Интерпретация тензорных участков
Я все еще новичок в tensorflow и я пытаюсь понять, что происходит, во время обучения моих моделей. Вкратце, я использую slim модели с предварительной подготовкой ImageNet сделать finetuning на моем наборе данных. Вот несколько графиков, извлеченных из тензорной доски для двух отдельных моделей:
Model_1 (InceptionResnet_V2)

Model_2 (InceptionV4)

Пока что обе модели имеют плохие результаты на валидационных наборах (Среднее значение Az (Площадь под кривой ROC) = 0,7 для Model_1 & 0,79 для Model_2). Моя интерпретация этих графиков заключается в том, что веса не меняются по сравнению с мини-партиями. Это только уклоны, которые изменяются по мини-партиям, и это может быть проблемой. Но я не знаю, где искать, чтобы проверить этот момент. Это единственное толкование, которое я могу придумать, но оно может быть неправильным, учитывая тот факт, что я все еще новичок. Можете ли вы поделиться со мной своими мыслями? Не стесняйтесь просить больше участков в случае необходимости.
РЕДАКТИРОВАТЬ: Как вы можете видеть на графиках ниже, кажется, что веса практически не меняются с течением времени. Это применяется ко всем другим весам для обеих сетей. Это привело меня к мысли, что где-то есть проблема, но я не знаю, как ее интерпретировать.
InceptionV4 weights

InceptionResnetV2 weights

РЕДАКТИРОВАТЬ 2: Эти модели были впервые обучены в ImageNet, и эти графики являются результатами настройки их на моем наборе данных. Я использую набор данных из 19 классов с примерно 800000 изображений в нем. Я занимаюсь проблемой классификации по нескольким меткам и использую sigmoid_crossentropy в качестве функции потерь. Классы сильно разбалансированы. В таблице ниже мы показываем процент присутствия каждого класса в 2 подмножествах (поезд, проверка):
Objects train validation
obj_1 3.9832 % 0.0000 %
obj_2 70.6678 % 33.3253 %
obj_3 89.9084 % 98.5371 %
obj_4 85.6781 % 81.4631 %
obj_5 92.7638 % 71.4327 %
obj_6 99.9690 % 100.0000 %
obj_7 90.5899 % 96.1605 %
obj_8 77.1223 % 91.8368 %
obj_9 94.6200 % 98.8323 %
obj_10 88.2051 % 95.0989 %
obj_11 3.8838 % 9.3670 %
obj_12 50.0131 % 24.8709 %
obj_13 0.0056 % 0.0000 %
obj_14 0.3237 % 0.0000 %
obj_15 61.3438 % 94.1573 %
obj_16 93.8729 % 98.1648 %
obj_17 93.8731 % 97.5094 %
obj_18 59.2404 % 70.1059 %
obj_19 8.5414 % 26.8762 %
Значения гиперпарама:
batch_size=32
weight_decay = 0.00004 #'The weight decay on the model weights.'
optimizer = rmsprop
rmsprop_momentum = 0.9
rmsprop_decay = 0.9 #'Decay term for RMSProp.'
learning_rate_decay_type = exponential #Specifies how the learning rate is decayed
learning_rate = 0.01 #Initial learning rate.
learning_rate_decay_factor = 0.94 #Learning rate decay factor
num_epochs_per_decay = 2.0 #'Number of epochs after which learning rate
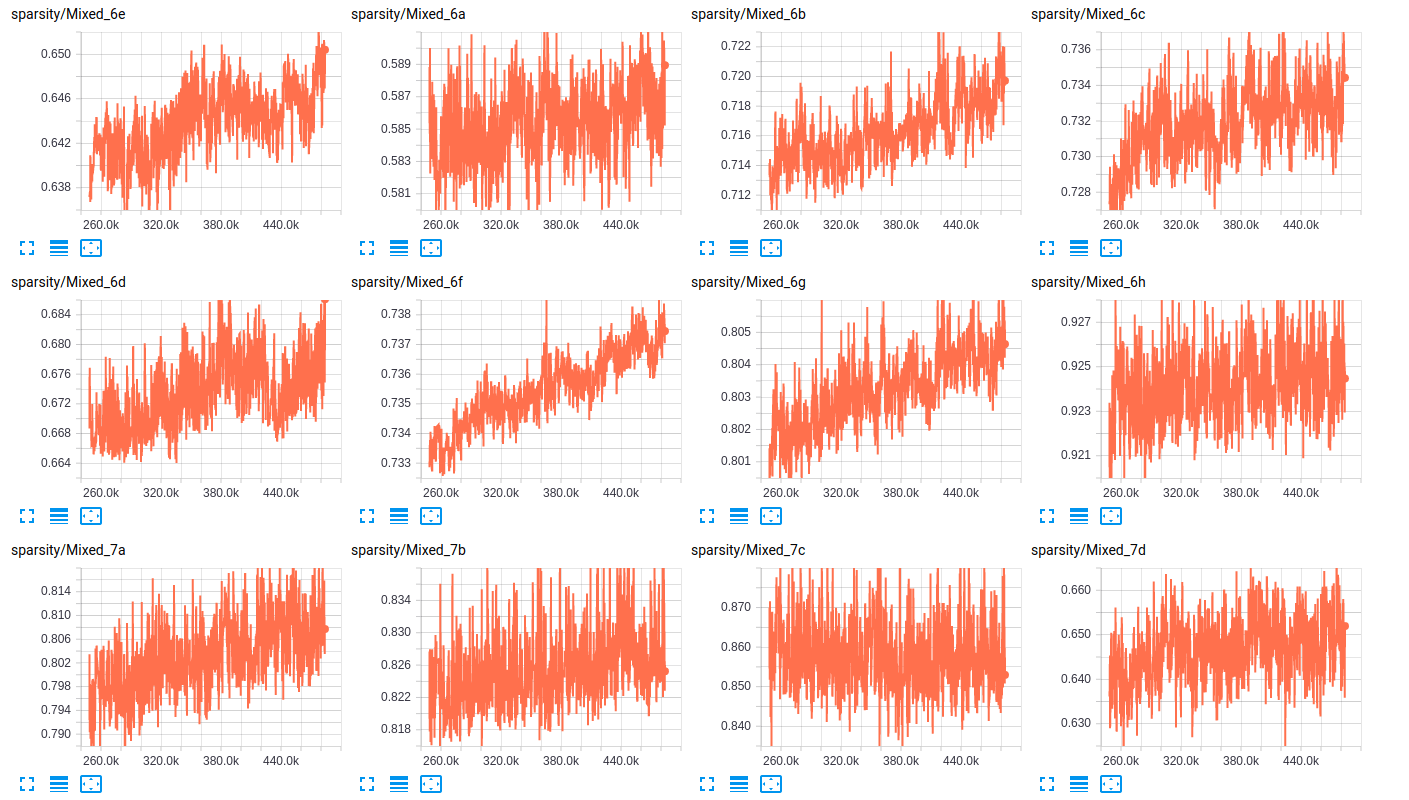
Что касается разреженности слоев, вот несколько примеров разреженности слоев для обеих сетей:
sparsity (InceptionResnet_V2)
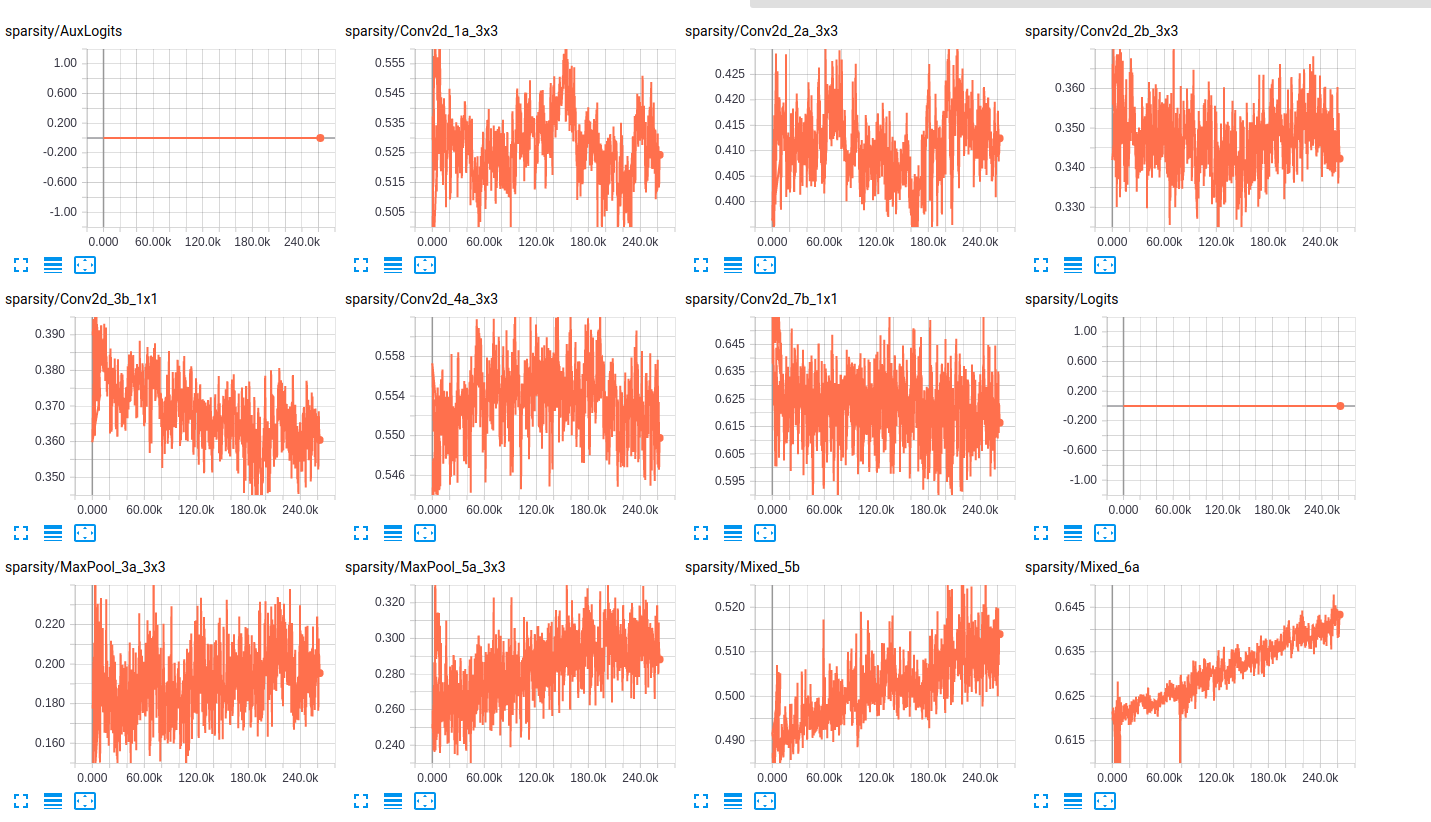
sparsity (InceptionV4)
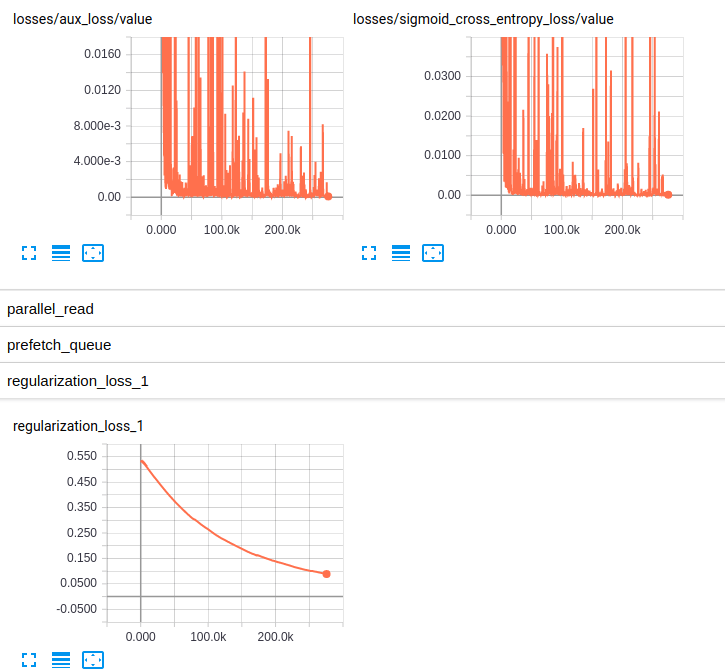
РЕДАКТИРОВАНИЕ 3: Вот графики потерь для обеих моделей:
Losses and regularization loss (InceptionResnet_V2)
Losses and regularization loss (InceptionV4)
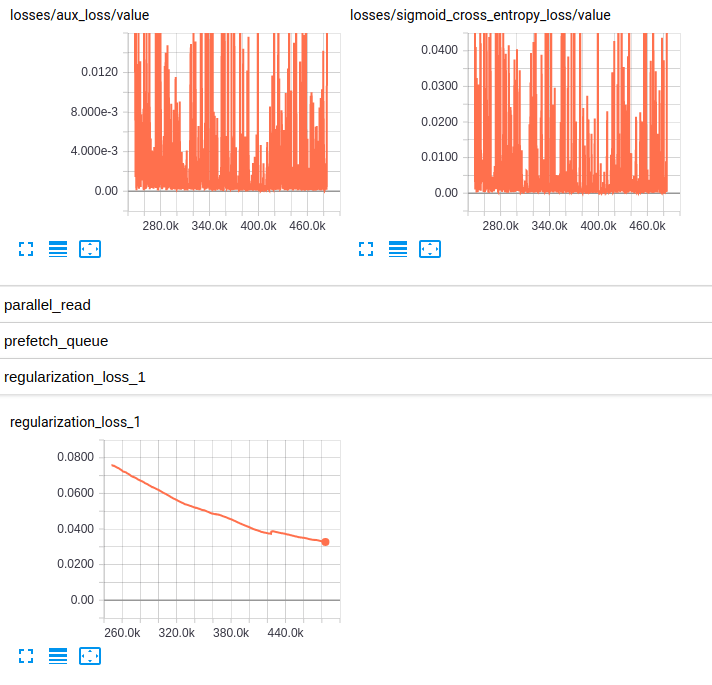
1 ответ
Я согласен с вашей оценкой - вес не сильно меняется в зависимости от мини-партии. Похоже, они несколько меняются.
Я уверен, что вы знаете, что вы делаете тонкую настройку с очень большими моделями. Таким образом, backprop иногда может занять некоторое время. Но вы проводите много обучающих итераций. Я не думаю, что это проблема.
Если я не ошибаюсь, оба они изначально проходили обучение в ImageNet. Если ваши изображения находятся в совершенно другой области, чем в ImageNet, это может объяснить проблему.
Уравнения backprop облегчают изменение смещений при определенных диапазонах активации. ReLU может быть равен единице, если модель очень разрежена (т. Е. Если у многих слоев значения активации равны 0, то веса будут трудно корректировать, но смещения не будут). Кроме того, если активации находятся в диапазоне [0, 1]градиент по отношению к весу будет выше, чем градиент по отношению к смещению. (Вот почему сигмоид является плохой функцией активации).
Это также может быть связано с вашим уровнем считывания - в частности, с функцией активации. Как вы рассчитываете ошибку? Это проблема классификации или регрессии? Если это вообще возможно, я рекомендую использовать что-то кроме sigmoid в качестве финальной функции активации. Тан может быть немного лучше. Линейное считывание иногда также ускоряет обучение (все градиенты должны "проходить" через слой считывания. Если производная слоя считывания всегда 1 - линейная - вы "пропускаете больше градиента", чтобы отрегулировать веса дальше вниз). модель).
Наконец, я замечаю, что ваши гистограммы весов подталкивают к отрицательным весам. Иногда, особенно с моделями, которые имеют много активации ReLU, это может быть индикатором разреженности обучения модели. Или индикатор проблемы мертвых нейронов. Или оба - оба в некоторой степени связаны.
В конечном счете, я думаю, что ваша модель просто пытается учиться. Я столкнулся с очень похожими гистограммами Переучивания Inception. Я использовал набор данных из примерно 2000 изображений, и я изо всех сил пытался увеличить его точность до 80% (как это происходит, набор данных был сильно смещен - эта точность была примерно так же хороша, как случайное угадывание). Это помогло, когда я установил постоянные переменные свертки и внес изменения только в полностью связанный слой.
Действительно, это проблема классификации, и сигмоидальная перекрестная энтропия является подходящей функцией активации. И у вас есть значительный набор данных - конечно, достаточно большой, чтобы точно настроить эти модели.
С этой новой информацией я бы предложил снизить начальную скорость обучения. У меня есть двоякое рассуждение здесь:
(1) это мой собственный опыт. Как я уже говорил, я не особенно знаком с RMSprop. Я использовал его только в контексте DNC (хотя DNC с сверточными контроллерами), но мой опыт подтверждает то, что я собираюсь сказать. Я думаю .01 высока для обучения модели с нуля, не говоря уже о тонкой настройке. Это определенно высоко для Адама. В некотором смысле, начинание с небольшой скорости обучения является "тонкой" частью тонкой настройки. Не заставляйте весы сдвигаться так сильно. Особенно, если вы настраиваете всю модель, а не последний (несколько) слоев.
(2) это увеличение разреженности и сдвиг в сторону отрицательных весов. Исходя из ваших разреженных графиков (кстати,хорошая идея), мне кажется, что некоторые веса могут застрять в разреженной конфигурации в результате чрезмерной коррекции. То есть, в результате высокой начальной скорости, веса "превышают" свою оптимальную позицию и застревают где-то, что затрудняет их восстановление и внесение вклада в модель. То есть слегка отрицательное и близкое к нулю, не хорошо в сети ReLU.
Как я уже упоминал (неоднократно), я не очень знаком с RMSprop. Но, поскольку вы уже выполняете много обучающих итераций, начните с низких, низких и низких начальных ставок и продолжайте расти. Я имею ввиду, посмотри как 1e-8 работает. Вполне возможно, что модель не будет реагировать на обучение с такой низкой скоростью, но сделает что-то вроде неформального поиска гиперпараметра со скоростью обучения. По моему опыту с начала с использованием Адама, 1e-4 в 1e-8 работал хорошо.