Как выполнить подгонку данных, чтобы найти распределение данных
Мне нужно выполнить подгонку данных, чтобы найти распределение данных.
Мне нужно найти функцию распределения PDF.
Я могу использовать функции подбора данных в Matlab и Python.
Похоже на усеченную гамму.
Но как найти параметры распределения?
Что если данные не вписываются в усеченную гамму?
График QQ (квантиль-квантиль) показывает, что он не подходит для усеченной гаммы.
Как найти параметры распределения, такие как альфа (форма), бета (масштаб) для усеченной гаммы?
Если сбор данных не может работать здесь, какие еще методы я могу использовать для этого?
Любая помощь будет оценена.
3 ответа
Проверьте allfitdist в Matlab.
В качестве альтернативы рассмотрите специальные пакеты, такие как ExpertFit или EasyFit. Статистическое программное обеспечение JMP также имеет довольно простой в использовании вариант подгонки распределения. Все они будут оценивать критерии соответствия, такие как Крамер-фон Мизес и оценки вероятности записи.
После того как вы выбрали функциональную форму распределения, значения параметров обычно оцениваются с помощью оценок максимального правдоподобия или метода моментов.
Если вы планируете использовать результаты в какой-либо модели симуляции, вы можете подумать о том, чтобы просто начать выборку, а не подгонять распределение. Еще одним вариантом симуляции будет запуск спроектированного эксперимента, в котором вы меняете выбор распределения и смотрите, оказывают ли альтернативы существенное влияние на ваши результаты, прежде чем слишком сильно беспокоиться о подборе правильного распределения.
The distfitбиблиотека может все точки, которые вы просите. Он выполняет поиск по 89 теоретическим распределениям, чтобы найти лучшее с параметрами loc, scale arg. Пример:
Мне нужно выполнить подгонку данных, чтобы найти распределение заданных данных.
pip install distfit
from distfit import distfit
import numpy as np
# Create dataset
X = np.random.normal(0, 2, 1000)
# Default method is parametric.
dfit = distfit(distr='popular') # 'all' for all 89 or specify your own list.
# Search for best theoretical fit on your empirical data
results = dfit.fit_transform(X)
# [distfit] >INFO> fit
# [distfit] >INFO> transform
# [distfit] >INFO> [norm ] [0.00 sec] [RSS: 0.00221125] [loc=0.002 scale=1.902]
# [distfit] >INFO> [expon ] [0.00 sec] [RSS: 0.189094] [loc=-5.527 scale=5.529]
# [distfit] >INFO> [pareto ] [0.00 sec] [RSS: 0.189094] [loc=-536870917.527 scale=536870912.000]
# [distfit] >INFO> [dweibull ] [0.03 sec] [RSS: 0.00285214] [loc=0.005 scale=1.667]
# [distfit] >INFO> [t ] [0.18 sec] [RSS: 0.00221128] [loc=0.002 scale=1.902]
# [distfit] >INFO> [genextreme] [0.08 sec] [RSS: 0.00295224] [loc=-0.699 scale=1.892]
# [distfit] >INFO> [gamma ] [0.02 sec] [RSS: 0.00221712] [loc=-2156.094 scale=0.002]
# [distfit] >INFO> [lognorm ] [0.13 sec] [RSS: 0.00235342] [loc=-149.018 scale=149.010]
# [distfit] >INFO> [beta ] [0.03 sec] [RSS: 0.00208639] [loc=-11.915 scale=24.259]
# [distfit] >INFO> [uniform ] [0.00 sec] [RSS: 0.122291] [loc=-5.527 scale=11.639]
# [distfit] >INFO> [loggamma ] [0.06 sec] [RSS: 0.00209695] [loc=-376.616 scale=55.771]
# [distfit] >INFO> Compute confidence intervals [parametric]
fig, ax = plt.subplots(1, 2, figsize=(20, 10))
dfit.plot(chart='PDF', ax=ax[0])
dfit.plot(chart='CDF', ax=ax[1])
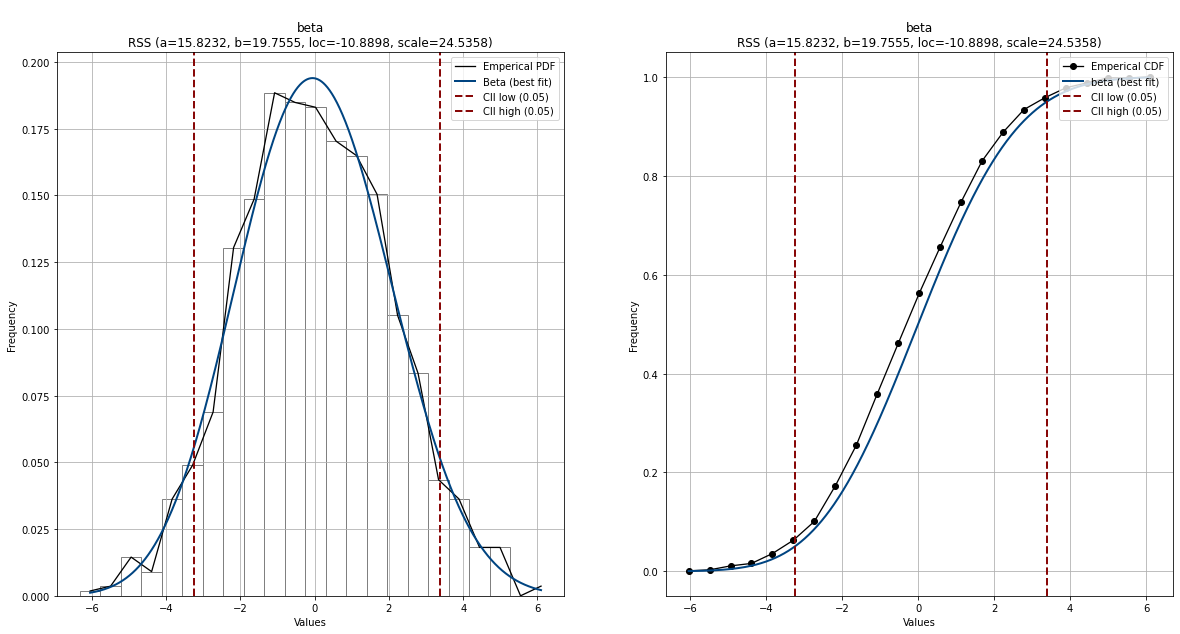
Лучшее соответствие можно найти в результатах, которые ответят на этот вопрос:
Мне нужно найти функцию pdf дистрибутива.
print(results['model'])
{'distr': <scipy.stats._continuous_distns.beta_gen at 0x155d67e35b0>,
'stats': 'RSS',
'params': (19.490647075756037,
20.18413144061353,
-11.915134641255602,
24.25907054997436),
'name': 'beta',
'model': <scipy.stats._distn_infrastructure.rv_continuous_frozen at 0x15583c00760>,
'score': 0.002086393123419647,
'loc': -11.915134641255602,
'scale': 24.25907054997436,
'arg': (19.490647075756037, 20.18413144061353),
'CII_min_alpha': -3.124111310171669,
'CII_max_alpha': 3.141196658807374}
Но как найти параметры распределения?
results['model']['params']
Что делать, если данные не могут хорошо соответствовать усеченной гамме?
# Take one of the other fitting models.
results['summary'][['distr', 'score']]
# Plot results
dfit.plot_summary()
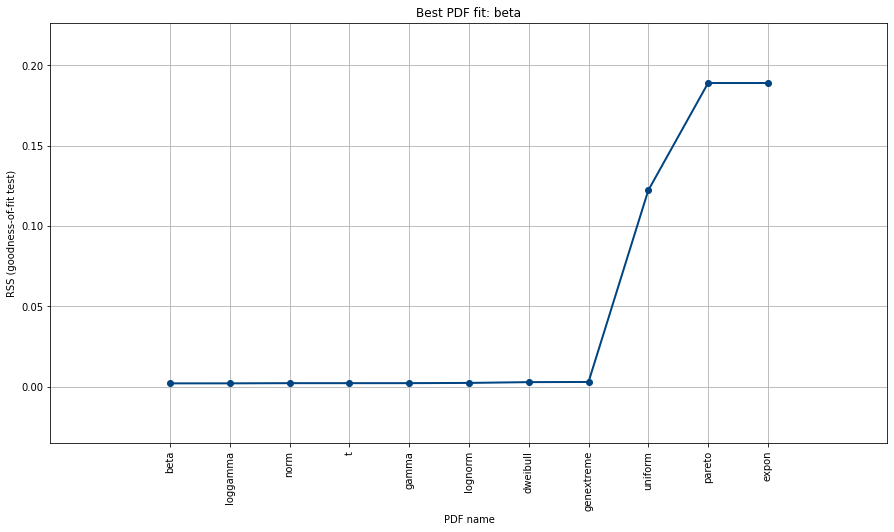
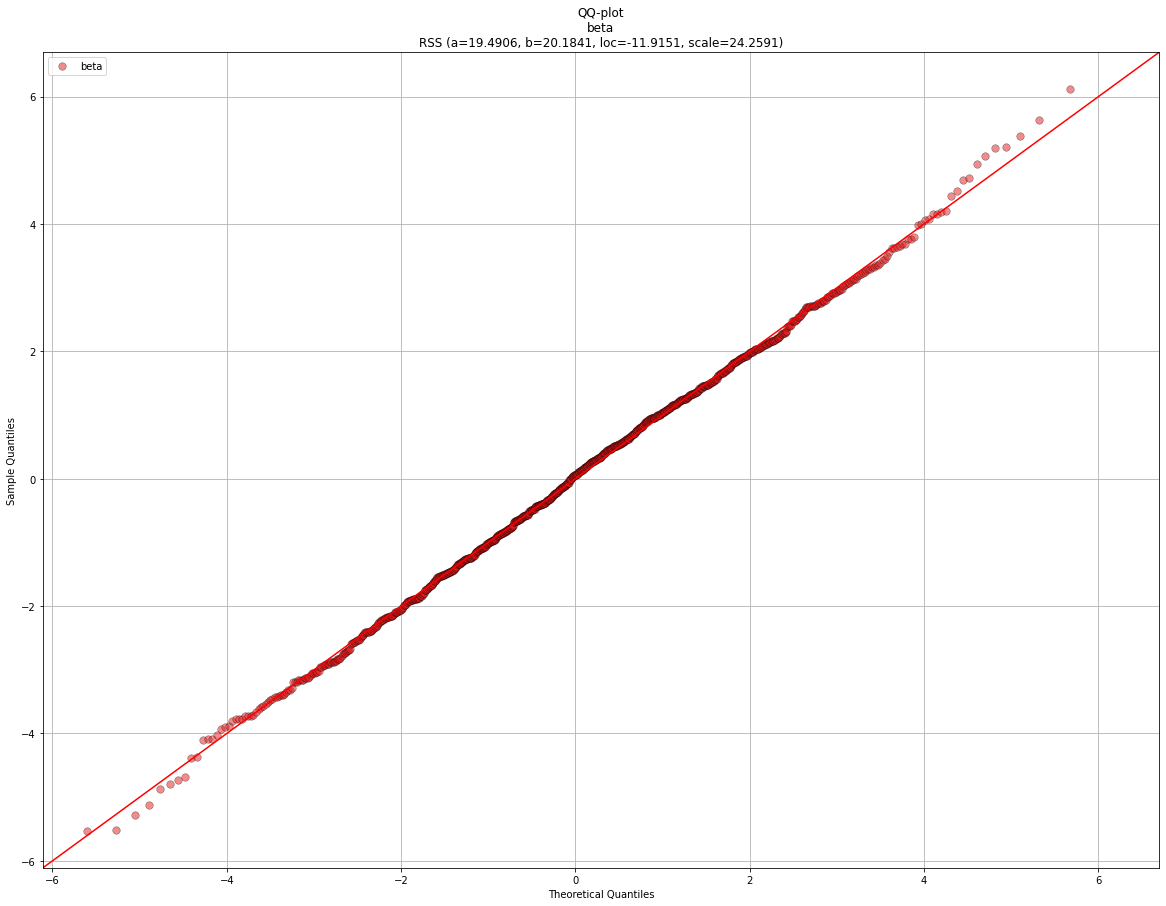
График QQ (квантиль-квантиль) показывает, что он не подходит для усеченной гаммы.
# Make qqplot for the best fit.
dfit.qqplot(X)
# Inspect all other fits
dfit.qqplot(X, n_top=10)

Если подгонка данных здесь не работает, какие другие методы я могу использовать для этого?
Вы можете использовать непараметрические методы:
# Quantile method
dfit = distfit(method='quantile')
# Percentile method
dfit = distfit(method='percentile')
Любая помощь будет оценена по достоинству.
Отказ от ответственности: я также являюсь автором этого репо.
Возможно, этот пост может помочь.
Я представил пример того, как с помощью OpenTURNS найти наилучшее распределение по критерию BIC.
Вы определяете список "Заводы по распространению"
tested_distributions = [ot.WeibullMaxFactory(), ot.NormalFactory(), ot.UniformFactory()]
тогда ты звонишь
BestModelBIC найти лучший вариант
best_model, best_bic = ot.FittingTest.BestModelBIC(sample, tested_distributions)
В настоящее время вы можете выбрать из 30 доступных "Фабрик" в OpenTURNS (см. Ниже). TruncatedNormalFactory доступен, но еще не TruncatedBetaFactory
print(ot.DistributionFactory.GetContinuousUniVariateFactories())
[Out]:
[ArcsineFactory,
BetaFactory,
BurrFactory,
ChiFactory,
ChiSquareFactory,
DirichletFactory,
ExponentialFactory,
FisherSnedecorFactory,
FrechetFactory,
GammaFactory,
GeneralizedParetoFactory,
GumbelFactory,HistogramFactory,
InverseNormalFactory,
LaplaceFactory,LogisticFactory,
LogNormalFactory,
LogUniformFactory,
MeixnerDistributionFactory,
NormalFactory,
ParetoFactory,
RayleighFactory,
RiceFactory,
StudentFactory,
TrapezoidalFactory,
TriangularFactory,
TruncatedNormalFactory,
UniformFactory,
WeibullMaxFactory,
WeibullMinFactory]
#30