Как работает процесс отработки отказа Hadoop Namenode?
Полное руководство Hadoop гласит:
Каждый Namenode запускает облегченный процесс контроллера отработки отказа, задача которого состоит в том, чтобы отслеживать его Namenode на наличие сбоев (используя простой механизм биения) и запускать отработку отказа в случае сбоя namenode.
Почему наменоде может что-то запустить, чтобы обнаружить свою ошибку?
Кто посылает сердцебиение кому?
Где этот процесс работает?
Как он обнаруживает ошибку наменода?
Кому это уведомить о переходе?
2 ответа
ZKFailoverController (ZKFC) - это новый компонент, который является клиентом ZooKeeper, который также отслеживает и управляет состоянием NameNode. Каждая из машин, на которой выполняется NameNode, также выполняет ZKFC, и этот ZKFC отвечает за:
Мониторинг работоспособности - ZKFC периодически проверяет свой локальный NameNode с помощью команды проверки работоспособности. До тех пор, пока NameNode своевременно отвечает с исправным состоянием, ZKFC считает узел работоспособным. Если узел вышел из строя, завис или иным образом перешел в неработоспособное состояние, монитор работоспособности помечает его как нездоровый.
Управление сессиями ZooKeeper - когда локальный NameNode исправен, ZKFC держит сессию открытой в ZooKeeper. Если локальный NameNode активен, он также содержит специальный znode " lock ". Эта блокировка использует поддержку ZooKeeper для " эфемерных " узлов; если сеанс истекает, узел блокировки будет автоматически удален.
Выбор на основе ZooKeeper - если локальный NameNode исправен и ZKFC видит, что ни один другой узел в настоящее время не содержит блокировку znode, он сам попытается получить блокировку. Если это удается, то он " выиграл выборы " и отвечает за запуск отработки отказа, чтобы сделать свой локальный NameNode активным.
Взгляните на этот Apache PDF, который является частью проблемы HDR-2185 JIRA
Слайд 16 из
http://www.slideshare.net/cloudera/hdfs-update-lipcon-federal-big-data-apache-hadoop-forum
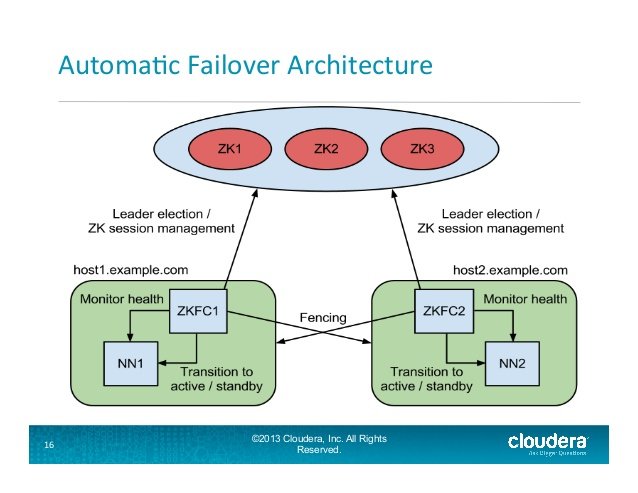 :
:
Автоматический процесс отработки отказа Namenode в Hadoop:
В типичном кластере высокой доступности две отдельные машины настроены как узлы имен. В любой момент времени ровно один из узлов имен находится в активном состоянии, а другой - в режиме ожидания. Active NameNode отвечает за все клиентские операции в кластере, в то время как Standby просто выступает в качестве подчиненного, поддерживая достаточно состояния, чтобы обеспечить быстрое переключение при сбое в случае необходимости.
Чтобы резервный Namenode поддерживал синхронизацию своего состояния с активным Namenode, оба узла связываются с группой отдельных демонов, называемых JournalNodes (JNs).
Когда активный узел выполняет какое-либо изменение пространства имен, он длительно записывает запись об изменении в большинство этих JN. Резервный узел считывает эти изменения из JN и применяет к своему собственному пространству имен.
В случае аварийного переключения Standby гарантирует, что он прочитал все изменения из узлов JounalNode, прежде чем перейти в активное состояние. Это гарантирует, что состояние пространства имен будет полностью синхронизировано до того, как произойдет аварийное переключение.
Для кластера высокой доступности важно, чтобы только один из NameNodes был активным одновременно. ZooKeeper использовался, чтобы избежать сценария разделения мозга, чтобы состояние узла имени не отклонялось из-за аварийного переключения.
Слайд 8 с: http://www.slideshare.net/cloudera/hdfs-futures-world2012-widescreen
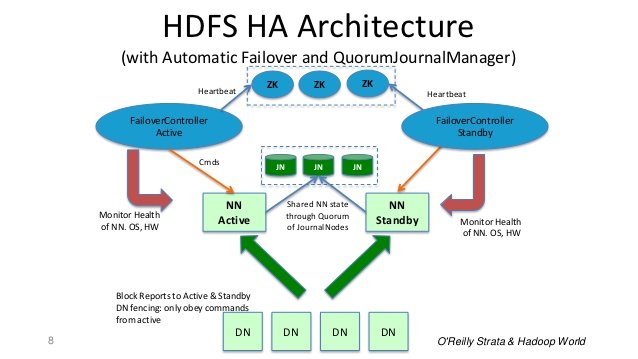 :
:
В итоге: Name Node - это Daemon, а контроллер Failover - это Daemon. Если происходит сбой в работе Name Node Daemon, контроллер Failover Daemon обнаруживает и предпринимает корректирующие действия. Даже если вся машина выйдет из строя, сервер ZooKeeper обнаружит ее, и срок действия блокировки истечет, а другой резервный узел имени будет выбран в качестве узла активного имени.
Согласно документации Hadoop, которую вы можете найти здесь , для реализации автоматического переключения при сбое необходимо добавить несколько вещей в развертывание HDFS:
1: кворум смотрителя зоопарка
2: процесс ZKFailoverController.
Чтобы ответить на ваши вопросы из документации:
Каждый из компьютеров NameNode в кластере поддерживает постоянный сеанс в ZooKeeper. В случае сбоя машины сеанс ZooKeeper истечет, уведомив другой NameNode о том, что следует запустить аварийное переключение.
Итак, чтобы ответить на ваши вопросы:
Вопрос: Как получается, что именный узел может запустить что-то, чтобы обнаружить собственный сбой?
О: Каждый узел имени поддерживает сеанс ZooKeeper через службу ZKFailoverController (ZKFC), которая работает на том же компьютере. По истечении срока действия этого сеанса другой узел имени будет уведомлен о том, что необходимо запустить аварийное переключение.
Монитор работоспособности ZKFC также периодически пингует свой локальный узел имени (это ваше сердцебиение), если узел имени выходит из строя, монитор работоспособности помечает этот узел имени как неработоспособный.
Когда вышедший из строя узел имени исправен и является активным узлом имени, он поддерживает специальный «блокирующий» узел. Когда узел имени помечен как неработоспособный, эта блокировка удаляется. Когда другой узел имени увидит, что ни один другой узел в настоящее время не удерживает znode блокировки, он попытается получить блокировку. Если он это сделает, то он станет активным узлом имени.
Вопрос: Кто кому отправляет пульс? Как он обнаруживает сбой узла имени?
А: Опять. Сессия ZooKeeper.
Вопрос: Где выполняется этот процесс?
О: Вы можете установить ZooKeeper на один компьютер или в кластер. Вы можете прочитать документацию здесь .
Вопрос: Кого уведомить о переходе?
О: Все это обрабатывается процессом ZKFailoverController, запущенным на каждом компьютере.
Здесь есть еще одна хорошая статья , которая визуализирует это немного лучше моих слов.