183.43
10 8 2 345.50
11 8 3 275.80
12 8 4 405.50
13 8 8 301.00
14 8 Total 1327.80
15 8 Mean 331.95
С участием data.table версия выше v1.11
library(data.table)
cubed <- cube(
as.data.table(mtcars),
.(`mean(disp)` = mean(disp)),
by = c("cyl", "carb")
)
#> cyl carb mean(disp)
#> 1: 6 4 163.8000
#> 2: 4 1 91.3800
#> 3: 6 1 241.5000
#> 4: 8 2 345.5000
#> 5: 8 4 405.5000
#> 6: 4 2 116.6000
#> 7: 8 3 275.8000
#> 8: 6 6 145.0000
#> 9: 8 8 301.0000
#> 10: 6 NA 183.3143
#> 11: 4 NA 105.1364
#> 12: 8 NA 353.1000
#> 13: NA 4 308.8200
#> 14: NA 1 134.2714
#> 15: NA 2 208.1600
#> 16: NA 3 275.8000
#> 17: NA 6 145.0000
#> 18: NA 8 301.0000
#> 19: NA NA 230.7219
res <- dcast(
cubed,
cyl ~ carb,
value.var = "mean(disp)"
)
#> cyl NA 1 2 3 4 6 8
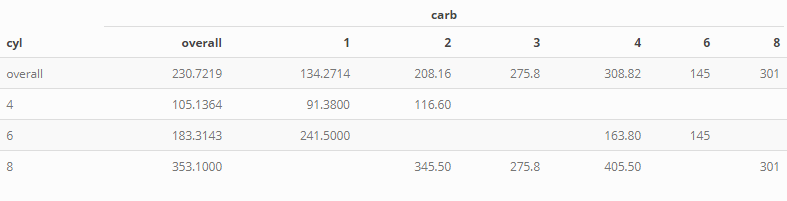
#> 1: NA 230.7219 134.2714 208.16 275.8 308.82 145 301
#> 2: 4 105.1364 91.3800 116.60 NA NA NA NA
#> 3: 6 183.3143 241.5000 NA NA 163.80 145 NA
#> 4: 8 353.1000 NA 345.50 275.8 405.50 NA 301
Создано 20.02.2020 пакетом REPEX (v0.3.0)
Источник: https://jozef.io/r912-datatable-grouping-sets/
library(kableExtra)
options(knitr.kable.NA = "")
res <- as.data.frame(res)
names(res)[2] <- "overall"
res[1, 1] <- "overall"
x <- kable(res, "html")
x <- kable_styling(x, "striped")
add_header_above(x, c(" " = 1, "carb" = ncol(res) - 1))
Я знаю, что это может быть не очень элегантное решение, но я надеюсь, что оно все равно поможет:
p <-mtcars %>% group_by(cyl,carb)
p$cyl <- as.factor(p$cyl)
average_disp <- sapply(1:length(levels(p$cyl)), function(x)mean(subset(p,p$cyl==levels(p$cyl)[x])$disp))
df <- data.frame(levels(p$cyl),average_disp)
colnames(df)[1]<-"cyl"
#> df
# cyl average_disp
#1 4 105.1364
#2 6 183.3143
#3 8 353.1000
(Изменить: после незначительного изменения в определении p теперь это дает те же результаты, что и решение @Frank's и @akrun)
Вы можете использовать эту обертку вокруг ddply, который применяется ddply за каждый возможный запас и rbinds результаты с его обычным выходом.
Чтобы выделить все факторы группировки:
mtcars %>% ddplym(.variables = .(cyl, carb), .fun = summarise, mean(disp))
Чтобы изолировать над carb только:
mtcars %>% ddplym(
.variables = .(carb),
.fun = function(data) data %>% group_by(cyl) %>% summarise(mean(disp)))
Упаковочный:
require(plyr)
require(dplyr)
ddplym <- function(.data, .variables, .fun, ..., .margin = TRUE, .margin_name = '(all)') {
if (.margin) {
df <- .ddplym(.data, .variables, .fun, ..., .margin_name = .margin_name)
} else {
df <- ddply(.data, .variables, .fun, ...)
if (.variables %>% length == 0) {
df$.id <- NULL
}
}
return(df)
}
.ddplym <- function(.data,
.variables,
.fun,
...,
.margin_name = '(all)'
) {
.variables <- as.quoted(.variables)
n <- length(.variables)
var_combn_idx <- lapply(0:n, function(x) {
combn(1:n, n - x) %>% alply(2, c)
}) %>%
unlist(recursive = FALSE, use.names = FALSE)
data_list <- lapply(var_combn_idx, function(x) {
data <- ddply(.data, .variables[x], .fun, ...)
# drop '.id' column created when no variables to split by specified
if (!length(.variables[x]))
data <- data[, -1, drop = FALSE]
return(data)
})
# workaround for NULL .variables
if (unlist(.variables) %>% is.null && names(.variables) %>% is.null) {
data_list <- data_list[1]
} else if (unlist(.variables) %>% is.null) {
data_list <- data_list[2]
}
if (length(data_list) > 1) {
data_list <- lapply(data_list, function(data)
rbind_pre(
data = data,
colnames = colnames(data_list[[1]]),
fill = .margin_name
))
}
Reduce(rbind, data_list)
}
rbind_pre <- function(data, colnames, fill = NA) {
colnames_fill <- setdiff(colnames, colnames(data))
data_fill <- matrix(fill,
nrow = nrow(data),
ncol = length(colnames_fill)) %>%
as.data.frame %>% setNames(colnames_fill)
cbind(data, data_fill)[, colnames]
}
Имея такую же проблему, я работаю над функцией, которая, надеюсь, решит эту проблему (см. https://github.com/jrf1111/TCCD/blob/dev/R/with_subtotals.R). Он все еще находится на стадии разработки, но делает именно то, что вы ищете.
mtcars %>%
group_by(cyl, carb) %>%
with_subtotals() %>%
summarize(mean(disp))
# A tibble: 19 x 3
# Groups: cyl [5]
cyl carb `mean(disp)`
<chr> <chr> <dbl>
1 4 1 91.4
2 4 2 117.
3 4 subtotal 105.
4 6 1 242.
5 6 4 164.
6 6 6 145
7 6 subtotal 183.
8 8 2 346.
9 8 3 276.
10 8 4 406.
11 8 8 301
12 8 subtotal 353.
13 subtotal 1 134.
14 subtotal 2 208.
15 subtotal 3 276.
16 subtotal 4 309.
17 subtotal 6 145
18 subtotal 8 301
19 total total 231.
Разделяю свой подход к этому (если он вообще полезен). Такой подход позволяет очень легко добавлять индивидуальные промежуточные итоги и итоги.
data = data.frame( thing1=sprintf("group %i",trunc(runif(200,0,5))),
thing2=sprintf("type %i",trunc(runif(200,0,5))),
value=rnorm(200,0,1) )
data %>%
group_by( thing1, thing2 ) %>%
summarise( sum=sum(value),
count=n() ) %>%
ungroup() %>%
bind_rows(.,
identity(.) %>%
group_by(thing1) %>%
summarise( aggregation="sub total",
sum=sum(sum),
count=sum(count) ) %>%
ungroup(),
identity(.) %>%
summarise( aggregation="total",
sum=sum(sum),
count=sum(count) ) %>%
ungroup() ) %>%
arrange( thing1, thing2, aggregation ) %>%
select( aggregation, everything() )
Попробовав долго и упорно, очень похожие вопросы, я обнаружил, что data.table предлагает самое простое и быстрое решение, которое подходит именно для этой цели
data.table::cube(
data.table::as.data.table(mtcars),
.(mean_disp = mean(disp)),
by = c("cyl","carb"))
cyl carb mean_disp
1: 6 4 163.8000
2: 4 1 91.3800
3: 6 1 241.5000
4: 8 2 345.5000
5: 8 4 405.5000
6: 4 2 116.6000
7: 8 3 275.8000
8: 6 6 145.0000
9: 8 8 301.0000
10: 6 NA 183.3143
11: 4 NA 105.1364
12: 8 NA 353.1000
13: NA 4 308.8200
14: NA 1 134.2714
15: NA 2 208.1600
16: NA 3 275.8000
17: NA 6 145.0000
18: NA 8 301.0000
19: NA NA 230.7219
В NAзаписи - это промежуточные итоги, которые вы ищете; например, в строке 10183.31результат - среднее значение для всех 6 цилиндров. Последний ряд с двойнымNA тот, у которого есть общее среднее значение.
Оттуда вы можете легко обернуть результат as_tibble() прыгнуть обратно в dplyr мир семантики.