Удаление левой рекурсии в DCG - Пролог
У меня небольшая проблема с левой рекурсией в этой грамматике. Я пытаюсь написать это в Прологе, но я не знаю, как удалить левую рекурсию.
<expression> -> <simple_expression>
<simple_expression> -> <simple_expression> <binary_operator> <simple_expression>
<simple_expression> -> <function>
<function> -> <function> <atom>
<function> -> <atom>
<atom> -> <number> | <variable>
<binary_operator> -> + | - | * | /
expression(Expr) --> simple_expression(SExpr), { Expr = SExpr }.
simple_expression(SExpr) --> simple_expression(SExpr1), binary_operator(Op), simple_expression(SExpr2), { SExpr =.. [Op, SExpr1, SExpr2] }.
simple_expression(SExpr) --> function(Func), { SExpr = Func }.
function(Func) --> function(Func2), atom(At), { Func = [Func2, atom(At)] }.
function(Func) --> atom(At), { Func = At }.
Я написал что-то подобное, но это не сработает вообще. Как изменить это, чтобы заставить эту программу работать?
4 ответа
Проблема возникает только потому, что вы используете обратную цепочку. В прямом связывании можно напрямую работать с правилами левой рекурсивной грамматики. Приведены правила грамматики вида:
NT ==> NT'
Не формируйте цикл. Вы также можете использовать вспомогательные вычисления, т.е. {}/1, если вы размещаете их после нетерминалов тела и если нетерминалы в голове не имеют параметров, входящих исключительно во вспомогательные вычисления. то есть восходящее условие.
Вот пример левой рекурсивной грамматики, которая отлично работает таким образом в цепочке вперед:
:- use_module(library(minimal/chart)).
:- use_module(library(experiment/ref)).
:- static 'D'/3.
expr(C) ==> expr(A), [+], term(B), {C is A+B}.
expr(C) ==> expr(A), [-], term(B), {C is A-B}.
expr(A) ==> term(A).
term(C) ==> term(A), [*], factor(B), {C is A*B}.
term(C) ==> term(A), [/], factor(B), {C is A/B}.
term(A) ==> factor(A).
factor(A) ==> [A], {integer(A)}.
Вот ссылка на исходный код парсера диаграмм. По этой ссылке также можно найти исходный код прямого цепочника. Ниже показан пример сеанса:
?- use_module(library(minimal/hypo)).
?- chart([1,+,2,*,3], N) => chart(expr(X), N).
X = 7
Во время синтаксического анализа анализатор диаграммы будет заполнять диаграмму снизу вверх. Для каждого нетерминального p/n в вышеприведенных постановках будут факты p/n+2. Вот результат диаграммы для приведенного выше примера:
:- thread_local factor/3.
factor(3, 4, 5).
factor(2, 2, 3).
factor(1, 0, 1).
:- thread_local term/3.
term(3, 4, 5).
term(2, 2, 3).
term(6, 2, 5).
term(1, 0, 1).
:- thread_local expr/3.
expr(3, 4, 5).
expr(2, 2, 3).
expr(6, 2, 5).
expr(1, 0, 1).
expr(3, 0, 3).
expr(7, 0, 5).
Проблема с вашей программой - действительно левая рекурсия; он должен быть удален, иначе вы застрянете в бесконечном цикле
Чтобы удалить немедленную левую рекурсию, вы заменяете каждое правило формы
A->A a1|A a2|....|b1|b2|....
с:
A -> b1 A'|b2 A'|....
A' -> ε | a1 A'| a2 A'|....
так что функция будет
function -> atom, functionR.
funtionR -> [].
Многие системы Prolog предоставляют табулирование. С табулированием прекращение также может быть распространено на левую рекурсивную грамматику во многих ситуациях. Вот решение, которое использует новую функцию табулирования SWI-Prolog:
:- use_module(library(tabling)).
:- table expr/3.
:- table term/3.
:- table factor/3.
expr(C) --> expr(A), [+], term(B), {C is A+B}.
expr(C) --> expr(A), [-], term(B), {C is A-B}.
expr(A) --> term(A).
term(C) --> term(A), [*], factor(B), {C is A*B}.
term(C) --> term(A), [/], factor(B), {C is A/B}.
term(A) --> factor(A).
factor(A) --> [A], {integer(A)}.
Поскольку эта функция является относительно новой в SWI-Prolog, она работает только в тот момент, когда вы включаете режим отладки:
?- debug.
?- phrase(expr(X), [1,+,2,*,3], []).
X = 7
Ответ @thanosQR довольно хороший, но он относится к более общему контексту, чем DCG, и требует изменения в дереве разбора. Фактически, "результат" анализа был удален, это не хорошо.
Если вас интересует только разбор выражений, я разместил здесь кое-что полезное.
Программирование набора ответов (ASP) предоставляет другой способ реализации грамматик. ASP может быть реализован с недетерминированной прямой цепочкой, и это то, что предоставляет наша библиотека (minimal/asp). Результатом ASP являются разные модели
данных правил. Мы используем здесь модели ASP для представления диаграммы Кок-Янгера-Касами. Мы начинаем нашу диаграмму с заданных слов, которые мы хотим проанализировать, которые представлены фактами word/3. По сравнению с DCG мы больше не обходимся
списки, но вместо позиций слов. Текст на языке Prolog calc2.p показывает такую реализацию синтаксического анализатора на основе ASP. Все правила теперь (<=)/2 правила, что означает, что они являются правилами прямой цепочки. И все головы теперь выбирают / 1 голов, означает, что они делают ASP
выбор модели. Мы объясняем, как реализуется выражение, термин реализуется аналогично. Поскольку у нас нет автоматического перевода, мы сделали перевод вручную. Мы будем вводить слова справа налево и запускать только в начале
каждого приписанного грамматического правила:
choose([expr(C, I, O)]) <= posted(expr(A, I, H)), word('+', H, J), term(B, J, O), C is A+B.
choose([expr(C, I, O)]) <= posted(expr(A, I, H)), word('-', H, J), term(B, J, O), C is A-B.
choose([expr(B, I, O)]) <= posted(word('-', I, H)), term(A, H, O), B is -A.
choose([expr(A, I, O)]) <= posted(term(A, I, O)).
Как видно, дополнительный предикат expr_rest не требовался, а перевод из грамматики в правила был 1-1. То же самое и со сроком. Выполнение такой грамматики требует, чтобы сначала слова были размещены справа налево, и результат может
затем считывать с соответствующего нетерминала:
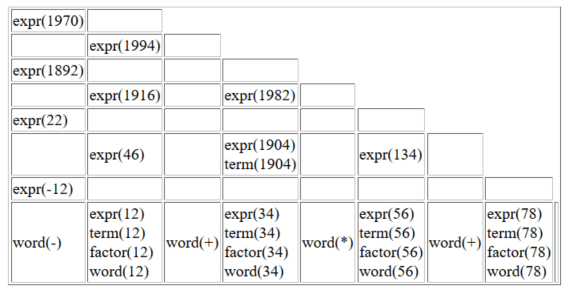
?- post(word(78,7,8)), post(word('+',6,7)), post(word(56,5,6)), post(word('*',4,5)),
post(word(34,3,4)), post(word('+',2,3)), post(word(12,1,2)), post(word('-',0,1)),
expr(X,0,8).
X = 1970
Мы также сделали текст show.p на языке Prolog, который позволяет визуализировать модель ASP в виде диаграммы синтаксического анализа. Мы просто используем обычное представление треугольной матрицы. Диаграмма синтаксического анализа для приведенного выше арифметического выражения выглядит следующим образом:
Питер Шюллер (2018 г.) - Программирование набора ответов в лингвистике
https://peterschueller.com//pub/2018/2018-schueller-asp-linguistics.pdf
Руководство пользователя - модуль "asp"
http://www.jekejeke.ch/idatab/doclet/prod/en/docs/15_min/10_docu/02_reference/07_theory/01_minimal/06_asp.html