R, padr добавление пропущенных строк на основе содержимого столбца
Я использую padr для заполнения даты для фрейма данных. Были добавлены строки, но как их можно добавить аккуратно?
Хотелось отсортировать фрейм данных по персоналу и дате и времени, а затем добавить пропущенные строки между сотрудниками. (Отсутствие между двумя разными сотрудниками не считается отсутствием)
Вот так выглядит фрейм данных и ожидание.
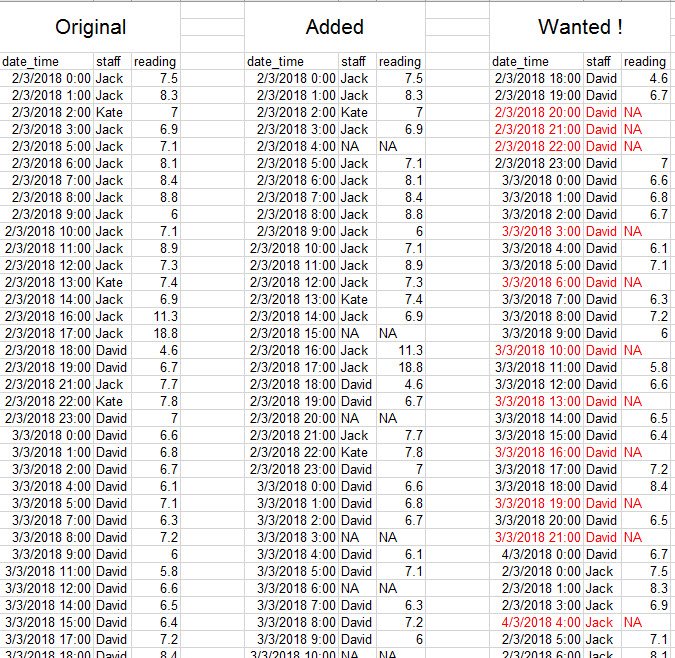
Я попытался отсортировать исходные данные, но, похоже, это не помогает в конечном результате. Как я могу это сделать? Спасибо.
df_sorted <- df[with(df, order(staff, date_time)), ]
код:
date_time <- c("02/03/2018 00:00","02/03/2018 01:00","02/03/2018 02:00","02/03/2018 03:00","02/03/2018 05:00","02/03/2018 06:00","02/03/2018 07:00","02/03/2018 08:00","02/03/2018 09:00","02/03/2018 10:00","02/03/2018 11:00","02/03/2018 12:00","02/03/2018 13:00","02/03/2018 14:00","02/03/2018 16:00","02/03/2018 17:00","02/03/2018 18:00","02/03/2018 19:00","02/03/2018 21:00","02/03/2018 22:00","02/03/2018 23:00","03/03/2018 00:00","03/03/2018 01:00","03/03/2018 02:00","03/03/2018 04:00","03/03/2018 05:00","03/03/2018 07:00","03/03/2018 08:00","03/03/2018 09:00","03/03/2018 11:00","03/03/2018 12:00","03/03/2018 14:00","03/03/2018 15:00","03/03/2018 17:00","03/03/2018 18:00","03/03/2018 20:00","03/03/2018 22:00","03/03/2018 23:00","04/03/2018 00:00","04/03/2018 01:00","04/03/2018 02:00","04/03/2018 03:00","04/03/2018 05:00","04/03/2018 06:00","04/03/2018 07:00","04/03/2018 08:00","04/03/2018 10:00","04/03/2018 11:00","04/03/2018 12:00","04/03/2018 14:00","04/03/2018 15:00","04/03/2018 16:00","04/03/2018 17:00","04/03/2018 19:00","04/03/2018 20:00","04/03/2018 22:00","04/03/2018 23:00")
staff <- c("Jack","Jack","Kate","Jack","Jack","Jack","Jack","Jack","Jack","Jack","Jack","Jack","Kate","Jack","Jack","Jack","David","David","Jack","Kate","David","David","David","David","David","David","David","David","David","David","David","David","David","David","David","David","Jack","Kate","David","Kate","Kate","Kate","Kate","Kate","Kate","Kate","Kate","Kate","Kate","Kate","Kate","Kate","Kate","Kate","Kate","Kate","Jack")
reading <- c("7.5","8.3","7","6.9","7.1","8.1","8.4","8.8","6","7.1","8.9","7.3","7.4","6.9","11.3","18.8","4.6","6.7","7.7","7.8","7","6.6","6.8","6.7","6.1","7.1","6.3","7.2","6","5.8","6.6","6.5","6.4","7.2","8.4","6.5","6.5","5.5","6.7","7.5","6.5","7.5","7.2","6.3","7.3","8","7","8.2","6.5","6.8","7.5","7","6.1","5.7","6.7","4.3","6.3")
df <- data.frame(date_time, staff, reading)
write.csv(df, "df.csv", row.names = FALSE)
library(padr)
df$date_time<-as.POSIXct(df$date_time,format="%d/%m/%Y %H:%M")
ddf <- pad(df)
write.csv(ddf, "ddf.csv", row.names = FALSE)
1 ответ
Решение
Я думаю, что это даст вам желаемый результат.
library(dplyr)
library(padr)
library(lubridate)
df %>%
mutate(date_time = dmy_hm(date_time)) %>%
pad(., interval = "hour", group = 'staff')
# A tibble: 172 x 3
# Groups: staff [3]
# date_time staff reading
# <dttm> <fct> <fct>
#1 2018-03-02 18:00:00 David 4.6
#2 2018-03-02 19:00:00 David 6.7
#3 2018-03-02 20:00:00 David <NA>
#4 2018-03-02 21:00:00 David <NA>
#5 2018-03-02 22:00:00 David <NA>
#6 2018-03-02 23:00:00 David 7
#7 2018-03-03 00:00:00 David 6.6
#8 2018-03-03 01:00:00 David 6.8
#9 2018-03-03 02:00:00 David 6.7
#10 2018-03-03 03:00:00 David <NA>
# ... with 162 more rows
Ключ к group по персоналу. Я надеюсь, что это помогает.