Являются ли "гонки данных" и "условия гонки" фактически одним и тем же в контексте параллельного программирования
Я часто нахожу эти термины в контексте параллельного программирования. Они одно и то же или разные?
6 ответов
Нет, они не одно и то же. Они не являются подмножеством друг друга. Они также не являются ни необходимым, ни достаточным условием друг для друга.
Определение гонки данных довольно ясно, и, следовательно, ее обнаружение может быть автоматизировано. Гонка данных происходит, когда 2 инструкции из разных потоков обращаются к одной и той же ячейке памяти, по крайней мере, один из этих обращений является записью, и нет синхронизации, которая предписывает какой-либо конкретный порядок среди этих обращений.
Состояние гонки - это семантическая ошибка. Это недостаток, возникающий при синхронизации или упорядочении событий, который приводит к ошибочному поведению программы. Многие гонки могут быть вызваны данными гонками, но это не обязательно.
Рассмотрим следующий простой пример, где x является общей переменной:
Thread 1 Thread 2
lock(l) lock(l)
x=1 x=2
unlock(l) unlock(l)
В этом примере записи в x из потока 1 и 2 защищены блокировками, поэтому они всегда происходят в некотором порядке, который обеспечивается порядком, в котором блокировки получаются во время выполнения. То есть атомарность писем не может быть нарушена; всегда происходит, прежде чем отношения между двумя записями в любом выполнении. Мы просто не можем знать, какая запись происходит раньше другой априори.
Между записями нет фиксированного порядка, потому что блокировки не могут этого обеспечить. Если правильность программ нарушена, скажем, когда запись в x по потоку 2 сопровождается записью в x в потоке 1, мы говорим, что существует условие состязания, хотя технически нет состязания данных.
Гораздо полезнее определять условия гонки, чем гонки данных; однако этого также очень трудно достичь.
Построение обратного примера также тривиально. Этот пост в блоге также очень хорошо объясняет разницу на простом примере банковской транзакции.
Согласно Википедии, термин "состояние гонки" использовался со времен первых электронных логических элементов. В контексте Java условие гонки может относиться к любому ресурсу, такому как файл, сетевое соединение, поток из пула потоков и т. Д.
Термин "гонка данных" лучше всего зарезервировать для его конкретного значения, определенного JLS.
Самый интересный случай - это состояние гонки, которое очень похоже на гонку данных, но все же не такое, как в этом простом примере:
class Race {
static volatile int i;
static int uniqueInt() { return i++; }
}
поскольку i изменчив, нет гонки данных; однако, с точки зрения правильности программы, из-за неатомичности двух операций возникает условие состязания: чтение i, записывать i+1, Несколько потоков могут получить одно и то же значение от uniqueInt,
TL;DR: различие между гонкой данных и состоянием гонки зависит от характера формулировки проблемы и от того, где провести границу между неопределенным поведением и четко определенным, но неопределенным поведением. Текущее различие условно и лучше всего отражает интерфейс между архитектором процессора и языком программирования.
1. Семантика
Гонка данных, в частности, относится к несинхронизированным конфликтующим "доступам к памяти" (или действиям, или операциям) к одному и тому же участку памяти. Если в доступе к памяти нет конфликта, но все еще существует неопределенное поведение, вызванное упорядочением операций, это состояние гонки.
Обратите внимание, что "доступ к памяти" здесь имеет особое значение. Они относятся к "чистой" загрузке памяти или действиям сохранения без какой-либо дополнительной семантики. Например, хранилище памяти из одного потока не обязательно (обязательно) знает, сколько времени требуется, чтобы данные были записаны в память и, наконец, передаются в другой поток. В качестве другого примера, сохранение в памяти одного места перед другим сохранением в другом месте одним и тем же потоком не (обязательно) гарантирует, что первые данные, записанные в память, будут впереди вторых. В результате порядок этих обращений к чистой памяти не (обязательно) может быть "обоснован", и все может произойти, если иное не определено четко.
Когда "доступы к памяти" четко определены с точки зрения упорядочения посредством синхронизации, дополнительная семантика может гарантировать, что даже если время доступа к памяти является неопределенным, их порядок можно "обосновать" посредством синхронизации. Обратите внимание, хотя порядок между обращениями к памяти можно обосновать, они не обязательно являются определяющими, отсюда и состояние гонки.
2. Почему разница?
Но если порядок все еще не определен в состоянии гонки, зачем вообще отличать его от гонки данных? Причина скорее практическая, чем теоретическая. Это потому, что существует различие в интерфейсе между языком программирования и архитектурой процессора.
Команда загрузки / сохранения памяти в современной архитектуре обычно реализуется как "чистый" доступ к памяти из-за природы неупорядоченного конвейера, предположений, многоуровневого кеширования, взаимодействия ЦП и ОЗУ, особенно многоядерных и т. Д. Есть много факторов, которые приводят к неопределенности в выборе времени и порядка. Принуждение к упорядочиванию каждой инструкции памяти влечет за собой огромные штрафы, особенно в конструкции процессора, поддерживающей многоядерность. Таким образом, семантика упорядочивания снабжена дополнительными инструкциями, такими как различные барьеры (или ограждения).
Гонка данных - это ситуация выполнения инструкций процессора без дополнительных ограждений, помогающих обосновать порядок конфликтующих обращений к памяти. Результат не только неопределенный, но также, возможно, очень странный, например, две записи в одно и то же место слова разными потоками могут происходить с каждой записывающей половиной слова или могут работать только с их локально кэшированными значениями. - Это неопределенное поведение с точки зрения программиста. Но они (обычно) хорошо определены с точки зрения архитектора процессора.
Программисты должны иметь способ обосновать выполнение своего кода. Гонка за данными - это то, что они не могут иметь смысла, поэтому всегда следует избегать (обычно). Вот почему спецификации языка на достаточно низком уровне обычно определяют гонку данных как неопределенное поведение, отличное от четко определенного поведения памяти в состоянии гонки.
3. Модели языковой памяти
Различные процессоры могут иметь разное поведение доступа к памяти, т. Е. Модель памяти процессора. Программистам неудобно изучать модель памяти каждого современного процессора, а затем разрабатывать программы, которые могут извлечь из них пользу. Желательно, чтобы язык мог определять модель памяти, чтобы программы на этом языке всегда вели себя так, как ожидалось, как это определяет модель памяти. Вот почему в Java и C++ определены свои модели памяти. Разработчики компилятора / среды выполнения обязаны обеспечить применение моделей языковой памяти для разных архитектур процессоров.
Тем не менее, если язык не хочет раскрывать низкоуровневое поведение процессора (и готов пожертвовать некоторыми преимуществами производительности современных архитектур), он может выбрать модель памяти, которая полностью скрывает детали "чистого" обращается к памяти, но применяет семантику упорядочения для всех своих операций с памятью. Затем разработчики компилятора / среды выполнения могут выбрать обработку каждой переменной памяти как изменчивой во всех архитектурах процессора. Для этих языков (которые поддерживают совместную память между потоками) не существует гонок данных, но все же могут быть условия гонки, даже с языком полной последовательной согласованности.
С другой стороны, модель памяти процессора может быть более строгой (или менее расслабленной, или на более высоком уровне), например, реализовывать последовательную согласованность, как это делал первые процессоры. Затем все операции с памятью упорядочиваются, и никакая гонка данных не существует ни для каких языков, работающих в процессоре.
4. Вывод
Вернемся к исходному вопросу, ИМХО, это нормально определять гонку данных как частный случай состояния гонки, а состояние гонки на одном уровне может стать гонкой данных на более высоком уровне. Это зависит от характера постановки проблемы и от того, где провести границу между неопределенным поведением и четко определенным, но неопределенным поведением. Просто текущее соглашение определяет границу в интерфейсе язык-процессор, не обязательно означает, что это всегда и должно быть так; но текущее соглашение, вероятно, лучше всего отражает современный интерфейс (и мудрость) между архитектором процессора и языком программирования.
Для меня данные гонки - это подмножество всех условий гонки. Гонки данных происходят, когда два или более потоков обращаются к одной и той же памяти без надлежащей блокировки, что может привести к неожиданным значениям (если у вас есть хотя бы один поток, выполняющий запись).
Термин условие гонки в общем случае может также относиться, например, к потокам, которые время от времени блокируются из-за гонок в планировании потоков (и ненадлежащего использования механизмов блокировки).
Нет, они разные, и ни один из них не является подмножеством одного или наоборот.
Термин условие гонки часто путают со связанным термином гонки данных, который возникает, когда синхронизация не используется для координации всего доступа к совместно используемому нефинальному полю. Вы рискуете гонкой данных, когда поток записывает переменную, которая затем может быть прочитана другим потоком, или читает переменную, которая могла быть в последний раз записана другим потоком, если оба потока не используют синхронизацию; код с гонками данных не имеет полезной определенной семантики в рамках модели памяти Java. Не все состязания являются состязаниями данных, и не все состязания данных являются состояниями состязаний, но они оба могут привести к сбою параллельных программ непредсказуемым образом.
Взято из превосходной книги " Параллелизм Java на практике" Джошуа Блоха и Ко.
Гонки данных и состояние гонки
[Атомарность, видимость, упорядоченность]
На мой взгляд, это определенно две разные вещи.
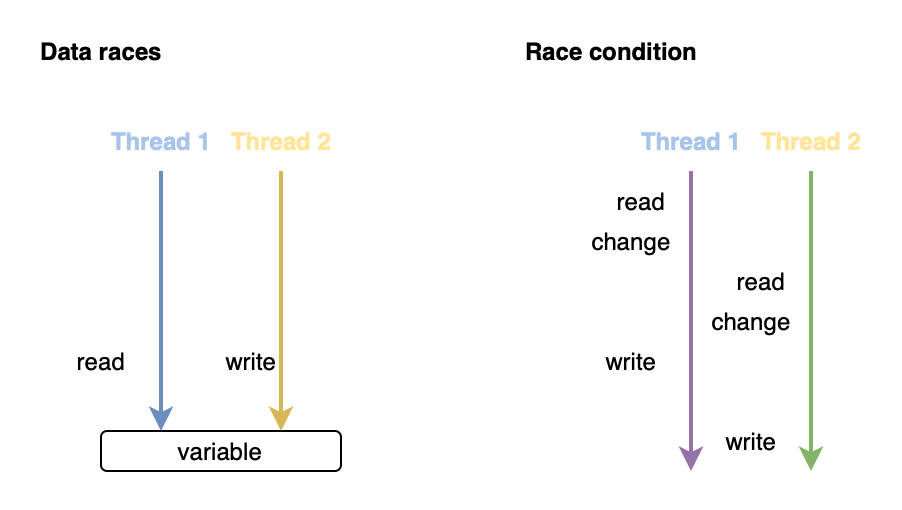
это ситуация, когда одна и та же память распределяется между несколькими потоками (по крайней мере, один из них изменяет ее (доступ для записи)) без синхронизации
это ситуация, когда несинхронизированные блоки кода (могут быть одинаковыми), использующие один и тот же общий ресурс, выполняются одновременно в разных потоках и результат которых непредсказуем.
Примеры:
//increment variable
1. read variable
2. change variable
3. write variable
//cache mechanism
1. check if exists in cache and if not
2. load
3. cache
Решение:
и являются проблемой атомарности, и их можно решить с помощью механизма синхронизации.
-
Data races- При записи доступ к общей переменной будет синхронизирован -
Race condition- Когда блок кода запускается как атомарная операция