Диаграммы временных рядов для больших объемов данных
У меня есть пара тысяч временных рядов, охватывающих несколько лет со второй гранулярностью. Я хотел бы хранить данные в подходящей БД (то есть той, которая хорошо масштабируется и может сохранять все данные с исходной гранулярностью, например, Druid, openTSDB или аналогичные). Цель состоит в том, чтобы иметь возможность просматривать данные в браузере (например, вводя временной интервал и в идеале имея функцию масштабирования / панорамирования).
Чтобы ограничить количество точек данных, которые должен обрабатывать мой веб-сервер, я хотел бы иметь функциональность, которая, кажется, работает из коробки для Graphite/Grafana (что, если я правильно понимаю, не является хорошим выбором для долгосрочного хранения данных): график временных рядов в Grafana будет ограничивать данные путем запроса агрегации из графита (например, возвращать среднее значение более 30 м сегментов при уменьшении при отображении всех данных при увеличении).
Теперь вопросы:
- Существуют ли инструменты визуализации для БД временных рядов, которые предоставляют эту функциональность?
- Существуют ли каркасы для диаграмм, которые позволяют мне настраивать данные для каждого уровня масштабирования?
Отзывы о выборе БД также приветствуются (желательно с открытым исходным кодом).
2 ответа
Вы можете абсолютно хранить данные за несколько лет в Graphite, проблема в том, что Graphite выбирает уровень агрегации для чтения, находя архив с наивысшим разрешением, который охватывает запрошенный интервал, поэтому вы не можете автоматически Воспользуйтесь преимуществами агрегации, чтобы иметь эффективные долгосрочные графики и возможность переходить к необработанным данным за прошедший период времени.
Один из способов обойти эту проблему - использовать агрегатор углерода для генерации нескольких выходных рядов с разными интервалами от ваших входных рядов, чтобы вы могли иметь my.metric.raw, my.metric.10min, my.metric.1hrи т. д. Вы бы соединили это с углеродной схемой, которая определяет интервал сопоставления и время хранения для каждой серии, так my.metric.raw хранится с разрешением в 1 секунду, .1min в 1 минуту и т. д.
Если вы сделаете это, то в Grafana вы можете использовать переменную шаблона, чтобы выбрать интервал, из которого вы хотите построить график, чтобы вы могли определить переменную $aggregation с вариантами raw, 10minи т. д. и напишите ваши запросы как my.metric.$aggregation,
Это даст вам необходимую производительность с возможностью углубления в необработанные данные.
Тем не менее, мы обычно находим, что, хотя все думают, что им нужно много исторических данных с высокой степенью детализации, они практически никогда не используются и, как правило, являются ненужными расходами. Это может быть не так, но подумайте о реальных случаях использования при проектировании системы.
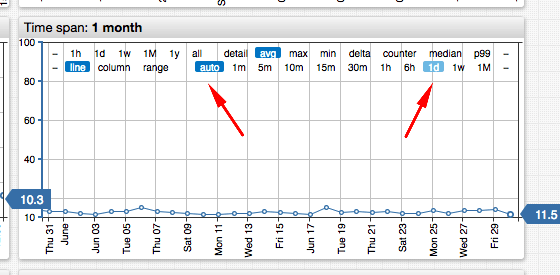
База данных временных рядов Axibase (ATSD) предоставляет встроенную библиотеку диаграмм, которая выполняет агрегацию периодов на лету в зависимости от интервала дат, отображаемого в браузере. Это контролируется с period = auto установка, которую вы можете переопределить, чтобы установить период явно. Когда пользователь увеличивает или уменьшает масштаб времени, период агрегации корректируется автоматически.
Вот живой пример и скриншот ниже. Кстати, диаграмма "1 год" отображает 2 миллиона выборок, собранных во время запроса на сервере. Агрегаты не кэшируются, что делает реализацию устойчивой к ошибкам записи.
Рекомендации:
- График временных рядов ATSD
- ATSD документация