Нормально распределенная подвыборка из массива в Python
У меня есть массив NumPy, значения которого распределяются следующим образом

Из этого массива мне нужно получить случайную подвыборку, которая обычно распределяется.
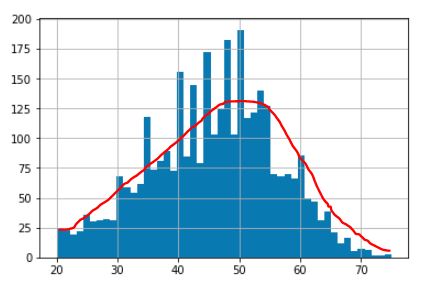
Мне нужно избавиться от значений из массива, которые находятся над красной линией на картинке. то есть мне нужно избавиться от некоторых вхождений определенных значений из массива, чтобы мое распределение было сглажено при удалении резких пиков.
И распределение моего массива должно выглядеть следующим образом: 
Может ли это быть достигнуто в python, без ручного поиска записей, соответствующих пикам, и удаления некоторых из них? Можно ли сделать это проще?
1 ответ
Следующий вид работ, он довольно агрессивный, хотя: 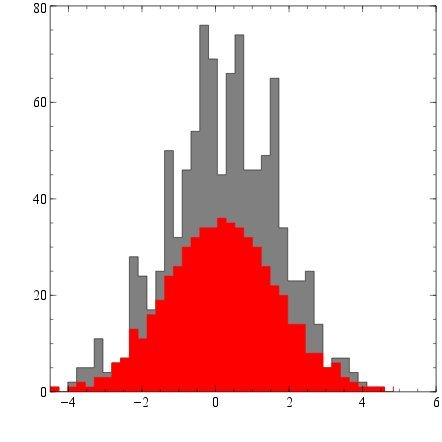
Он работает, упорядочивая сэмплы, преобразуя их в однородные и затем пытаясь выбрать регулярную подвыборку сетки. Если вы чувствуете, что это слишком агрессивно, вы можете увеличить ns что по сути количество сохраненных образцов.
Также обратите внимание, что для этого требуется знание истинного дистрибутива. В случае нормального распределения вы должны быть в порядке с использованием выборочного среднего значения и оценки несмещенной дисперсии (с n-1).
Код (без вычерчивания):
import scipy.stats as ss
import numpy as np
a = ss.norm.rvs(size=1000)
b = ss.uniform.rvs(size=1000)<0.4
a[b] += 0.1*np.sin(10*a[b])
def smooth(a, gran=25):
o = np.argsort(a)
s = ss.norm.cdf(a[o])
ns = int(gran / np.max(s[gran:] - s[:-gran]))
grid, dp = np.linspace(0, 1, ns, endpoint=False, retstep=True)
grid += dp/2
idx = np.searchsorted(s, grid)
c = np.flatnonzero(idx[1:] <= idx[:-1])
while c.size > 0:
idx[c+1] = idx[c] + 1
c = np.flatnonzero(idx[1:] <= idx[:-1])
idx = idx[:np.searchsorted(idx, len(a))]
return o[idx]
ap = a[smooth(a)]
c, b = np.histogram(a, 40)
cp, _ = np.histogram(ap, b)