Расчеты недоумения растут между каждым значительным падением
Я тренирую разговорный агент, используя LSTM и модель перевода tenorflow. Я использую периодическое обучение, что приводит к значительному снижению сложности тренировочных данных после начала каждой эпохи. Это падение можно объяснить тем, как я считываю данные в пакеты, поскольку я гарантирую, что каждая обучающая пара в моих тренировочных данных обрабатывается ровно один раз в каждую эпоху. Когда начинается новая эпоха, улучшения, сделанные моделью в предыдущих эпохах, покажут свою прибыль, когда она снова встретит обучающие данные, представленные в виде падения на графике. Другие периодические подходы, такие как тот, который используется в модели трансляции tenorflow, не приведут к такому же поведению, поскольку их методология состоит в том, чтобы загружать все тренировочные данные в память и случайным образом выбирать выборки из них.
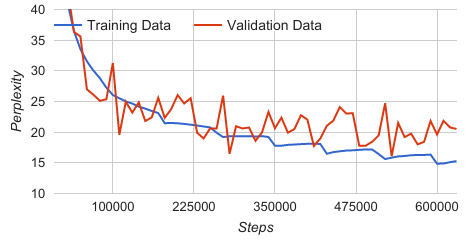
Шаг, недоумение
- 330000, 19,36
- 340000, 19,20
- 350000, 17,79
- 360000, 17,79
- 370000, 17,93
- 380000, 17,98
- 390000, 18,05
- 400000, 18.10
- 410000, 18,14
- 420000, 18,07
- 430000, 16,48
- 440000, 16,75
(Небольшое отрывание от недоумения, показывающее падение на 350000 и 430000. Между каплями недоумение немного возрастает)
Однако мой вопрос касается тренда после падения. Из графика видно, что недоумение немного возрастает (для каждой эпохи после шага ~350000), до следующего падения. Может кто-нибудь дать ответ или теорию, почему это происходит?