Python re.finditer match.groups() не содержит все группы из match
Я пытаюсь использовать регулярные выражения в Python, чтобы найти и напечатать все соответствующие строки из многострочного поиска. Текст, который я ищу, может иметь следующую структуру примера:
AAA АВС1 ABC2 ABC3 AAA АВС1 ABC2 ABC3 ABC4 азбука AAA АВС1 AAA
Из которого я хочу получить ABC *, которые встречаются хотя бы один раз и перед ними стоит AAA.
Проблема в том, что несмотря на то, что группа ловит то, что я хочу:
match = <_sre.SRE_Match object; span=(19, 38), match='AAA\nABC2\nABC3\nABC4\n'>
... Я могу получить доступ только к последнему совпадению группы:
match groups = ('AAA\n', 'ABC4\n')
Ниже приведен пример кода, который я использую для этой проблемы.
#! python
import sys
import re
import os
string = "AAA\nABC1\nABC2\nABC3\nAAA\nABC1\nABC2\nABC3\nABC4\nABC\nAAA\nABC1\nAAA\n"
print(string)
p_MATCHES = []
p_MATCHES.append( (re.compile('(AAA\n)(ABC[0-9]\n){1,}')) ) #
matches = re.finditer(p_MATCHES[0],string)
for match in matches:
strout = ''
gr_iter=0
print("match = "+str(match))
print("match groups = "+str(match.groups()))
for group in match.groups():
gr_iter+=1
sys.stdout.write("TEST GROUP:"+str(gr_iter)+"\t"+group) # test output
if group is not None:
if group != '':
strout+= '"'+group.replace("\n","",1)+'"'+'\n'
sys.stdout.write("\nCOMPLETE RESULT:\n"+strout+"====\n")
2 ответа
Вот ваше регулярное выражение:
(AAA\r\n)(ABC[0-9]\r\n){1,}
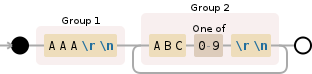
Ваша цель - захватить все ABC#с, которые следуют сразу AAA, Как вы можете видеть в этой демонстрации Debuggex, все ABC#s действительно сопоставляются (они выделены желтым цветом). Однако, поскольку только часть "что повторяется"
ABC[0-9]\r\n
захватывается (находится в скобках), и его квантификатор,
{1,}
не фиксируется, поэтому все совпадения, кроме последнего, будут отброшены. Чтобы получить их, вы также должны захватить квантификатор:
AAA\r\n((?:ABC[0-9]\r\n){1,})
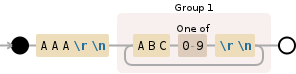
Я поместил часть "что повторяется" (ABC[0-9]\r\n) в не захватывающую группу. (Я также перестал захватывать AAA, как вам, кажется, не нужно.)
Захваченный текст может быть разделен на новую строку и даст вам все фрагменты, как вы пожелаете.
(Обратите внимание, что \n само по себе не работает в Debuggex. Это требует \r\n.)
Это обходной путь. Не многие разновидности регулярных выражений предлагают возможность повторения повторяющихся захватов (какие...?). Более нормальный подход состоит в том, чтобы проходить иобрабатывать каждое совпадение по мере его обнаружения. Вот пример из Java:
import java.util.regex.*;
public class RepeatingCaptureGroupsDemo {
public static void main(String[] args) {
String input = "I have a cat, but I like my dog better.";
Pattern p = Pattern.compile("(mouse|cat|dog|wolf|bear|human)");
Matcher m = p.matcher(input);
while (m.find()) {
System.out.println(m.group());
}
}
}
Выход:
cat
dog
(От http://ocpsoft.org/opensource/guide-to-regular-expressions-in-java-part-1/, примерно на 1/4 вниз)
Пожалуйста, рассмотрите возможность добавления закладок в FAQ по регулярным выражениям в стеке. Ссылки в этом ответе взяты из него.
Вы хотите, чтобы последовательность ABC\n происходила после AAA\n самым жадным образом. Вам также нужна только группа следующих друг за другом ABC\ n, а не кортеж из этого и самого последнего ABC\n . Итак, в вашем регулярном выражении исключите подгруппу внутри группы. Обратите внимание на образец, напишите образец, представляющий всю строку.
AAA\n(ABC[0-9]\n)+
Затем запишите интересующий вас объект с помощью (), не забывая при этом исключить подгруппу (ы)
AAA\n((?:ABC[0-9]\n)+)
Затем вы можете использовать findall() или finditer(). Я считаю, что findIter проще, особенно когда вы имеете дело с более чем одним захватом. finditer:-
import re
matches_iter = re.finditer(r'AAA\n((?:ABC[0-9]\n)+)', string)
[print(i.group(1)) for i in matches_iter]
findall использовал исходный {1,} как более подробную форму +:-
matches_all = re.findall(r'AAA\n((?:ABC[0-9]\n){1,})', string)
[[print(x) for x in y.split("\n")] for y in matches_all]