Может кто-нибудь объяснить мне StandardScaler?
Я не могу понять страницу StandardScaler в документации sklearn,
Кто-нибудь может объяснить мне это простыми словами?
7 ответов
Основная идея состоит в том, чтобы нормализовать / стандартизировать ваши функции перед применением методов машинного обучения.
Одна важная вещь, которую вы должны иметь в виду, это то, что большинство (если не все) scikit-learn модели / классы / функции, ожидайте в качестве входных данных матрицу X с размерами / формой [number_of_samples, number_of_features], Это очень важно. Некоторые другие библиотеки ожидают в качестве входных данных обратное.
StandardScaler() нормализует объекты (каждый столбец X), так что каждый столбец / функция / переменная будет иметь mean = 0 а также standard deviation = 1,
Пример:
from sklearn.preprocessing import StandardScaler
import numpy as np
data = np.array([[0, 0], [0, 0], [1, 1], [1, 1]])
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print(data)
[[0 0]
[0 0]
[1 1]
[1 1]]
print(scaled_data)
[[-1. -1.]
[-1. -1.]
[ 1. 1.]
[ 1. 1.]]
Убедитесь, что среднее значение каждого объекта (столбца) равно 0:
scaled_data.mean(axis = 0)
array([0., 0.])
Убедитесь, что стандартное значение каждой функции (столбца) равно 1:
scaled_data.std(axis = 0)
array([1., 1.])
Идея позади StandardScaler является то, что он преобразует ваши данные так, что его распределение будет иметь среднее значение 0 и стандартное отклонение 1. Учитывая распределение данных, каждое значение в наборе данных будет вычитаться из среднего значения выборки, а затем делится на стандартное отклонение всего набора данных.
StandardScaler выполняет задачу стандартизации. Обычно набор данных содержит переменные разного масштаба. Например, набор данных Employee будет содержать столбец AGE со значениями по шкале 20-70 и столбец SALARY со значениями по шкале 10000-80000.
Поскольку эти два столбца отличаются по масштабу, они стандартизированы, чтобы иметь общий масштаб при построении модели машинного обучения.
Как рассчитать это:

Вы можете прочитать больше здесь:
Это полезно, когда вы хотите сравнить данные, которые соответствуют различным единицам. В этом случае вы хотите удалить единицы. Чтобы сделать это согласованным образом для всех данных, вы должны преобразовать данные таким образом, чтобы дисперсия была унитарной, а среднее значение ряда равнялось 0.
Ниже приведен простой рабочий пример, объясняющий, как работает стандартизация. Часть теории уже хорошо объяснена в других ответах.
>>>import numpy as np
>>>data = [[6, 2], [4, 2], [6, 4], [8, 2]]
>>>a = np.array(data)
>>>np.std(a, axis=0)
array([1.41421356, 0.8660254 ])
>>>np.mean(a, axis=0)
array([6. , 2.5])
>>>from sklearn.preprocessing import StandardScaler
>>>scaler = StandardScaler()
>>>scaler.fit(data)
>>>print(scaler.mean_)
#Xchanged = (X−μ)/σ WHERE σ is Standard Deviation and μ is mean
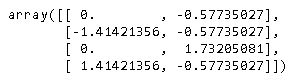
>>>z=scaler.transform(data)
>>>z
расчет
Как вы можете видеть на выходе, среднее значение равно [6., 2.5] и стандартное отклонение [1.41421356, 0.8660254]
Данные (0,1) позиция 2 Стандартизация = (2 - 2,5)/0,8660254 = -0,57735027
Данные в (1,0) позиции: 4 Стандартизация = (4-6)/1,41421356 = -1,414
Результат после стандартизации
Проверьте среднее и стандартное отклонение после стандартизации
Примечание: -2,77555756e-17 очень близко к 0.
Рекомендации
Ответы выше велики, но мне нужен был простой пример, чтобы снять некоторые проблемы, которые у меня были в прошлом. Я хотел убедиться, что он действительно обрабатывает каждую колонку отдельно. Теперь я успокоился и не могу найти, какой пример вызвал у меня беспокойство. Все столбцы масштабируются отдельно, как описано выше.
КОД
import pandas as pd
import scipy.stats as ss
from sklearn.preprocessing import StandardScaler
data= [[1, 1, 1, 1, 1],[2, 5, 10, 50, 100],[3, 10, 20, 150, 200],[4, 15, 40, 200, 300]]
df = pd.DataFrame(data, columns=['N0', 'N1', 'N2', 'N3', 'N4']).astype('float64')
sc_X = StandardScaler()
df = sc_X.fit_transform(df)
num_cols = len(df[0,:])
for i in range(num_cols):
col = df[:,i]
col_stats = ss.describe(col)
print(col_stats)
ВЫХОД
DescribeResult(nobs=4, minmax=(-1.3416407864998738, 1.3416407864998738), mean=0.0, variance=1.3333333333333333, skewness=0.0, kurtosis=-1.3599999999999999)
DescribeResult(nobs=4, minmax=(-1.2828087129930659, 1.3778315806221817), mean=-5.551115123125783e-17, variance=1.3333333333333337, skewness=0.11003776770595125, kurtosis=-1.394993095506219)
DescribeResult(nobs=4, minmax=(-1.155344148338584, 1.53471088361394), mean=0.0, variance=1.3333333333333333, skewness=0.48089217736510326, kurtosis=-1.1471008824318165)
DescribeResult(nobs=4, minmax=(-1.2604572012883055, 1.2668071116222517), mean=-5.551115123125783e-17, variance=1.3333333333333333, skewness=0.0056842140599118185, kurtosis=-1.6438177182479734)
DescribeResult(nobs=4, minmax=(-1.338945389819976, 1.3434309690153527), mean=5.551115123125783e-17, variance=1.3333333333333333, skewness=0.005374558840039456, kurtosis=-1.3619131970819205)
После применения StandardScaler()каждый столбец в X будет иметь среднее значение 0 и стандартное отклонение 1.
Формулы перечислены другими на этой странице.
Обоснование: некоторые алгоритмы требуют, чтобы данные выглядели так (см. Документацию sklearn).
Мы применяем
StandardScalar() на рядной основе.
Итак, для каждой строки в столбце (я предполагаю, что вы работаете с Pandas DataFrame):
x_new = (x_original - mean_of_distribution) / std_of_distribution
Несколько очков -
Это называется стандартным скаляром, поскольку мы делим его на стандартное отклонение распределения (распределение функции). Точно так же вы можете угадать
MinMaxScalar().Исходное распределение остается прежним после применения
StandardScalar(). Это распространенное заблуждение, что распределение меняется на нормальное. Мы просто сжимаем диапазон до [0, 1].