Добавить легенду для точечного графика (PCA)
Я новичок в Python и нашел это отличное предложение для биплота PCA ( загрузка загрузок PCA и загрузка в биплот в sklearn (как автоплот R)). Теперь я попытался добавить легенду к сюжету для разных целей. Но команда plt.legend() не работает
Есть ли простой способ сделать это? В качестве примера приведены данные радужной оболочки с кодом биплота по ссылке выше.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.decomposition import PCA
import pandas as pd
from sklearn.preprocessing import StandardScaler
iris = datasets.load_iris()
X = iris.data
y = iris.target
#In general a good idea is to scale the data
scaler = StandardScaler()
scaler.fit(X)
X=scaler.transform(X)
pca = PCA()
x_new = pca.fit_transform(X)
def myplot(score,coeff,labels=None):
xs = score[:,0]
ys = score[:,1]
n = coeff.shape[0]
scalex = 1.0/(xs.max() - xs.min())
scaley = 1.0/(ys.max() - ys.min())
plt.scatter(xs * scalex,ys * scaley, c = y)
for i in range(n):
plt.arrow(0, 0, coeff[i,0], coeff[i,1],color = 'r',alpha = 0.5)
if labels is None:
plt.text(coeff[i,0]* 1.15, coeff[i,1] * 1.15, "Var"+str(i+1), color = 'g', ha = 'center', va = 'center')
else:
plt.text(coeff[i,0]* 1.15, coeff[i,1] * 1.15, labels[i], color = 'g', ha = 'center', va = 'center')
plt.xlim(-1,1)
plt.ylim(-1,1)
plt.xlabel("PC{}".format(1))
plt.ylabel("PC{}".format(2))
plt.grid()
#Call the function. Use only the 2 PCs.
myplot(x_new[:,0:2],np.transpose(pca.components_[0:2, :]))
plt.show()
Любые предложения для болтов PCA приветствуются! Также другие коды, если добавление легенды проще по-другому!
1 ответ
Недавно я предложил простой способ добавить легенду к скаттеру, см. GitHub PR. Это все еще обсуждается.
А пока вам нужно вручную создать легенду из уникальных ярлыков в y, Для каждого из них вы бы создали Line2D объект с тем же маркером, который используется на диаграмме рассеяния, и предоставить их в качестве аргумента plt.legend,
scatter = plt.scatter(xs * scalex,ys * scaley, c = y)
labels = np.unique(y)
handles = [plt.Line2D([],[],marker="o", ls="",
color=scatter.cmap(scatter.norm(yi))) for yi in labels]
plt.legend(handles, labels)
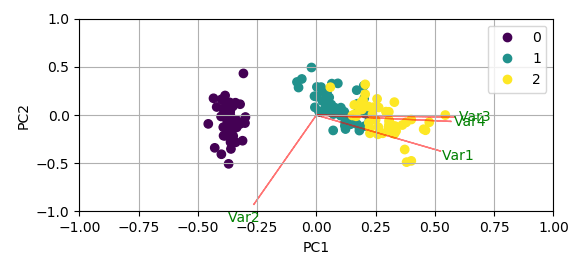
Попробуйте библиотеку "PCA". Это будет отображать объясненную дисперсию и создать двойной график.
pip install pca
from pca import pca
# Initialize to reduce the data up to the number of componentes that explains 95% of the variance.
model = pca(n_components=0.95)
# Or reduce the data towards 2 PCs
model = pca(n_components=2)
# Load example dataset
import pandas as pd
import sklearn
from sklearn.datasets import load_iris
X = pd.DataFrame(data=load_iris().data, columns=load_iris().feature_names, index=load_iris().target)
# Fit transform
results = model.fit_transform(X)
# Plot explained variance
fig, ax = model.plot()

# Scatter first 2 PCs
fig, ax = model.scatter()
# Make biplot with the number of features
fig, ax = model.biplot(n_feat=4)

Результатом является dict, содержащий множество статистических данных о ПК, загрузках и т. Д.