Что такое группа без захвата? Что делает (?:)?
Как ?: используется и для чего он хорош?
18 ответов
Позвольте мне попытаться объяснить это на примере.
Рассмотрим следующий текст:
http://stackru.com/
https://stackru.com/questions/tagged/regex
Теперь, если я применю регулярное выражение ниже...
(https?|ftp)://([^/\r\n]+)(/[^\r\n]*)?
... я бы получил следующий результат:
Match "http://stackru.com/"
Group 1: "http"
Group 2: "stackru.com"
Group 3: "/"
Match "https://stackru.com/questions/tagged/regex"
Group 1: "https"
Group 2: "stackru.com"
Group 3: "/questions/tagged/regex"
Но мне нет дела до протокола - мне просто нужен хост и путь к URL. Итак, я изменяю регулярное выражение, чтобы включить группу без захвата (?:),
(?:https?|ftp)://([^/\r\n]+)(/[^\r\n]*)?
Теперь мой результат выглядит так:
Match "http://stackru.com/"
Group 1: "stackru.com"
Group 2: "/"
Match "https://stackru.com/questions/tagged/regex"
Group 1: "stackru.com"
Group 2: "/questions/tagged/regex"
Увидеть? Первая группа не была захвачена. Парсер использует его для соответствия тексту, но игнорирует его позже, в конечном результате.
РЕДАКТИРОВАТЬ:
В соответствии с просьбой, позвольте мне попытаться объяснить группы тоже.
Ну, группы служат многим целям. Они могут помочь вам извлечь точную информацию из большего совпадения (которое также может быть названо), они позволяют вам сопоставить предыдущую сопоставленную группу и могут быть использованы для замены. Давайте попробуем несколько примеров, не так ли?
Хорошо, представьте, что у вас есть какой-то XML или HTML (имейте в виду, что регулярное выражение может быть не лучшим инструментом для работы, но это хорошо в качестве примера). Вы хотите разобрать теги, чтобы вы могли сделать что-то вроде этого (я добавил пробелы, чтобы было легче понять):
\<(?<TAG>.+?)\> [^<]*? \</\k<TAG>\>
or
\<(.+?)\> [^<]*? \</\1\>
Первый регулярное выражение имеет именованную группу (TAG), а второй использует общую группу. Оба регулярных выражения делают одно и то же: они используют значение из первой группы (имя тега), чтобы соответствовать закрывающему тегу. Разница в том, что первый использует имя для соответствия значению, а второй использует групповой индекс (который начинается с 1).
Давайте попробуем некоторые замены сейчас. Рассмотрим следующий текст:
Lorem ipsum dolor sit amet consectetuer feugiat fames malesuada pretium egestas.
Теперь давайте воспользуемся этим тупым регулярным выражением:
\b(\S)(\S)(\S)(\S*)\b
Это регулярное выражение сопоставляет слова, содержащие не менее 3 символов, и использует группы для разделения первых трех букв. Результат таков:
Match "Lorem"
Group 1: "L"
Group 2: "o"
Group 3: "r"
Group 4: "em"
Match "ipsum"
Group 1: "i"
Group 2: "p"
Group 3: "s"
Group 4: "um"
...
Match "consectetuer"
Group 1: "c"
Group 2: "o"
Group 3: "n"
Group 4: "sectetuer"
...
Итак, если мы применим строку подстановки...
$1_$3$2_$4
... поверх него мы пытаемся использовать первую группу, добавить подчеркивание, использовать третью группу, затем вторую группу, добавить еще одно подчеркивание, а затем четвертую группу. Результирующая строка будет похожа на приведенную ниже.
L_ro_em i_sp_um d_lo_or s_ti_ a_em_t c_no_sectetuer f_ue_giat f_ma_es m_la_esuada p_er_tium e_eg_stas.
Вы также можете использовать именованные группы для замены, используя ${name},
Чтобы поиграть с регулярными выражениями, я рекомендую http://regex101.com/, который предлагает большое количество деталей о том, как работает регулярное выражение; он также предлагает несколько двигателей регулярных выражений на выбор.
Вы можете использовать группы захвата для организации и анализа выражения. У группы без захвата есть первое преимущество, но нет второго. Вы все еще можете сказать, что не захватывающая группа является необязательной, например.
Допустим, вы хотите сопоставить числовой текст, но некоторые числа могут быть записаны как 1-й, 2-й, 3-й, 4-й,... Если вы хотите захватить числовую часть, но не (необязательный) суффикс, вы можете использовать группу без захвата,
([0-9]+)(?:st|nd|rd|th)?
Это будет соответствовать числам в форме 1, 2, 3... или в форме 1, 2, 3,..., но это будет захватывать только числовую часть.
?: используется, когда вы хотите сгруппировать выражение, но не хотите сохранять его как совпадающую / захваченную часть строки.
Примером будет что-то, чтобы соответствовать IP-адресу:
/(?:\d{1,3}\.){3}\d{1,3}/
Обратите внимание, что я не забочусь о сохранении первых 3 октетов, но (?:...) группирование позволяет мне сократить регулярное выражение без дополнительных затрат на захват и сохранение матча.
ИСТОРИЧЕСКАЯ МОТИВАЦИЯ: Существование не захватывающих групп можно объяснить с помощью круглых скобок. Рассмотрим выражения (a|b)c и a|bc, из-за приоритета конкатенации над |, эти выражения представляют два разных языка ({ac, bc} и {a, bc} соответственно). Тем не менее, скобки также используются в качестве соответствующей группы (как объяснено другими ответами...).
Если вы хотите иметь круглые скобки, но не захватывать подвыражение, вы используете НЕЗАХВАТЫВАЮЩИЕ ГРУППЫ. В примере (?: A | b) c
Позвольте мне попробовать это на примере:
Код регулярного выражения:- (?:animal)(?:=)(\w+)(,)\1\2
Строка поиска:-
Строка 1 - animal=cat,dog,cat,tiger,dog
Строка 2 - animal=cat,cat,dog,dog,tiger
Строка 3 - animal=dog,dog,cat,cat,tiger
(?:animal) -> Незахваченная группа 1
(?:=)-> Незахваченная группа 2
(\w+)-> Захваченная группа 1
(,)-> Захваченная группа 2
\1 -> результат захваченной группы 1, т.е. в строке 1 - кошка, в строке 2 - кошка, в строке 3 - собака.
\2 -> результат захваченной группы 2, т.е. запятая (,)
Таким образом, в этом коде, давая \1 и \2, мы напоминаем или повторяем результат захваченной группы 1 и 2 соответственно позже в коде.
В соответствии с порядком кода (?: Animal) должна быть группа 1, а (?:=) Должна быть группа 2 и продолжается..
но, задавая?: мы делаем группу совпадений не захваченной (которые не учитываются в сопоставленной группе, поэтому номер группы начинается с первой захваченной группы, а не не захваченной), так что повторение результата совпадения -group (?:animal) не может быть вызвана позже в коде.
Надеюсь, это объясняет использование группы без захвата.
Это делает группу не захватывающей, что означает, что подстрока, сопоставленная этой группой, не будет включена в список перехватов. Пример в ruby, чтобы проиллюстрировать разницу:
"abc".match(/(.)(.)./).captures #=> ["a","b"]
"abc".match(/(?:.)(.)./).captures #=> ["b"]
Группы, которые вы собираете, вы можете использовать позже в регулярном выражении, чтобы соответствовать ИЛИ, вы можете использовать их в заменяющей части регулярного выражения. Создание группы без захвата просто освобождает эту группу от использования по любой из этих причин.
Группы без захвата хороши, если вы пытаетесь захватить много разных вещей, и есть группы, которые вы не хотите захватывать.
Это в значительной степени причина, по которой они существуют. Пока вы учитесь о группах, узнаваете об атомных группах, они многое делают! Есть также обходные группы, но они немного сложнее и не так часто используются.
Пример использования позже в регулярном выражении (обратная ссылка):
<([A-Z][A-Z0-9]*)\b[^>]*>.*?</\1> [Находит тег xml (без поддержки ns) ]
([A-Z][A-Z0-9]*) группа захвата (в данном случае это тэг)
Позже в регулярном выражении \1 это означает, что он будет совпадать только с тем же текстом, который был в первой группе (([A-Z][A-Z0-9]*) группа) (в данном случае это совпадает с конечным тегом).
Простой ответ
Используйте их, чтобы убедиться, что здесь возникает одна из нескольких возможностей.
Они сводят к минимуму количество ваших захваченных групп.
Группы без захвата, как следует из названия, являются частями регулярного выражения, которые вы не хотите включать в матч, и ?: способ определить группу как не захватывающую
Допустим, у вас есть адрес электронной почты example@example.com, Следующее регулярное выражение создаст две группы, часть id и часть @ example.com. (\p{Alpha}*[a-z])(@example.com), Для простоты мы извлекаем все доменное имя, включая @ персонаж.
Допустим, вам нужна только часть идентификатора адреса. То, что вы хотите сделать, это захватить первую группу результата матча, в окружении () в регулярном выражении и способ сделать это состоит в том, чтобы использовать синтаксис группы без захвата, т.е. ?:, Так что регулярное выражение (\p{Alpha}*[a-z])(?:@example.com) вернет только часть идентификатора электронной почты.
Я не могу комментировать верхние ответы, чтобы сказать это: я хотел бы добавить явное замечание, которое подразумевается только в верхних ответах:
Группа без захвата (?...) не удаляет символы из исходного полного соответствия, он только визуально реорганизует регулярное выражение для программиста.
Чтобы получить доступ к определенной части регулярного выражения без определенных посторонних символов, вам всегда нужно использовать .group(<index>)
Одна интересная вещь, с которой я столкнулся, это то, что вы можете иметь группу захвата внутри группы без захвата. Посмотрите на регулярное выражение для соответствия веб-URL:
var parse_url_regex = /^(?:([A-Za-z]+):)(\/{0,3})([0-9.\-A-Za-z]+)(?::(\d+))?(?:\/([^?#]*))?(?:\?([^#]*))?(?:#(.*))?$/;
Входная строка URL:
var url = "http://www.ora.com:80/goodparts?q#fragment";
Первая группа в моем регулярном выражении (?:([A-Za-z]+):) это группа без захвата, которая соответствует схеме протокола и двоеточию : характер т.е. http: но когда я работал под кодом ниже, я увидел, что первый индекс возвращаемого массива содержит строку http когда я думал, что http и толстая кишка : оба не будут сообщены, так как они находятся в группе без захвата.
console.debug(parse_url_regex.exec(url));
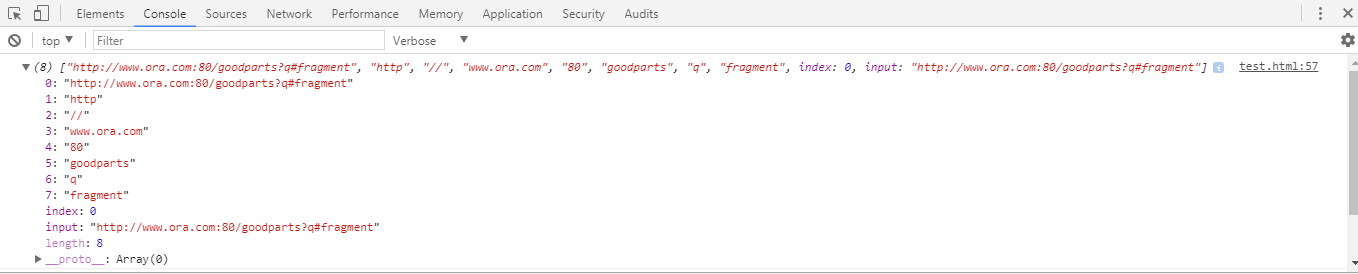
Я думал, что если первая группа (?:([A-Za-z]+):) это группа без захвата, то почему она возвращается http строка в выходном массиве.
Так что, если вы заметили, что есть вложенная группа ([A-Za-z]+) внутри группы без захвата. Эта вложенная группа ([A-Za-z]+) группа захвата (не имеющая ?: в начале) сама по себе внутри группы без захвата (?:([A-Za-z]+):), Вот почему текст http все еще попадает в плен, но толстая кишка : символ, который находится внутри группы без захвата, но вне группы захвата, не выводится в выходном массиве.
Ну, я разработчик JavaScript и постараюсь объяснить его значение для JavaScript.
Рассмотрим сценарий, в котором вы хотите соответствовать cat is animalкогда вы хотели бы сочетать кошку и животное, и оба должны иметь is между ними.
// this will ignore "is" as that's is what we want
"cat is animal".match(/(cat)(?: is )(animal)/) ;
result ["cat is animal", "cat", "animal"]
// using lookahead pattern it will match only "cat" we can
// use lookahead but the problem is we can not give anything
// at the back of lookahead pattern
"cat is animal".match(/cat(?= is animal)/) ;
result ["cat"]
//so I gave another grouping parenthesis for animal
// in lookahead pattern to match animal as well
"cat is animal".match(/(cat)(?= is (animal))/) ;
result ["cat", "cat", "animal"]
// we got extra cat in above example so removing another grouping
"cat is animal".match(/cat(?= is (animal))/) ;
result ["cat", "animal"]
В сложных регулярных выражениях может возникнуть ситуация, когда вы хотите использовать большое количество групп, некоторые из которых существуют для сопоставления повторений, а некоторые - для обратных ссылок. По умолчанию текст, соответствующий каждой группе, загружается в массив обратных ссылок. Там, где у нас много групп, и нам нужно только ссылаться на некоторые из них из массива обратных ссылок, мы можем переопределить это поведение по умолчанию, чтобы сообщить регулярному выражению, что определенные группы существуют только для обработки повторений и их не нужно захватывать и хранить в массиве обратных ссылок.
Позвольте мне привести вам пример географической координаты, приведенная ниже соответствует двум группам.
Latitude,Longitude
([+-]?\d+(?:\.\d+)?),([+-]?\d+(?:\.\d+)?)
Возьмем один
([+-]?\d+(?:\.\d+)?)
координата может быть целым числом или может быть
58.666
Следовательно, необязательная () вторая часть
(\.\d+)?упомянуто.
(...)? - for optional
Но в скобках указано, что это будет другая группа матчей. и мы не хотим две спички одну за
58и еще один для
.666, нам нужна одна широта в качестве совпадения. А вот и группа без захвата
(?:)
с группой без захвата
[+-]?\d+(?:\.\d+)?, 58,666 и 58 — одно совпадение
(?: ...) действует как группа (...), но не захватывает совпадающие данные. Это действительно намного эффективнее, чем стандартная группа захвата. Он используется, когда вы хотите что-то сгруппировать, но вам не нужно повторно использовать это позже. @Toto
Это очень просто, мы можем понять на простом примере даты, предположим, что если дата упоминается как 1 января 2019 года или 2 мая 2019 года или любая другая дата, и мы просто хотим преобразовать ее в формат дд / мм / гггг, нам не понадобится месяц имя, которое в этом случае будет январь или февраль, поэтому для захвата числовой части, но не (необязательного) суффикса, вы можете использовать группу без захвата.
поэтому регулярное выражение будет
([0-9]+)(?:January|February)?
Это так просто.
Я думаю, что дал бы вам ответ: не используйте переменные захвата, не проверив, что совпадение прошло успешно.
Переменные захвата, $1 и т. Д., Недействительны, если совпадение не выполнено, и они также не очищены.
#!/usr/bin/perl
use warnings;
use strict;
$_ = "bronto saurus burger";
if (/(?:bronto)? saurus (steak|burger)/)
{
print "Fred wants a $1";
}
else
{
print "Fred dont wants a $1 $2";
}
В приведенном выше примере, чтобы избежать захвата бронто в $1, используется (?:). Если шаблон соответствует, то $ 1 фиксируется как следующий сгруппированный шаблон. Итак, вывод будет таким, как показано ниже:
Fred wants a burger
Это полезно, если вы не хотите, чтобы совпадения были сохранены.
Откройте Google Chrome devTools, а затем вкладку "Консоль" и введите:
"Peace".match(/(\w)(\w)(\w)/)
Запустите его, и вы увидите:
["Pea", "P", "e", "a", index: 0, input: "Peace", groups: undefined]
JavaScript Движок RegExp захватывает три группы, элементы с индексами 1,2,3. Теперь используйте не захватывающую метку, чтобы увидеть результат.
"Peace".match(/(?:\w)(\w)(\w)/)
Результат:
["Pea", "e", "a", index: 0, input: "Peace", groups: undefined]
Это очевидно, что не захватывает группу.