Понимание макетов памяти переводчика (JVM/JS)
Я пытаюсь понять структуру памяти процесса на уровне операционной системы, и мы привыкли к этой диаграмме. 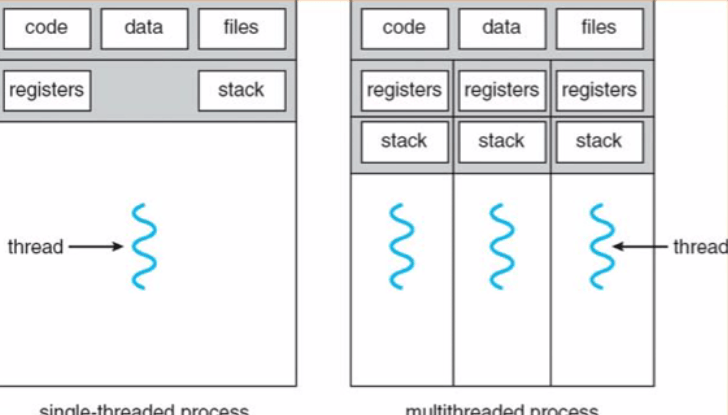
Забудьте многопоточную часть диаграммы, но теперь для общих целей мы предполагаем, что блок "кода", показанный на диаграмме выше, является двоичными инструкциями нашей программы. Это предполагает, что код уже скомпилирован и теперь доступен в двоичном виде. Но как насчет интерпретируемых языков, например, байт-кода, который должен выполняться интерпретатором JVM. Пока я выбираю интерпретатор JVM здесь, мой вопрос касается любого интерпретируемого языка и того, как он вписывается в диаграмму, показанную выше. Насколько я понимаю, сам Интерпретатор - это программа, и поэтому он должен находиться в блоке кода, показанном на диаграмме выше, а программа.class в случае Java или файл.js в случае интерпретаторов Javascript является "аргументом", так что говорят, что этот интерпретатор работает, чтобы перевести их в OS/ машинный код, который затем выполняется. Запросите ваши мысли по этому поводу.
1 ответ
Вопрос о том, будете ли вы считать байт-код "кодом", зависит от перспективы. Терминология немного нечеткая.
"Код" на диаграмме - это собственный исполняемый код, т. Е. Ваш интерпретатор. Что касается процессора и операционной системы, то это единственный код, который когда-либо запускался. Для ОС интерпретируемый байт-код - это просто данные, с которыми работает настоящий нативный код.
То, что в этом случае данные также являются формой инструкций, является деталью, о которой процессор не знает и не заботится.