Как найти все возможные совпадения с регулярным выражением в Python?
Я пытаюсь найти все возможные пары слово / тег или другие вложенные комбинации с python и его регулярными выражениями.
sent = '(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))'
def checkBinary(sentence):
n = re.findall("\([A-Za-z-0-9\s\)\(]*\)", sentence)
print(n)
checkBinary(sent)
Output:
['(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))']
находясь в поиске:
['(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))',
'(NNP Hoi)',
'(NN Hallo)',
'(NN Hey)',
'(NNP (NN Ciao) (NN Adios))',
'(NN Ciao)',
'(NN Adios)']
Я думаю, что формула регулярного выражения также может найти вложенные пары слов / тегов в скобках, но она не возвращает их. Как мне это сделать?
2 ответа
На самом деле это невозможно сделать с помощью регулярных выражений, потому что регулярные выражения выражают язык, определенный с помощью регулярной грамматики, который может быть решен с помощью бесконечного детерминированного автомата, где сопоставление представлено состояниями; затем, чтобы соответствовать вложенным круглым скобкам, вам нужно будет соответствовать бесконечному количеству круглых скобок, а затем иметь автомат с бесконечным числом состояний.
Чтобы справиться с этим, мы используем так называемый автомат с нажатием кнопки вниз, который используется для определения контекстно-свободной грамматики.
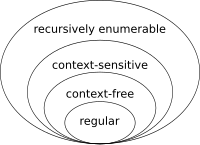
Поэтому, если ваше регулярное выражение не соответствует вложенным круглым скобкам, это потому, что оно выражает следующий автомат и ничего не соответствует вашему вводу:

В качестве ссылки, пожалуйста, посмотрите курсы MIT по этой теме:
- http://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-045j-automata-computability-and-complexity-spring-2011/lecture-notes/MIT6_045JS11_lec04.pdf
- http://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-005-elements-of-software-construction-fall-2011/lecture-notes/MIT6_005F11_lec05.pdf
- http://www.saylor.org/site/wp-content/uploads/2012/01/CS304-2.1-MIT.pdf
Поэтому один из способов эффективного анализа вашей строки - это построить грамматику для вложенных скобок (pip install pyparsing первый):
>>> import pyparsing
>>> strings = pyparsing.Word(pyparsing.alphanums)
>>> parens = pyparsing.nestedExpr( '(', ')', content=strings)
>>> parens.parseString('(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))').asList()
[['NP', ['NNP', 'Hoi'], ['NN', 'Hallo'], ['NN', 'Hey'], ['NNP', ['NN', 'Ciao'], ['NN', 'Adios']]]]
Примечание: существует несколько механизмов регулярных выражений, которые реализуют сопоставление вложенных скобок с помощью нажатия вниз. Python по умолчанию re двигатель не является одним из них, но существует альтернативный двигатель, называемый regex (pip install regex) который может выполнять рекурсивное сопоставление (что делает контекст движка свободным), см. этот фрагмент кода:
>>> import regex
>>> res = regex.search(r'(?<rec>\((?:[^()]++|(?&rec))*\))', '(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))')
>>> res.captures('rec')
['(NNP Hoi)', '(NN Hallo)', '(NN Hey)', '(NN Ciao)', '(NN Adios)', '(NNP (NN Ciao) (NN Adios))', '(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))']
Регулярные выражения, используемые в современных языках, НЕ представляют собой обычные языки. zmo прав, говоря, что обычные языки в Language Theroy представлены автоматами с конечным состоянием, но регулярные выражения, использующие любой вид обратного отслеживания, например, с использованием групп захвата, обходных путей и т. д., которые используются в современных языках, НЕ МОГУТ быть представлены FSA, известными в Language Теория. Как вы можете представить шаблон как (\w+)\1 с DFA или даже и NFA?
Требуемое регулярное выражение может выглядеть примерно так (соответствует только двум уровням):
(?=(\((?:[^\)\(]*\([^\)]*\)|[^\)\(])*?\)))
Я проверял это на http://regexhero.net/tester/
Матчи в захваченных группах:
1: (NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios))
1: (NNP Hoi)
1: (NN Hallo)
1: (NN Эй)
1: (NNP (NN Ciao) (NN Adios))
1: (NN Ciao)
1: (NN Adios)