Стандартизируйте переменную по группе - почему среднее всегда равно нулю?
У меня есть следующие данные:
df = pd.DataFrame({'sound': ['A', 'B', 'B', 'A', 'B', 'A'],
'score': [10, 5, 6, 7, 11, 1]})
print(df)
sound score
0 A 10
1 B 5
2 B 6
3 A 7
4 B 11
5 A 1
Если я стандартизирую (то есть Z балл) score переменная, я получаю следующие значения. Смысл нового z столбец в основном 0, с SD 1, оба ожидаются для стандартизированной переменной:
df['z'] = (df['score'] - df['score'].mean())/df['score'].std()
print(df)
print('Mean: {}'.format(df['z'].mean()))
print('SD: {}'.format(df['z'].std()))
sound score z
0 A 10 0.922139
1 B 5 -0.461069
2 B 6 -0.184428
3 A 7 0.092214
4 B 11 1.198781
5 A 1 -1.567636
Mean: -7.401486830834377e-17
SD: 1.0
Тем не менее, что меня на самом деле интересует, так это расчет Z баллов на основе членства в группе (sound). Например, если партитура получена из звука A, преобразуйте это значение в балл Z, используя только среднее значение и SD для звука А. Аналогично, для звуковых оценок B Z будут использоваться только среднее значение и SD для звука B. Это, очевидно, приведет к другим значениям по сравнению с обычным расчетом Z-очков:
df['zg'] = df.groupby('sound')['score'].transform(lambda x: (x - x.mean()) / x.std())
print(df)
print('Mean: {}'.format(df['zg'].mean()))
print('SD: {}'.format(df['zg'].std()))
sound score z zg
0 A 10 0.922139 0.872872
1 B 5 -0.461069 -0.725866
2 B 6 -0.184428 -0.414781
3 A 7 0.092214 0.218218
4 B 11 1.198781 1.140647
5 A 1 -1.567636 -1.091089
Mean: 3.700743415417188e-17
SD: 0.894427190999916
Мой вопрос: почему среднее значение стандартизированных значений для групп (zg) тоже в основном равен 0? Это ожидаемое поведение или есть ошибка в моих расчетах где-то?
z баллы имеют смысл, потому что стандартизация внутри переменной по существу заставляет среднее значение до 0. Но zg значения рассчитываются с использованием различных средних значений и SD для каждой звуковой группы, поэтому я не уверен, почему среднее значение этой новой переменной также было установлено на 0.
Единственная ситуация, когда я вижу, что это происходит, - это если сумма значений> 0 равна сумме значений < 0, которая при усреднении отменяет значение до 0. Это происходит при обычном вычислении Z-баллов, но я удивлен, что это также происходит при работе в нескольких группах, как это...
2 ответа
Я думаю, что это имеет смысл. Если E[abc | def ] ожидание abc дано def), затем в df['zg']:
m1 = E['zg' | sound = 'A'знак равно (0.872872 + 0.218218 -1.091089)/3 ~ 0
m2 = E['zg' | sound = 'B'знак равно (-0.725866 - 0.414781 + 1.140647)/3 ~ 0
а также
E['zg'знак равно (m1+m2)/2 знак равно (0.872872 + 0.218218 -1.091089 -0.725866 - 0.414781 + 1.140647)/6 ~ 0
Да, это ожидаемое поведение.
В причудливых словах, используя закон повторных ожиданий,
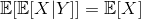
И конкретно, если группы Y конечны и, следовательно, исчисляются,

где
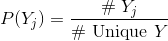
Однако по построению каждый E[X|Y_j] является 0 для всех значений Y в вашем наборе G возможных групп.
Таким образом, общее среднее значение также будет равно нулю.