Применить MASS::fitdistr к нескольким данным с коэффициентом
Мой вопрос в конце выделен жирным шрифтом.
Я знаю, как приспособить бета-версию к некоторым данным. Например:
library(Lahman)
library(dplyr)
# clean up the data and calculate batting averages by playerID
batting_by_decade <- Batting %>%
filter(AB > 0) %>%
group_by(playerID, Decade = round(yearID - 5, -1)) %>%
summarize(H = sum(H), AB = sum(AB)) %>%
ungroup() %>%
filter(AB > 500) %>%
mutate(average = H / AB)
# fit the beta distribution
library(MASS)
m <- MASS::fitdistr(batting_by_decade$average, dbeta,
start = list(shape1 = 1, shape2 = 10))
alpha0 <- m$estimate[1]
beta0 <- m$estimate[2]
# plot the histogram of data and the beta distribution
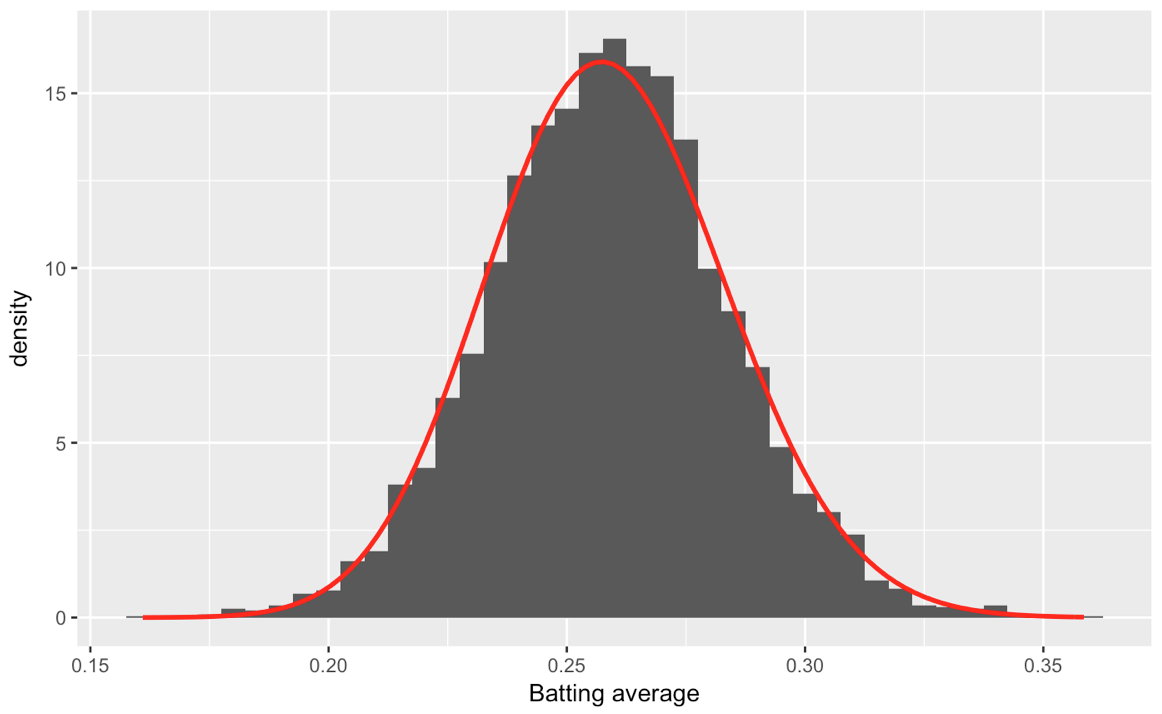
ggplot(career_filtered) +
geom_histogram(aes(average, y = ..density..), binwidth = .005) +
stat_function(fun = function(x) dbeta(x, alpha0, beta0), color = "red",
size = 1) +
xlab("Batting average")
Который дает:
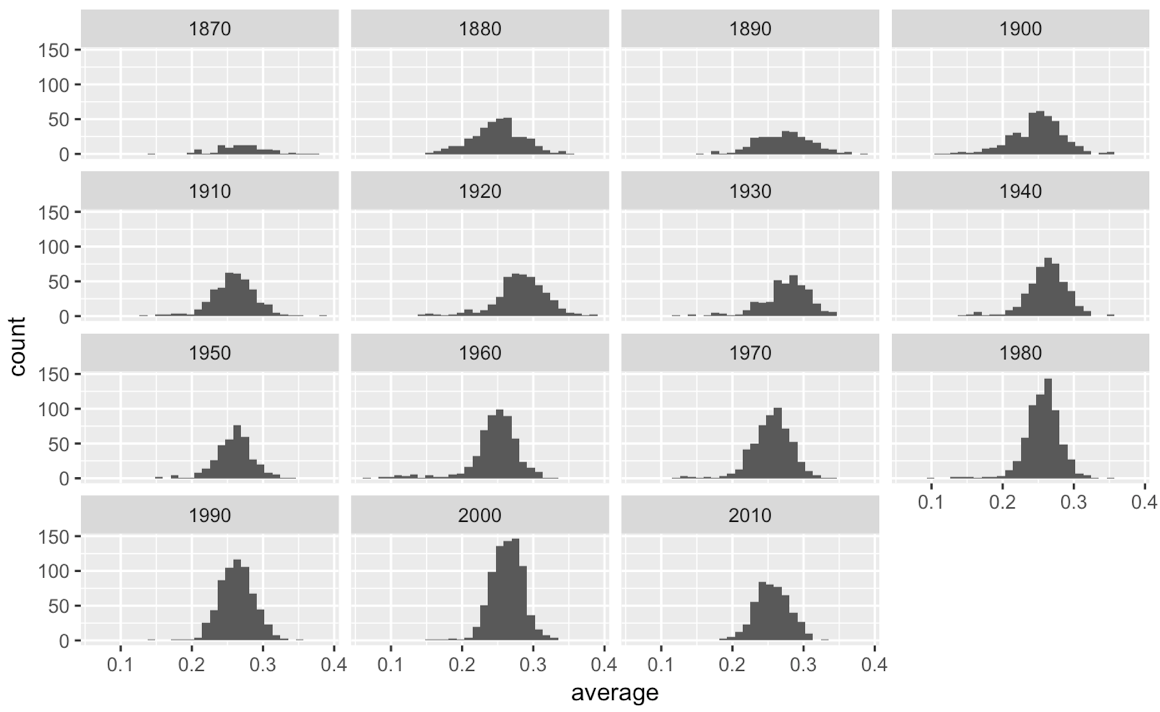
Теперь я хочу рассчитать разные бета-параметры alpha0 а также beta0 для каждого batting_by_decade$Decade столбец данных, так что я получаю 15 наборов параметров и 15 бета-распределений, которые я могу вписать в этот ggplot средних значений ватина, с которыми сталкивается Decade:
batting_by_decade %>%
ggplot() +
geom_histogram(aes(x=average)) +
facet_wrap(~ Decade)
Я могу жестко запрограммировать это, отфильтровывая каждое десятилетие и передавая данные этого десятилетия в fidistr функция, повторяя это в течение всех десятилетий, но есть ли способ быстро и воспроизводимо рассчитать все бета-параметры за десятилетие, возможно, с помощью одной из применяемых функций?
3 ответа
Вы можете использовать summarise вместе с двумя пользовательскими функциями для этого:
getAlphaEstimate = function(x) {MASS::fitdistr(x, dbeta,start = list(shape1 = 1, shape2 = 10))$estimate[1]}
getBetaEstimate = function(x) {MASS::fitdistr(x, dbeta,start = list(shape1 = 1, shape2 = 10))$estimate[2]}
batting_by_decade %>%
group_by(Decade) %>%
summarise(alpha = getAlphaEstimate(average),
beta = getBetaEstimate(average)) -> decadeParameters
Тем не менее, вы не сможете построить его с stat_summary согласно сообщению Хэдли здесь: /questions/38796148/ispolzuya-statfunction-i-facetwrap-vmeste-v-ggplot2-v-r/38796161#38796161
Вот пример того, как вы бы пошли от создания фиктивных данных вплоть до построения графиков.
temp.df <- data_frame(yr = 10*187:190,
al = rnorm(length(yr), mean = 4, sd = 2),
be = rnorm(length(yr), mean = 10, sd = 2)) %>%
group_by(yr, al, be) %>%
do(data_frame(dats = rbeta(100, .$al, .$be)))
Сначала я составил некоторые параметры шкалы за четыре года, сгруппированные по каждой комбинации, а затем использовал do создать фрейм данных со 100 выборками из каждого дистрибутива. Помимо знания "истинных" параметров, этот фрейм данных должен быть очень похож на ваши исходные данные: вектор выборок с соответствующим годом.
temp.ests <- temp.df %>%
group_by(yr, al, be) %>%
summarise(ests = list(MASS::fitdistr(dats, dbeta, start = list(shape1 = 1, shape2 = 1))$estimate)) %>%
unnest %>%
mutate(param = rep(letters[1:2], length(ests)/2)) %>%
spread(key = param, value = ests)
Это основная часть вашего вопроса здесь, очень многое решено так, как вы решили его. Если вы пройдете этот фрагмент за строкой, то увидите, что у вас есть фрейм данных со столбцом типа list, содержащий <dbl [2]> в каждом ряду. Когда ты unnest() он разбивает эти два числа на отдельные строки, поэтому мы идентифицируем их, добавляя столбец с надписью "a, b, a, b, ..." и spread их обратно на части, чтобы получить две колонки с одним рядом для каждого года. Здесь вы также можете увидеть, насколько близко fitdistr соответствует истинной популяции, из которой мы выбрали a против al а также b против be,
temp.curves <- temp.ests %>%
group_by(yr, al, be, a, b) %>%
do(data_frame(prop = 1:99/100,
trueden = dbeta(prop, .$al, .$be),
estden = dbeta(prop, .$a, .$b)))
Теперь мы вывернем этот процесс наизнанку, чтобы сгенерировать данные для построения кривых. Для каждого ряда мы используем do сделать фрейм данных с последовательностью значений propи рассчитать бета-плотность для каждого значения как для истинных параметров популяции, так и для наших расчетных параметров выборки.
ggplot() +
geom_histogram(data = temp.df, aes(dats, y = ..density..), colour = "black", fill = "white") +
geom_line(data = temp.curves, aes(prop, trueden, color = "population"), size = 1) +
geom_line(data = temp.curves, aes(prop, estden, color = "sample"), size = 1) +
geom_text(data = temp.ests,
aes(1, 2, label = paste("hat(alpha)==", round(a, 2))),
parse = T, hjust = 1) +
geom_text(data = temp.ests,
aes(1, 1, label = paste("hat(beta)==", round(b, 2))),
parse = T, hjust = 1) +
facet_wrap(~yr)
Наконец, мы собрали его вместе, построив гистограмму наших выборочных данных. Затем линия из наших данных кривой для истинной плотности. Затем линия из наших данных кривой для нашей предполагаемой плотности. Затем некоторые метки из наших параметров оценивают данные, чтобы показать параметры выборки и фасеты по годам.

Это подходящее решение, но я предпочитаю решение dplyr @CMichael.
calc_beta <- function(decade){
dummy <- batting_by_decade %>%
dplyr::filter(Decade == decade) %>%
dplyr::select(average)
m <- fitdistr(dummy$average, dbeta, start = list(shape1 = 1, shape2 = 10))
alpha0 <- m$estimate[1]
beta0 <- m$estimate[2]
return(c(alpha0,beta0))
}
decade <- seq(1870, 2010, by =10)
params <- sapply(decade, calc_beta)
colnames(params) <- decade
Re: @ CMichael комментарий о том, как избежать двойного fitdistrмы могли бы переписать функцию getAlphaBeta,
getAlphaBeta = function(x) {MASS::fitdistr(x, dbeta,start = list(shape1 = 1, shape2 = 10))$estimate}
batting_by_decade %>%
group_by(Decade) %>%
summarise(params = list(getAlphaBeta(average))) -> decadeParameters
decadeParameters$params[1] # it works!
Теперь нам просто нужно убрать второй столбец хорошим способом....