Что такое "семантическая сегментация" по сравнению с "сегментацией" и "маркировкой сцены"?
Является ли семантическая сегментация просто плеоназмом или есть разница между "семантической сегментацией" и "сегментацией"? Есть ли разница в "маркировке сцен" или "разборе сцен"?
В чем разница между пиксельным уровнем и пиксельной сегментацией?
(Дополнительный вопрос: если у вас есть подобная попиксельная аннотация, вы получаете обнаружение объекта бесплатно или еще есть чем заняться?)
Пожалуйста, дайте источник для ваших определений.
Источники, которые используют "семантическую сегментацию"
- Джонатан Лонг, Эван Шелхамер, Тревор Даррелл: полностью сверточные сети для семантической сегментации. CVPR, 2015 и PAMI, 2016
- Hong, Seunghoon, Hyeonwoo Noh и Bohyung Han: "Разделенная глубокая нейронная сеть для семантической сегментации под наблюдением". Препринт arXiv arXiv: 1506.04924, 2015.
- В. Лемпицкий, А. Ведальди и А. Циссерман: модель пилона для семантической сегментации. Достижения в области нейронных систем обработки информации, 2011.
Источники, которые используют "маркировку сцены"
- Клемент Фарабет, Камиль Купри, Лоран Наджман, Янн ЛеКун: Изучение иерархических особенностей для маркировки сцен. В анализе образцов и машинном интеллекте, 2013.
Источник, который использует "уровень пикселей"
- Пинейро, Педро О. и Ронан Коллоберт: "От уровня изображения до маркировки на уровне пикселей с помощью сверточных сетей". Материалы конференции IEEE по компьютерному зрению и распознаванию образов, 2015 г. (см. http://arxiv.org/abs/1411.6228).
Источник, использующий "пиксельно"
- Ли, Хуншен, Руи Чжао и Сяоган Ван: "Высокоэффективное прямое и обратное распространение сверточных нейронных сетей для пиксельной классификации". Препринт arXiv arXiv: 1412.4526, 2014.
Google Ngrams
"Семантическая сегментация" в последнее время более широко используется, чем "маркировка сцен"
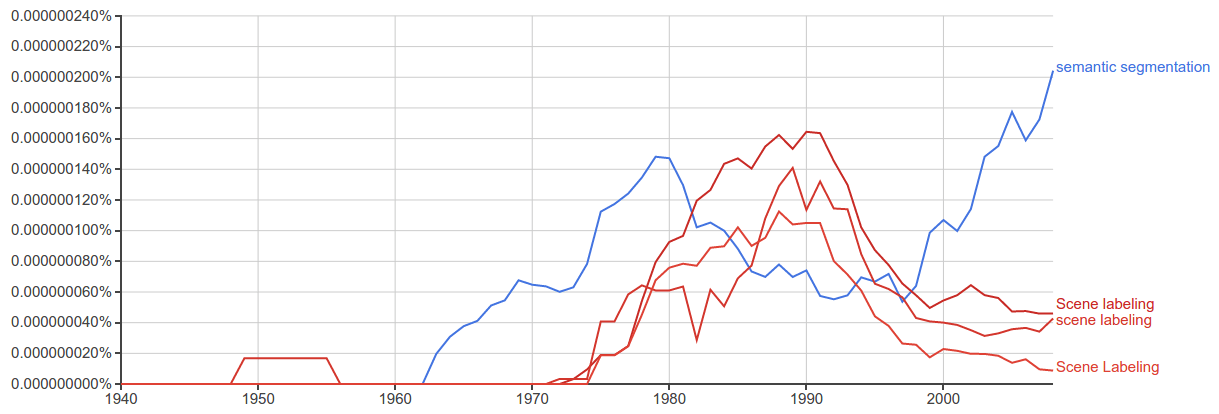
3 ответа
"Сегментация" - это разделение изображения на несколько "связных" частей, но без какой-либо попытки понять, что представляют собой эти части. Одной из самых известных работ (но определенно не первой) является " PAMI 2000" Ши и Малика "Нормализованные срезы и сегментация изображения". В этих работах делается попытка определить "согласованность" в терминах сигналов низкого уровня, таких как цвет, текстура и гладкость границы. Вы можете проследить эти работы до теории Гештальта.
С другой стороны, "семантическая сегментация" пытается разделить изображение на семантически значимые части и классифицировать каждую часть в один из заранее определенных классов. Вы также можете достичь той же цели, классифицируя каждый пиксель (а не все изображение / сегмент). В этом случае вы делаете попиксельную классификацию, которая приводит к тому же конечному результату, но по несколько другому пути...
Итак, я полагаю, вы можете сказать, что "семантическая сегментация", "маркировка сцены" и "пиксельная классификация" в основном пытаются достичь одной и той же цели: семантического понимания роли каждого пикселя в изображении. Вы можете пойти разными путями, чтобы достичь этой цели, и эти пути приводят к небольшим нюансам в терминологии.
Я прочитал много статей об обнаружении объектов, распознавании объектов, сегментации объектов, сегментации изображений и сегментации семантических изображений, и вот мои выводы, которые могут быть неверными:
Распознавание объектов: в данном изображении вы должны обнаружить все объекты (ограниченный класс объектов зависит от вашего набора данных), локализовать их с помощью ограничительной рамки и пометить эту ограничительную рамку с помощью метки. На изображении ниже вы увидите простой вывод информации о состоянии объекта распознавания.

Обнаружение объектов: это похоже на распознавание объектов, но в этой задаче у вас есть только два класса классификации объектов, которые означают ограничивающие прямоугольники объекта и ограничивающие прямоугольники объекта. Например, Обнаружение автомобиля: вы должны Обнаружить все автомобили на заданном изображении с помощью их ограничительных рамок.

Сегментация объектов: Как и при распознавании объектов, вы узнаете все объекты на изображении, но в выходных данных должен отображаться объект, классифицирующий пиксели изображения.

Сегментация изображения: при сегментации изображения вы сегментируете области изображения. ваш вывод не будет помечать сегменты и области изображения, которые согласуются друг с другом, должны быть в одном сегменте. Извлечение суперпикселей из изображения является примером этой задачи или сегментации фона на переднем плане.

Семантическая сегментация: В семантической сегментации вы должны пометить каждый пиксель классом объектов (Автомобиль, Человек, Собака,...) и не-объектами (Вода, Небо, Дорога,...). Другими словами, в семантической сегментации вы будете обозначать каждую область изображения.

Я думаю, что пиксельный уровень и пиксельная маркировка в основном одинаковы, это может быть сегментация изображения или семантическая сегментация. Я также ответил на ваш вопрос в этой ссылке как то же самое.
Предыдущие ответы действительно хороши, я хотел бы отметить еще несколько дополнений:
Сегментация объектов
одна из причин, по которой он потерял популярность в исследовательском сообществе, заключается в том, что он проблематичен. Сегментация объектов используется просто для обозначения нахождения одного или небольшого количества объектов на изображении и рисования границы вокруг них, и для большинства целей все еще можно предположить, что это означает это. Тем не менее, оно также стало использоваться для обозначения сегментации больших двоичных объектов, которые могут быть объектами, сегментации объектов из фона (чаще называемой теперь вычитанием фона или сегментацией фона или обнаружением на переднем плане), и даже в некоторых случаях используется взаимозаменяемо с распознаванием объектов с использованием ограничивающие рамки (это быстро прекратилось с появлением глубоких нейронных сетевых подходов к распознаванию объектов, но предварительное распознавание объектов также может означать просто маркировку всего изображения с объектом в нем).
Что делает "сегментация" "семантической"?
Simpy, каждому сегменту или, в случае глубоких методов, каждому пикселю присваивается метка класса на основе категории. Сегментация в целом - это просто деление изображения по некоторому правилу. Сегментация по среднему сдвигу, например, с очень высокого уровня делит данные в соответствии с изменениями энергии изображения. Сегментация, основанная на разрезе графа, аналогичным образом не изучается, но напрямую выводится из свойств каждого изображения отдельно от остальных. Более поздние (основанные на нейронных сетях) методы используют пиксели, которые помечены, чтобы научиться идентифицировать локальные особенности, которые связаны с конкретными классами, а затем классифицировать каждый пиксель на основе того, какой класс имеет наибольшую достоверность для этого пикселя. Таким образом, "маркировка пикселей" на самом деле является более честным названием для задачи, а компонент "сегментация" является эмерджентным.
Сегментация экземпляра
Возможно, самое сложное, уместное и оригинальное значение сегментации объектов, "сегментация экземпляров", означает сегментацию отдельных объектов в сцене независимо от того, относятся ли они к одному типу. Однако одна из причин, по которой это так сложно, состоит в том, что с точки зрения видения (и в некотором смысле философского) то, что делает экземпляр объекта, не совсем понятно. Являются ли части тела объектами? Должны ли такие "составные объекты" быть сегментированы вообще алгоритмом сегментации экземпляра? Должны ли они быть сегментированными, только если они рассматриваются отдельно от целого? Как насчет составных объектов, если две вещи четко примыкают, но могут быть отделены друг от друга, то есть один или два объекта (это камень, приклеенный к вершине палки топором, молотком или просто палкой и камнем, если они не сделаны должным образом?). Также не ясно, как различать экземпляры. Является ли завещание отдельным экземпляром от других стен, к которым оно прикреплено? В каком порядке должны учитываться экземпляры? Как они появляются? Близость к точке зрения? Несмотря на эти трудности, сегментация объектов все еще имеет большое значение, потому что, как люди, мы все время взаимодействуем с объектами независимо от их "ярлыка класса" (используя случайные объекты вокруг вас в качестве бумажных гирь, сидя на вещах, которые не являются стульями), и поэтому некоторые наборы данных пытаются решить эту проблему, но главная причина, по которой этой проблеме не уделяется много внимания, заключается в том, что она недостаточно определена. 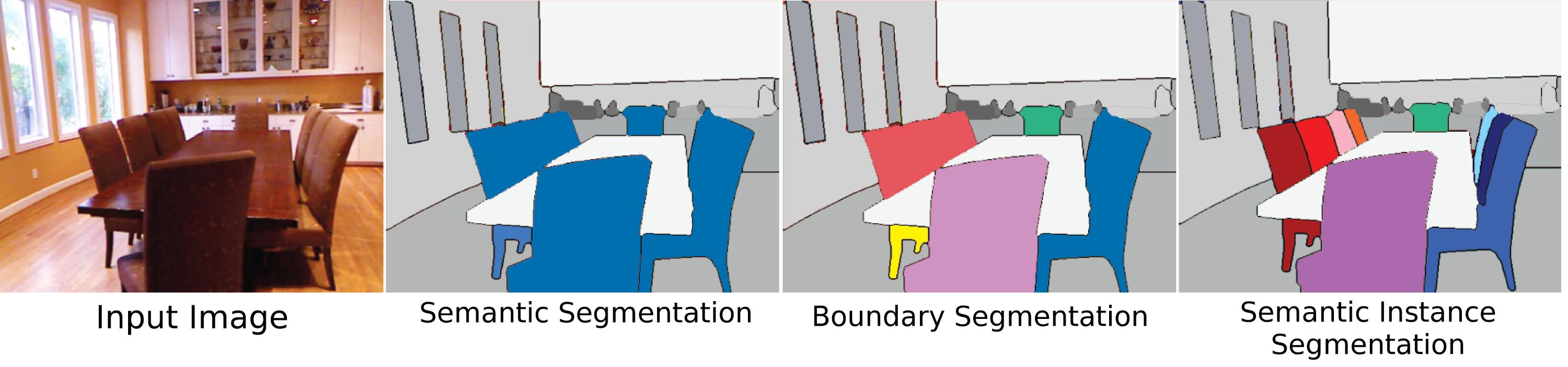
Разбор сцены / Маркировка сцены
Scene Parsing - это строго сегментированный подход к маркировке сцены, который также имеет свои собственные проблемы с неопределенностью. Исторически маркировка сцены подразумевала разделение всей "сцены" (изображения) на сегменты и присвоение им всех меток класса. Однако это также использовалось для обозначения надписей классов областям изображения без их явного сегментирования. Что касается сегментации, "семантическая сегментация" не подразумевает разделение всей сцены. Для семантической сегментации алгоритм предназначен для сегментирования только тех объектов, которые ему известны, и будет оштрафован своей функцией потерь за маркировку пикселей, которые не имеют какой-либо метки. Например, набор данных MS-COCO является набором данных для семантической сегментации, где сегментированы только некоторые объекты. 