R соответствует двойной экспоненциальной кривой роста
Я пытаюсь соответствовать двойной экспоненциальной кривой роста в форме y = a1*exp(b1*x)+a2*exp(b2*x) для заданного набора данных, с nlsОднако я всегда получаю любую из ошибок
(1) Ошибка сходимости: ложная сходимость
(2) особый градиент.
Я обеспокоен тем, как выбрать параметры запуска.
dput(data)
structure(list(x = c(945.215200958252, 841.160401229858, 756.464001846314,
761.525999221802, 858.50640007019, 986.62599899292, 971.313199462891,
849.174199714661, 776.209600372315, 723.809600753784, 976.608401947022,
984.150799865723, 918.562801513672, 806.130400238037, 669.209998245239,
997.029203643799, 946.925600280762, 952.693200378418, 908.331200637817,
759.581600265503), y = c(2504.35798767332, 1393.74419037031,
801.352724934674, 594.595314570309, 545.238493983611, 3096.99909306567,
2335.01775505392, 1090.89140859095, 640.612753846014, 515.489681719953,
3609.04419294434, 3119.35657562002, 1458.34041207895, 679.989754325102,
496.516167617315, 4239.49376527158, 3250.19182566731, 2025.87274302584,
894.559293335184, 571.966366494787), c = c(2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L),
id = 1:20), .Names = c("x", "y", "c", "id"), class = "data.frame", row.names = c("1",
"2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12", "13",
"14", "15", "16", "17", "18", "19", "20"))
И скрипт для поиска лучших начальных параметров
mfit=nls(y ~ a1*exp(b1*x)+a2*exp(b2*x),data,
start=list(a1=0.125,a2=0.16,b1=0.010,b2=0.005),
algorithm="port",trace=TRUE)
Когда я пытался построить график, вручную я вижу график, как показано ниже: 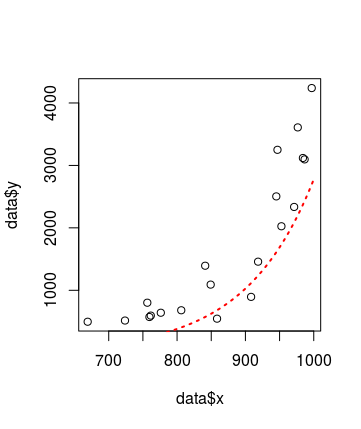
1 ответ
Почему вы предполагаете, что эти данные должны соответствовать двойной экспоненте? Когда мы подаем заявку mexpfit из пакета Pracma к ним (X-, Y-координаты), то мы получаем один a а также b ценности:
> mexpfit(ex$x, ex$y, p0=c(0.1, 0.1), const=FALSE)
## $a0
## [1] 0
## $a
## [1] 0.4784374
## $b
## [1] 0.008983063
## $ssq
## [1] 3653990
## $iter
## [1] 12
## $errmess
## [1] "Stopped by small x-step."
что означает, что простая экспоненциальная кривая является лучшим приближением, чем двойная экспонента.
nls Функция печально известна своими сообщениями "единственного градиента". Вместо этого используйте его предполагаемую замену nlxb из пакета nlsr.
> nlsr::nlxb(y ~ a1*exp(b1*x)+a2*exp(b2*x),
start=c(a1=0.125,a2=0.16,b1=0.010,b2=0.005), data=data)
## vn:[1] "y" "a1" "b1" "x" "a2" "b2"
## no weights
## nlsr object: x
## residual sumsquares = 3653990 on 20 observations
## after 18 Jacobian and 25 function evaluations
## name coeff SE tstat pval gradient JSingval
## a1 0.478215 NA NA NA -457.7 8736009
## a2 12.0676 NA NA NA -5.967e-15 810.1
## b1 0.00898354 NA NA NA -204286 1.514e-13
## b2 -0.0575306 NA NA NA -4.838e-11 0
Это решение имеет точно такую же "сумму квадратов", что и решение, приведенное выше, и является квази-"численно идентичным" в данной области значений x.