Regex Alternation Order
Я установил сложное регулярное выражение для извлечения данных со страницы текста. Почему-то порядок чередования не тот, который я ожидаю. Простой пример будет:
((13th|(Executive |Residential)|((\w+) ){1,3})Floor)
Проще говоря, я пытаюсь либо получить номер этажа, известное имя этажа, и, в качестве резервной копии, я фиксирую 1-3 неизвестных слова, за которыми следует слово этажа на всякий случай, чтобы просмотреть позже (на самом деле я использую имя группы, чтобы определить это но не хотел путать вопрос)
Проблема в том, если строка
on the 13th Floor
Я не понимаю 13th Floor я получил on the 13th Floor который, кажется, указывает, что это соответствует 3-му чередованию. Я ожидал, что это будет соответствовать 13-му этажу. Я настроил это специально (или я так думал), чтобы расставить приоритеты по типам матчей и оставить неопределенные на последний, только если пропущены другие. Я думаю, они не шутили, когда говорили, что Регекс жадный, но мне неясно, как настроить его на "жадность" и вести себя так, как я хочу.
2 ответа
Ну, автомат стоит 1000 слов:
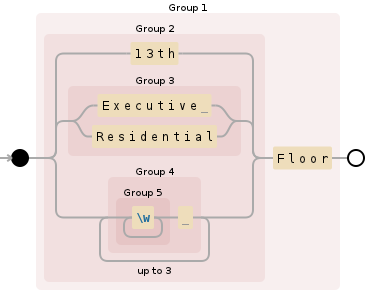
Ваша проблема в том, что вы используете жадный \w+ суб-регулярное выражение в вашем чередовании. Поскольку @rigderunner заявляет в своем комментарии, NFA совпадает с самой длинной левой подстрокой, \w+ всегда будет соответствовать всему, что предшествует Floorбудь то серия слов или 13th или же Executive или же Residential или трое из них. Круглые скобки не меняют поведение чередования.
Таким образом, в худшем случае, если вы не хотите, чтобы он совпадал, это:
xxxx yyyy zzz tttt Floor
Проблема с вашим регулярным выражением состоит в том, что вы ожидаете сделать то, чего не могут сделать обычные регулярные выражения: вы ожидаете, что оно будет соответствовать словам, если альтернативы не сработали. Поскольку обычный язык не может отслеживать статус, регулярное выражение не может выразить это.
Я на самом деле не уверен, что использование какого-либо вида заблаговременности может помочь вам сделать это за одно регулярное выражение, и даже если вы сможете, вы получите очень сложное, нечитаемое и, возможно, даже неэффективное регулярное выражение.
Поэтому вы можете вместо этого использовать два регулярных выражения и получить группы из второго регулярного выражения в случае неудачи первого:
((13th|Executive|Residential) +Floor)
и если нет совпадения
((\w+ +){1:3}Floor)
NB: чтобы не повторяться, пожалуйста, посмотрите на этот другой ответ, где я даю список интересных ресурсов, читающих лекции по регулярным выражениям и NFA. Это поможет вам понять, как на самом деле работает регулярное выражение.
Во-первых, вот ваше регулярное выражение в режиме свободного пространства:
tidied = re.compile(r"""
( # $1: ...
( # $2: One ... from 3 alternatives.
13th # Either a1of3.
| ( # Or a2of3 $3: One ... from 2 alternatives.
Executive[ ] # Either a1of2.
| Residential # Or a2of2.
) # End $3: One ... from 2 alternatives.
| ( # Or a3of3 $4: Last match from 1 to 3 ...
(\w+) # $5: ...
[ ] #
){1,3} # End $4: Last match from 1 to 3 ...
) # End $2: One ... from 3 alternatives.
Floor #
) # End $1: ...
""", re.VERBOSE)
Обратите внимание, что приведенный выше шаблон имеет дополнительные скобки, которые не имеют никакого эффекта. Вот упрощенное выражение, которое функционально эквивалентно:
tidied = re.compile(r"""
( # $1: One ... from 4 alternatives.
13th # Either a1of4.
| Executive[ ] # Or a2of4.
| Residential # Or a3of4.
| ( # Or a4of4 $2: Last match from 1 to 3 ...
(\w+) # $3: ...
[ ] #
){1,3} # End $2: Last match from 1 to 3 ...
) # End $1: One ... from 4 alternatives.
Floor #
""", re.VERBOSE)
Самые длинные левые матчи
По сути, перед требуемым словом есть четыре сгруппированных альтернативы: Floor, Первые три варианта - каждое слово, но четвертый вариант соответствует трем словам. Механизм регулярных выражений NFA работает слева направо и всегда пытается найти самое длинное левое совпадение. В этом случае, когда регулярное выражение проходит через регулярное выражение по одному символу за раз, оно проверяет все четыре параметра в каждой позиции символа. Так как четвертый вариант всегда может сопоставить два слова перед остальными тремя, он всегда будет совпадать первым (при условии, что перед словом стоят три слова) Floor в данном тексте.). Если нет трех слов, предшествующих Floor, тогда может совпадать один из первых трех вариантов.
Обратите также внимание, что после 13th а также Residential альтернативы, таким образом, это будет когда-либо совпадать только тогда, когда представлен текст, имеющий объединенный текст: ResidentialFloor или же 13thFloor,