Нейроэволюция возрастающих топологий (NEAT) и глобальное количество инноваций
Я не смог найти, почему у нас должен быть глобальный номер инновации для каждого нового гена соединения в NEAT.
Из моего небольшого знания NEAT каждый номер инновации напрямую связан с парой node_in, node_out, так почему бы не использовать эту пару идентификаторов вместо номера инновации? Какая новая информация есть в этом номере инновации? хронология?
Обновить
Это алгоритм оптимизации?
2 ответа
Примечание: это скорее расширенный комментарий, чем ответ.
Вы столкнулись с проблемой, с которой я также столкнулся при разработке NEAT-версии для JavaScript. Оригинальная статья, опубликованная в 2002 году, очень неясна.
Оригинальный документ содержит следующее:
Всякий раз, когда появляется новый ген (посредством структурной мутации), глобальный инновационный номер увеличивается и присваивается этому гену. Таким образом, числа инноваций представляют хронологию появления каждого гена в системе. [..]; количество инноваций никогда не меняется. Таким образом, историческое происхождение каждого гена в системе известно на протяжении всей эволюции.
Но в статье очень неясно о следующем случае, скажем, у нас есть два; "идентичные" (той же структуры) сети:
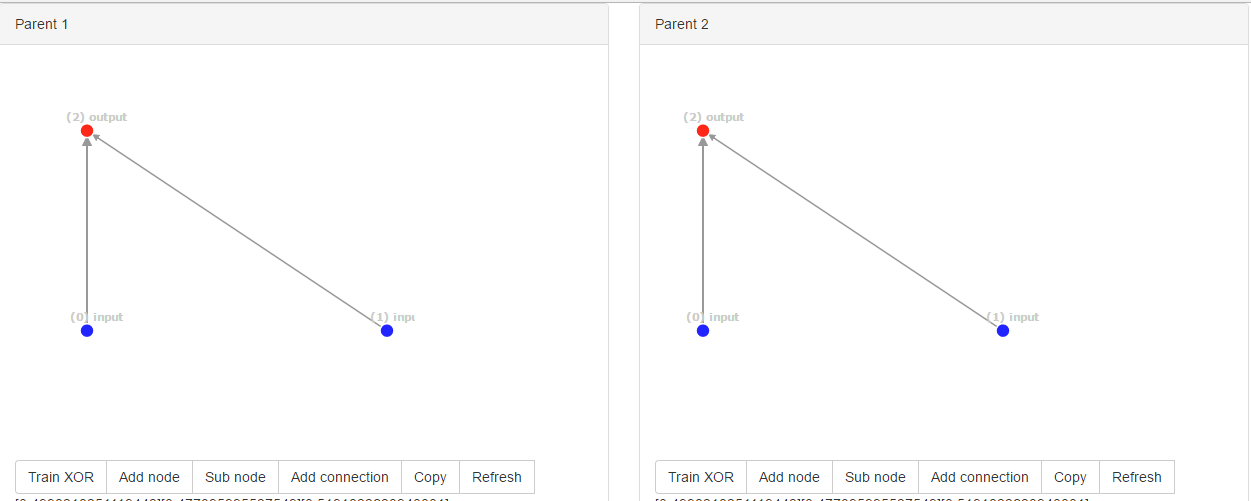
Вышеуказанные сети были начальными сетями; сети имеют одинаковый идентификатор инновации, а именно [0, 1], Так что теперь сети случайным образом видоизменяют дополнительное соединение.
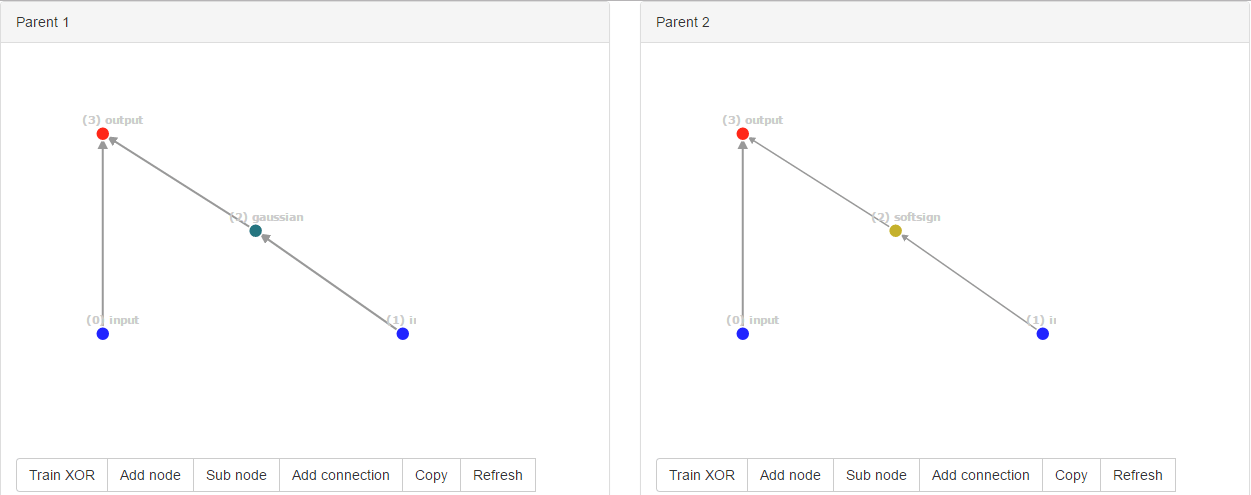
Boom! Случайно они мутировали в ту же новую структуру. Тем не менее, идентификаторы соединения совершенно разные, а именно [0, 2, 3] для parent1 и [0, 4, 5] для parent2 в качестве идентификатора учитывается глобально.
Но алгоритм NEAT не может определить, что эти структуры одинаковы. Когда один из родителей набирает больше очков, чем другой, это не проблема. Но когда родители имеют одинаковую физическую форму, у нас проблемы.
Поскольку в документе говорится:
При составлении потомства гены выбираются случайным образом из любого из родителей в совпадающих генах, тогда как все избыточные или непересекающиеся гены всегда включаются из более подходящего родителя или, если они одинаково подходят, из обоих родителей.
Так что, если родители в равной степени подходят, потомство будет иметь связи [0, 2, 3, 4, 5], Это означает, что некоторые узлы имеют двойные соединения... Удаление глобальных счетчиков инноваций и просто присваивание идентификаторов, глядя на node_in и node_out, вы избежите этой проблемы.
Поэтому, когда вы одинаково подходите родителям, вы оптимизировали алгоритм. Но это почти никогда не бывает.
Довольно интересно: в более новой версии статьи они фактически убрали эту жирную линию! Старая версия здесь.
Кстати, вы можете решить эту проблему, вместо того, чтобы назначать идентификаторы инноваций, назначать идентификаторы на основе node_in и node_out, используя функции сопряжения. Это создает довольно интересные нейронные сети, когда фитнес равен:
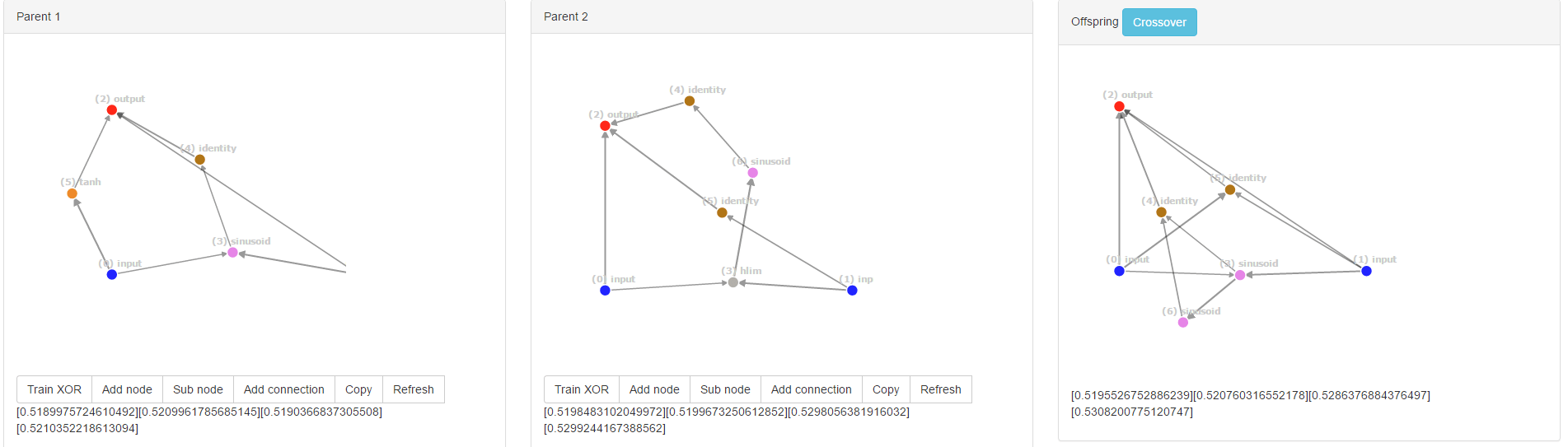
Когда я создавал свою первую реализацию NEAT, я думал так же... зачем вам сохранять трекер инновационных номеров...? и почему вы используете его только для одного поколения? Не лучше ли вообще его не хранить и использовать значение ключа, равное узлам?
Теперь, когда я внедряю свою третью версию, я вижу, что Кеннет Стэнли пытался сделать с ними и почему он хотел сохранить их только для одного поколения.
Когда соединение создано, оно начнет свою оптимизацию в этот момент. Это отмечает его происхождение. Если такое же соединение появится в другом поколении, тогда начнется его оптимизация. Числа поколений пытаются отделить те, которые происходят от общего предка, поэтому те, которые были оптимизированы для многих поколений, не ставятся рядом с тем, который был только что создан. Если одна и та же связь обнаружена в двух геномах, это означает, что этот ген происходит из одного источника и, следовательно, может быть выровнен.
Представьте себе, что у вас есть чемпион вашего поколения. Некоторые из их генов с вероятностью 50% будут потеряны из-за одинакового отношения к выровненным генам.
Что лучше...? Я не видел никаких экспериментов, сравнивающих два подхода.
Кеннет Стэнли также обратился к этой проблеме на странице пользователей NEAT: https://www.cs.ucf.edu/~kstanley/neat.html
Следует ли вести учет инноваций постоянно или только для нынешнего поколения?
В моей реализации NEAT запись ведется только в течение одного поколения, но нет ничего плохого в том, чтобы хранить их вечно. На самом деле, это может работать лучше. Вот длинное объяснение:
Причина, по которой я не вел запись всего прогона в моей реализации NEAT, заключалась в том, что я чувствовал, что вызывать что-то такое же, что и при совершенно других обстоятельствах, было не интуитивно. Таким образом, вполне вероятно, что через несколько поколений "значение" или вклад одного и того же соединения относительно всех других соединений в сети отличается от того, каким оно было бы, если бы оно появилось много поколений назад. Я использовал одно поколение в качестве критерия для такого рода ситуаций, хотя это по общему признанию ad hoc.
Тем не менее, с функциональной точки зрения, я не думаю, что есть что-то плохое в том, чтобы постоянно хранить инновации. Основным эффектом является создание меньшего количества видов. И наоборот, отсутствие их вокруг приводит к появлению большего количества видов… некоторые из них представляют одно и то же, но, тем не менее, разделяются. В настоящее время не ясно, какой метод дает лучшие результаты при каких обстоятельствах.
Обратите внимание, что по мере расхождения видов, называя соединение, появившееся у одного вида, другим именем, нежели название, появившееся ранее у другого, просто увеличивает несовместимость вида. Это мало что меняет, так как они были несовместимы с самого начала. С другой стороны, если тот же вид добавляет связь, которую он добавил в более раннем поколении, это должно означать, что некоторые представители вида еще не приняли эту связь... так что теперь, вероятно, что первая "версия" этого соединение, которое станет полезным, победит, а другое угаснет. Третий случай, когда связь уже была принята определенным видом. В этом случае не может быть никакой мутации, создающей такую же связь у этого вида, поскольку она уже взята. Суть в том, что вы не ожидаете появления слишком большого числа действительно похожих структур с разной маркировкой, даже если ведете учет только одно поколение.
Какой способ работает лучше всего - хороший вопрос. Если у вас есть интересные экспериментальные результаты по этому вопросу, пожалуйста, дайте мне знать.
Моя третья ревизия позволит оба варианта. Я добавлю больше информации к этому ответу, когда у меня будут результаты об этом.
Во время кроссовера мы должны рассмотреть два генома, которые разделяют связь между двумя одинаковыми узлами в их личных нейронных сетях. Как мы можем обнаружить это столкновение, не повторяя снова и снова гены связи обоих геномов для каждого шага кроссовера? Легко: если оба соединения, проверяемые во время кроссовера, совместно используют номер инновации, они соединяют одни и те же два узла, потому что они получили это соединение от одного общего предка.
Простой пример: если я являюсь геномом с определенным геном связи с инновационным номером "i", мои дети, которые берут от меня ген "i", могут в конечном итоге скрещиваться друг с другом через 100 поколений. Мы должны определить, когда эти две эволюционные версии (аллели) моего гена 'i' находятся в столкновении, чтобы предотвратить прием обоих. Если взять два одинаковых гена, фенотип, вероятно, зациклится и рухнет, убив генотип.
Я не могу дать подробный ответ, но число инноваций позволяет определенным функциям в модели NEAT быть оптимальными (например, вычисление вида гена), а также позволяет пересечение между геномами переменной длины. Кроссовер не нужен в NEAT, но это может быть сделано из-за количества инноваций.
Я получил все мои ответы отсюда:
http://nn.cs.utexas.edu/downloads/papers/stanley.ec02.pdf
Это хорошо читать