Построение тепловой карты для 3 колонн в питоне с морской волной
v1 v2 yy
15.25 44.34 100.00
83.05 59.78 100.00
96.61 65.09 100.00
100.00 75.47 100.00
100.00 50.00 100.00
100.00 68.87 100.00
100.00 79.35 100.00
100.00 100.00 100.00
100.00 63.21 100.00
100.00 100.00 100.00
100.00 68.87 100.00
0.00 56.52 92.86
10.17 52.83 92.86
23.73 46.23 92.86
На приведенном выше кадре данных я хочу построить тепловую карту, используя v1 и v2 в качестве оси x и y, а yy в качестве значения. Как я могу сделать это в Python? Я попробовал морского рожка:
df = df.pivot('v1', 'v2', 'yy')
ax = sns.heatmap(df)
Однако это не работает. Любое другое решение?
2 ответа
Морской Рог heatmap строит категорические данные. Это означает, что каждое возникающее значение будет занимать то же место в тепловой карте, что и любое другое значение, независимо от того, насколько далеко они численно разделены. Это обычно нежелательно для числовых данных. Вместо этого может быть выбран один из следующих методов.
Scatter
Цветная диаграмма рассеяния может быть так же хороша, как тепловая карта. Цвета точек будут представлять yy значение.
ax.scatter(df.v1, df.v2, c=df.yy, cmap="copper")
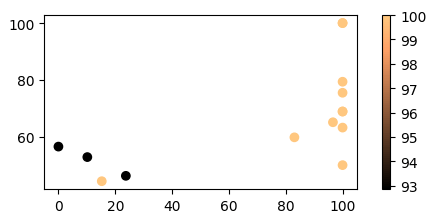
u = u"""v1 v2 yy
15.25 44.34 100.00
83.05 59.78 100.00
96.61 65.09 100.00
100.00 75.47 100.00
100.00 50.00 100.00
100.00 68.87 100.00
100.00 79.35 100.00
100.00 100.00 100.00
100.00 63.21 100.00
100.00 100.00 100.00
100.00 68.87 100.00
0.00 56.52 92.86
10.17 52.83 92.86
23.73 46.23 92.86"""
import pandas as pd
import matplotlib.pyplot as plt
import io
df = pd.read_csv(io.StringIO(u), delim_whitespace=True )
fig, ax = plt.subplots()
sc = ax.scatter(df.v1, df.v2, c=df.yy, cmap="copper")
fig.colorbar(sc, ax=ax)
ax.set_aspect("equal")
plt.show()Hexbin
Вы можете посмотреть в hexbin, Данные будут отображаться в шестиугольных ячейках, а данные агрегируются как среднее значение внутри каждой ячейки. Преимущество здесь в том, что если вы выберете большой размер сетки, он будет выглядеть как график рассеяния, а если вы сделаете его маленьким, он будет выглядеть как тепловая карта, позволяющая легко настроить график под желаемое разрешение.
h1 = ax.hexbin(df.v1, df.v2, C=df.yy, gridsize=100, cmap="copper")
h2 = ax2.hexbin(df.v1, df.v2, C=df.yy, gridsize=10, cmap="copper")
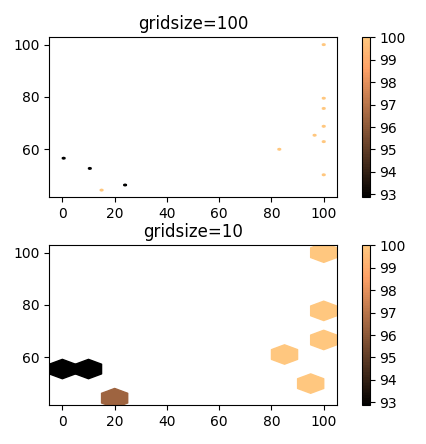
u = u"""v1 v2 yy
15.25 44.34 100.00
83.05 59.78 100.00
96.61 65.09 100.00
100.00 75.47 100.00
100.00 50.00 100.00
100.00 68.87 100.00
100.00 79.35 100.00
100.00 100.00 100.00
100.00 63.21 100.00
100.00 100.00 100.00
100.00 68.87 100.00
0.00 56.52 92.86
10.17 52.83 92.86
23.73 46.23 92.86"""
import pandas as pd
import matplotlib.pyplot as plt
import io
df = pd.read_csv(io.StringIO(u), delim_whitespace=True )
fig, (ax, ax2) = plt.subplots(nrows=2)
h1 = ax.hexbin(df.v1, df.v2, C=df.yy, gridsize=100, cmap="copper")
h2 = ax2.hexbin(df.v1, df.v2, C=df.yy, gridsize=10, cmap="copper")
fig.colorbar(h1, ax=ax)
fig.colorbar(h2, ax=ax2)
ax.set_aspect("equal")
ax2.set_aspect("equal")
ax.set_title("gridsize=100")
ax2.set_title("gridsize=10")
fig.subplots_adjust(hspace=0.3)
plt.show()Tripcolor
tripcolor График может использоваться для получения цветных областей на графике в соответствии с точками данных, которые затем интерпретируются как грани треугольников, раскрашенных в соответствии с данными граничных точек. Такой график потребовал бы наличия большего количества данных, чтобы дать осмысленное представление.
ax.tripcolor(df.v1, df.v2, df.yy, cmap="copper")
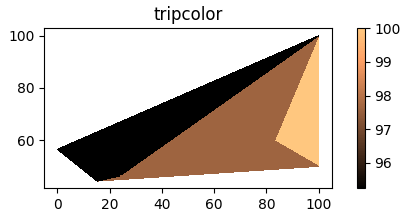
u = u"""v1 v2 yy
15.25 44.34 100.00
83.05 59.78 100.00
96.61 65.09 100.00
100.00 75.47 100.00
100.00 50.00 100.00
100.00 68.87 100.00
100.00 79.35 100.00
100.00 100.00 100.00
100.00 63.21 100.00
100.00 100.00 100.00
100.00 68.87 100.00
0.00 56.52 92.86
10.17 52.83 92.86
23.73 46.23 92.86"""
import pandas as pd
import matplotlib.pyplot as plt
import io
df = pd.read_csv(io.StringIO(u), delim_whitespace=True )
fig, ax = plt.subplots()
tc = ax.tripcolor(df.v1, df.v2, df.yy, cmap="copper")
fig.colorbar(tc, ax=ax)
ax.set_aspect("equal")
ax.set_title("tripcolor")
plt.show()Обратите внимание, что tricontourf График может также подходить, если доступно больше точек данных по всей сетке.
ax.tricontourf(df.v1, df.v2, df.yy, cmap="copper")
Проблема в том, что ваши данные имеют повторяющиеся значения, такие как:
100.00 100.00 100.00
100.00 100.00 100.00
Вы должны отбросить повторяющиеся значения, затем развернуть и построить график, как здесь:
import seaborn as sns
import pandas as pd
# fill data
df = pd.read_clipboard()
df.drop_duplicates(['v1','v2'], inplace=True)
pivot = df.pivot(index='v1', columns='v2', values='yy')
ax = sns.heatmap(pivot,annot=True)
plt.show()
print (pivot)
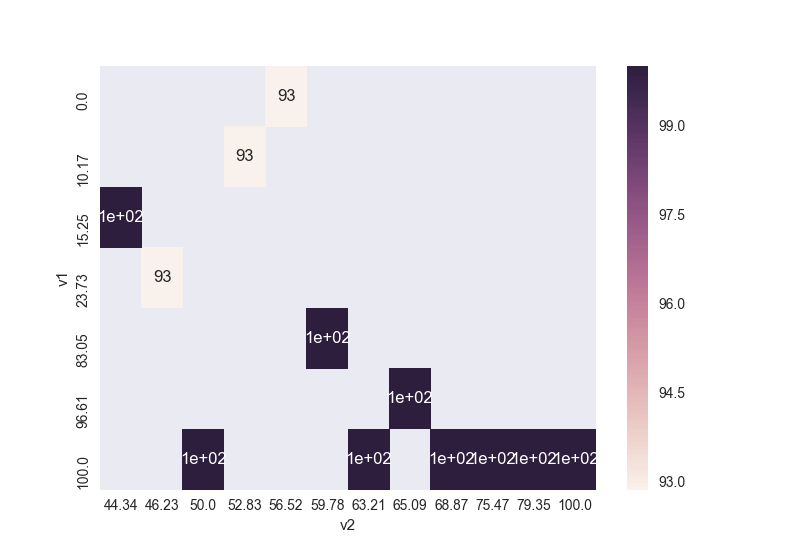
Pivot:
v2 44.34 46.23 50.00 52.83 56.52 59.78 63.21 65.09 \
v1
0.00 NaN NaN NaN NaN 92.86 NaN NaN NaN
10.17 NaN NaN NaN 92.86 NaN NaN NaN NaN
15.25 100.0 NaN NaN NaN NaN NaN NaN NaN
23.73 NaN 92.86 NaN NaN NaN NaN NaN NaN
83.05 NaN NaN NaN NaN NaN 100.0 NaN NaN
96.61 NaN NaN NaN NaN NaN NaN NaN 100.0
100.00 NaN NaN 100.0 NaN NaN NaN 100.0 NaN
v2 68.87 75.47 79.35 100.00
v1
0.00 NaN NaN NaN NaN
10.17 NaN NaN NaN NaN
15.25 NaN NaN NaN NaN
23.73 NaN NaN NaN NaN
83.05 NaN NaN NaN NaN
96.61 NaN NaN NaN NaN
100.00 100.0 100.0 100.0 100.0