Чистый Архитектурный Дизайн Шаблон
https://8thlight.com/blog/uncle-bob/2012/08/13/the-clean-architecture.html
У меня есть вопрос по этому шаблону. База данных находится на внешнем уровне, но как это будет работать в реальности? Например, если у меня есть Microservices, который просто управляет этой сущностью:
person{
id,
name,
age
}И один из вариантов использования будет управлять людьми. Manage Persons сохраняет / извлекает / .. Persons (=> операции CRUD), но для этого сценарий использования должен общаться с базой данных. Но это было бы нарушением правила зависимости
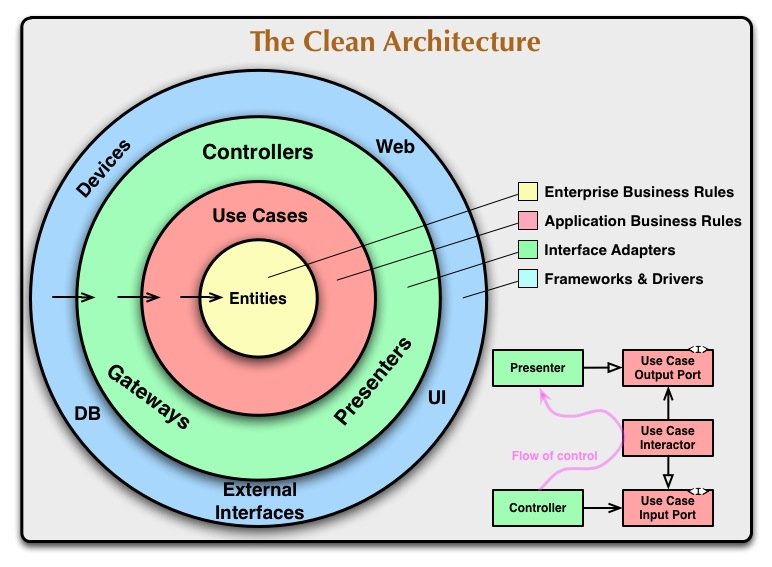
Главное правило, которое заставляет эту архитектуру работать, - это правило зависимости. Это правило говорит, что зависимости исходного кода могут указывать только внутрь.
- Будет ли это даже допустимым вариантом использования?
- как я могу получить доступ к базе данных, если она находится на внешнем уровне? (Зависимость Iversion?)
Если я получу GET /person/{id} Запрос должен ли мой Microservices обрабатывать это так?
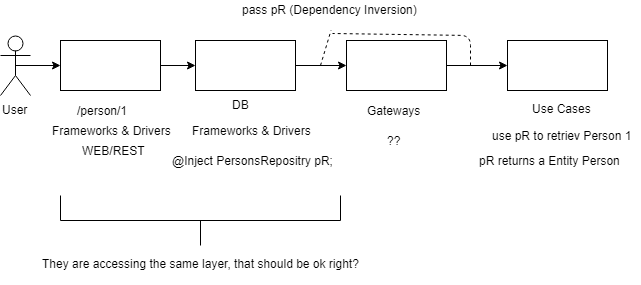
Но использование инверсии зависимости будет нарушением
Ничто во внутреннем круге не может вообще ничего знать о чем-то во внешнем круге. В частности, имя чего-либо, объявленного во внешнем круге, не должно упоминаться кодом во внутреннем круге. Это включает в себя функции, классы. переменные или любой другой названный программный объект.
Пересечение границ. В правом нижнем углу диаграммы показан пример того, как мы пересекаем границы круга. На нем показаны контроллеры и презентаторы, взаимодействующие с вариантами использования на следующем уровне. Обратите внимание на поток контроля. Он начинается в контроллере, проходит через сценарий использования, а затем завершается выполнением в презентаторе. Обратите внимание также на зависимости исходного кода. Каждый из них направлен внутрь на случаи использования.
Мы обычно разрешаем это очевидное противоречие, используя принцип инверсии зависимости. Например, в таком языке, как Java, мы бы организовали интерфейсы и отношения наследования таким образом, чтобы зависимости исходного кода противодействовали потоку управления только в нужных точках через границу.
Например, учтите, что в случае использования необходимо позвонить докладчику. Тем не менее, этот вызов не должен быть прямым, потому что это нарушит правило зависимости: ни одно имя во внешнем круге не может быть упомянуто внутренним кругом. Таким образом, у нас есть вариант использования, вызывающий интерфейс (показанный здесь как порт вывода варианта использования) во внутреннем круге, и ведущий во внешнем круге реализует его.
Эта же техника используется для пересечения всех границ в архитектурах. Мы используем преимущества динамического полиморфизма для создания зависимостей исходного кода, которые противостоят потоку управления, чтобы мы могли соответствовать правилу зависимости независимо от того, в каком направлении движется поток управления.
Если уровень варианта использования объявляет интерфейс репозитория, который будет реализован пакетом БД (уровень Frameworks & Drivers)
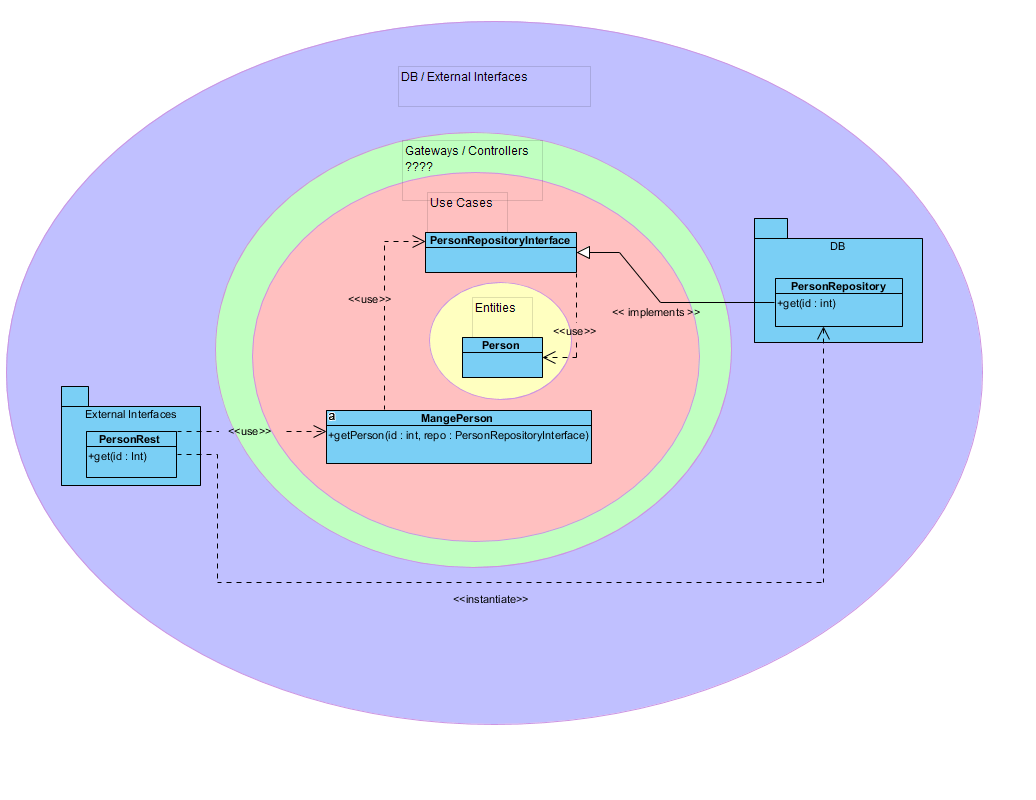
Если Сервер получает GET /persons/1 Запросить PersonRest создаст PersonRepository и передаст этот репозиторий + идентификатор в функцию ManagePerson::getPerson, getPerson не знает PersonRepository, но знает интерфейс, который он реализует, поэтому он не нарушает никаких правил, верно?
ManagePerson::getPerson будет использовать этот репозиторий для поиска сущности и вернет Person Person в PersonRest::get, который вернет Json Objekt клиенту, верно?
К сожалению, английский не мой родной язык, поэтому я надеюсь, что вы, ребята, дадите мне знать, если я правильно понял схему и, возможно, ответите на некоторые мои вопросы.
Ты заранее
2 ответа
База данных находится на внешнем уровне, но как это будет работать в реальности?
Вы создаете независимый от технологии интерфейс на уровне шлюза и внедряете его на уровне базы данных. Например
public interface OrderRepository {
public List<Order> findByCustomer(Customer customer);
}
реализация находится на уровне БД
public class HibernateOrderRepository implements OrderRepository {
...
}
Во время выполнения внутренние слои внедряются с реализациями внешних слоев. Но у вас нет зависимости исходного кода.
Вы можете увидеть это, отсканировав свои операторы импорта.
И один из вариантов использования будет управлять людьми. Manage Persons сохраняет / извлекает / .. Persons (=> операции CRUD), но для этого сценарий использования должен общаться с базой данных. Но это было бы нарушением правила зависимости
Нет, это не нарушило бы правило зависимости, потому что варианты использования определяют интерфейс, который им нужен. БД просто реализует это.
Если вы управляете зависимостями вашего приложения с помощью maven, вы увидите, что модуль db jar зависит от вариантов использования, а не наоборот. Но было бы еще лучше извлечь интерфейс этих прецедентов в собственный модуль.
Тогда зависимости модуля будут выглядеть так
+-----+ +---------------+ +-----------+
| db | --> | use-cases-api | <-- | use cases |
+-----+ +---------------+ +-----------+
это инверсия зависимостей, которые в противном случае выглядели бы так
+-----+ +-----------+
| db | <-- | use cases |
+-----+ +-----------+
Если я получу запрос GET /person/{id}, должен ли мой Микросервис обрабатывать его следующим образом?
Да, это было бы нарушением, потому что веб-слой обращается к слою БД. Лучшим подходом является то, что веб-уровень обращается к уровню контроллера, который обращается к уровню варианта использования и так далее.
Чтобы сохранить инверсию зависимостей, вы должны отделить слои, используя интерфейсы, как я показал выше.
Поэтому, если вы хотите передать данные на внутренний уровень, вы должны ввести интерфейс на внутреннем уровне, который определяет методы для получения необходимых данных и реализации их на внешнем уровне.
На уровне контроллера вы будете указывать такой интерфейс
public interface ControllerParams {
public Long getPersonId();
}
в веб-слое вы можете реализовать свой сервис, как это
@Path("/person")
public PersonRestService {
// Maybe injected using @Autowired if you are using spring
private SomeController someController;
@Get
@Path("{id}")
public void getPerson(PathParam("id") String id){
try {
Long personId = Long.valueOf(id);
someController.someMethod(new ControllerParams(){
public Long getPersonId(){
return personId;
}
});
} catch (NumberFormatException e) {
// handle it
}
}
}
На первый взгляд, это похоже на стандартный код. Но имейте в виду, что вы можете позволить остальной среде десериализовать запрос в объект Java. И этот объект может реализовать ControllerParams вместо.
Следовательно, если вы будете следовать правилу инверсии зависимостей и чистой архитектуре, вы никогда не увидите оператор импорта класса внешнего уровня во внутреннем уровне.
Целью чистой архитектуры является то, что основные бизнес-классы не зависят от какой-либо технологии или среды. Поскольку зависимости указывают от внешнего к внутреннему слоям, единственной причиной изменения внешнего слоя является изменение внутреннего слоя. Или если вы обменяетесь на технологию реализации внешнего уровня. Например, Отдых -> МЫЛО
Так почему мы должны делать это?
Роберт К. Мартин рассказывает об этом в главе 5 "Объектно-ориентированное программирование". В конце раздела инверсии зависимостей он говорит:
При таком подходе архитекторы программного обеспечения, работающие в системах, написанных на ОО-языках, полностью контролируют направление всех зависимостей исходного кода в системе. Они не обязаны выравнивать эти зависимости с потоком управления. Независимо от того, какой модуль вызывает и какой модуль вызывается, архитектор программного обеспечения может указать зависимость исходного кода в любом направлении.
Это сила!
Я предполагаю, что разработчики часто смущаются из-за потока управления и зависимости исходного кода. Поток управления обычно остается тем же самым, но зависимости исходного кода инвертированы. Это дает нам возможность создавать подключаемые архитектуры. Каждый интерфейс является точкой подключения. Таким образом, его можно заменить, например, по техническим причинам или в целях тестирования.
РЕДАКТИРОВАТЬ
уровень шлюза = интерфейс OrderRepository => не должен ли OrderRepository-Interface быть внутри UseCases, потому что мне нужно использовать операции crud на этом уровне?
Я думаю, что это нормально, чтобы переместить OrderRepository в слой варианта использования. Другой вариант - использовать входные и выходные порты варианта использования. Входной порт варианта использования может иметь методы, подобные хранилищу, например findOrderByIdи адаптирует это к OrderRepository, Для устойчивости он может использовать методы, которые вы определили в выходном порту.
public interface UseCaseInputPort {
public Order findOrderById(Long id);
}
public interface UseCaseOutputPort {
public void save(Order order);
}
Разница только с использованием OrderRepository в том, что порты прецедентов содержат только специфичные для прецедента методы репозитория. Таким образом, они изменяются только в случае изменения варианта использования. Таким образом, они несут единоличную ответственность, и вы соблюдали принцип разделения интерфейса.
Ключевым элементом является инверсия зависимостей. Ни один из внутренних слоев не должен иметь зависимостей от внешних слоев. Таким образом, если, например, слою Use Case необходимо вызвать хранилище базы данных, вы должны определить интерфейс хранилища (просто интерфейс, без какой-либо реализации) внутри уровня Use Case и поместить его реализацию на уровень Interface Adapters.