Лоренцу подходит два способа написания кода
Я борюсь прямо сейчас с подгонкой кривой Лоренца. Я постараюсь объяснить мою проблему. Мне нужно написать свой собственный код для подбора кривой Лоренца, чтобы я мог добавить некоторые вещи в уравнения. Я реализовал лоренцевский фит model а также defЯ написал аналогично, но это не работает. Проверьте мой код:
Итак, вот мои данные:
for dataset in [Bxfft]:
dataset = np.asarray(dataset)
freqs, psd = signal.welch(dataset, fs=266336/300, window='hamming', nperseg=16192, scaling='density')
plt.semilogy(freqs[30:-7000], psd[30:-7000]/dataset.size**0, color='r', label='Bx')
x = freqs[100:-7900]
y = psd[100:-7900]
Вот подгонка кривой Лоренца, определенная мной:
def lorentzian(x, amp, cen, sig):
return (amp/np.pi) * (sig/(x-cen)**2 + sig**2)
model = Model(lorentzian)
pars = model.make_params(amp=6, cen=5, sig=1)
pars['amp'].max = 6
result = model.fit(y, pars, x=x)
final_fit = result.best_fit
print(result.fit_report(min_correl=0.25))
plt.plot(x, final_fit, 'k--', linewidth=3)
И здесь сделано по модели функции:
model2 = LorentzianModel()
params2 = model2.make_params(amplitude=6, center=5, sigma=1)
params2['amplitude'].value = 6
result2 = model2.fit(y, params2, x=x)
final_fit2 = result2.best_fit
print(result2.fit_report(min_correl=0.25))
plt.plot(x, final_fit2, 'k--', linewidth=3)
Верхний участок идет за def Лоренцян, а нижний сюжет идет на model Лоренцевы.
И вот результат: 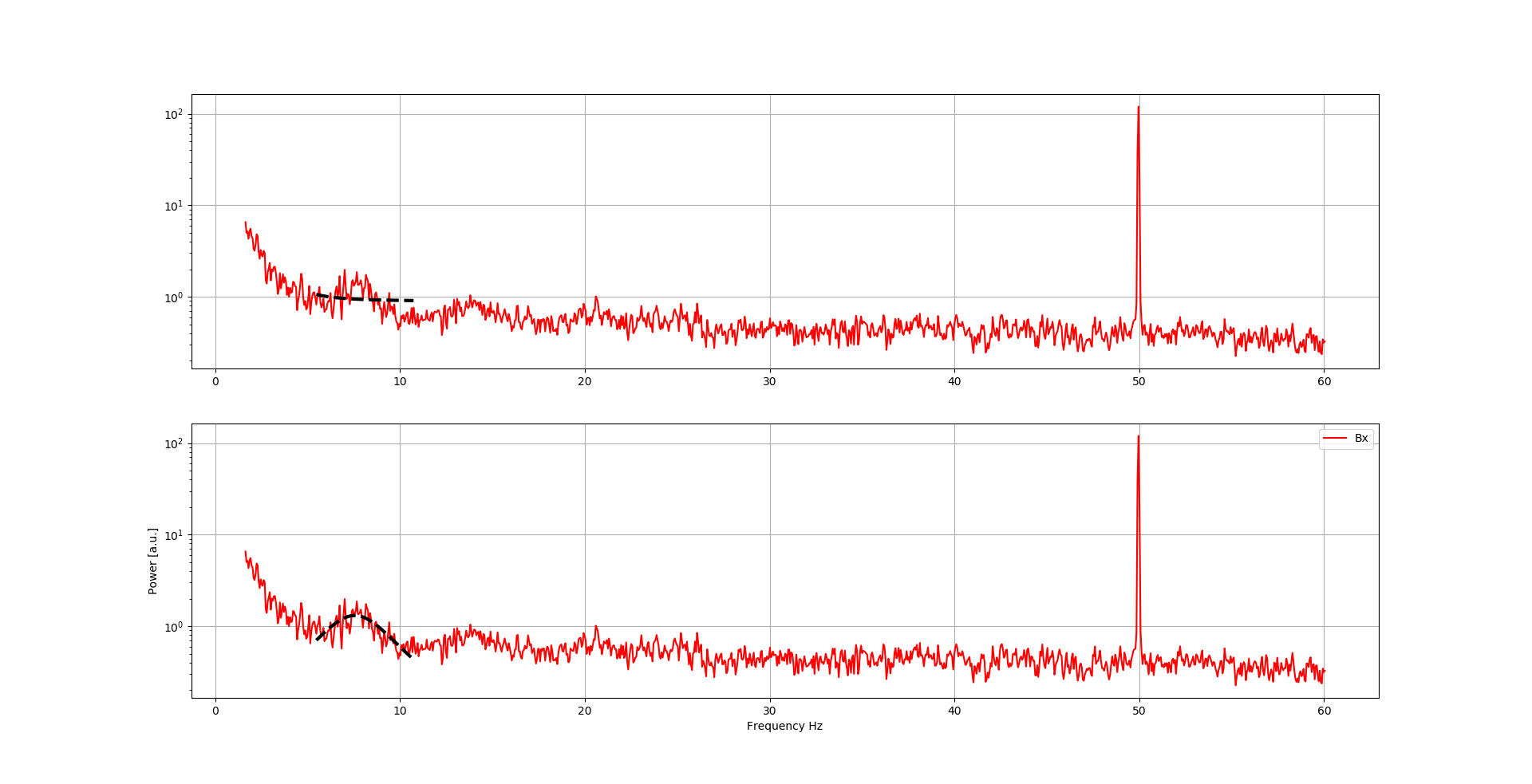
1 ответ
Похоже на проблему с круглыми скобками. Это:
(amp/np.pi) * (sig/(x-cen)**2 + sig**2)
не лоренц. Это:
(amp/np.pi) * (sig/((x-cen)**2 + sig**2))
является. Кроме того, у вас может быть небольшая целочисленная проблема в редком случае cen,x,sig все целые числа. Ты можешь использовать math.pow чтобы решить это, или что они делают в lmfit и умножить x поплавком: 1.0*x-cen,
Как примечание стороны, lmfit по какой-то причине пишет эту функцию эквивалентно, но немного по-другому (найти на странице lorentzian). Я не вижу причины для этого все же.