Проблема общей памяти CUDA
Как-то, когда я изменяю d_updated_water_flow_map в приведенном ниже коде, d_terrain_height_map модифицируется тоже / вместо.
Изменение порядка размещения для двух массивов устраняет проблему, но я предполагаю, что это только маскировка основной причины проблемы.
cudaCheck(cudaMalloc((void **)&d_water_flow_map, SIZE * 4));
cudaCheck(cudaMalloc((void **)&d_updated_water_flow_map, SIZE * 4)); // changing this array also changes d_terrain_height_map
cudaCheck(cudaMalloc((void **)&d_terrain_height_map, SIZE));
Я собираю ядро в DLL и вызываю его из-под файла python внутри интерпретатора Python 3D Blender. Все значения являются 32-битными числами с плавающей запятой.
cu_include.h
#pragma once
#ifdef MATHLIBRARY_EXPORTS
#define MATHLIBRARY_API __declspec(dllexport)
#else
#define MATHLIBRARY_API __declspec(dllimport)
#endif
extern "C" __declspec(dllexport)
void init(float *t_height_map,
float *w_height_map,
float *s_height_map,
int SIZE_X,
int SIZE_Y);
extern "C" __declspec(dllexport)
void run_hydro_erosion(int cycles,
float t_step,
float min_tilt_angle,
float SEDIMENT_CAP,
float DISSOLVE_CONST,
float DEPOSIT_CONST,
int SIZE_X,
int SIZE_Y,
float PIPE_LENGTH,
float ADJACENT_LENGTH,
float TIME_STEP,
float MIN_TILT_ANGLE);
extern "C" __declspec(dllexport)
void free_mem();
extern "C" __declspec(dllexport)
void procedural_rain(float *water_height_map, float *rain_map, int SIZE_X, int SIZE_Y);
erosion_kernel.dll
#include "cu_include.h"
// includes, system
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <math.h>
#include <time.h>
#include <iostream>
#include <algorithm>
#include <random>
// includes CUDA
#include <cuda_runtime.h>
using namespace std;
#define FLOW_RIGHT 0
#define FLOW_UP 1
#define FLOW_LEFT 2
#define FLOW_DOWN 3
#define X_VEL 0
#define Y_VEL 1
#define LEFT_CELL row, col - 1
#define RIGHT_CELL row, col + 1
#define ABOVE_CELL row - 1, col
#define BELOW_CELL row + 1, col
// CUDA API error checking macro
#define T 1024
#define M 1536
#define blockSize 1024
#define cudaCheck(error) \
if (error != cudaSuccess) { \
printf("Fatal error: %s at %s:%d\n", \
cudaGetErrorString(error), \
__FILE__, __LINE__); \
exit(1); \
}
__global__ void update_water_flow(float *water_height_map, float *water_flow_map, float *d_updated_water_flow_map, int SIZE_X, int SIZE_Y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int col = index % SIZE_X;
int row = index / SIZE_X;
index = row * (SIZE_X * 4) + col * 4; // 3D index
d_updated_water_flow_map[index + FLOW_RIGHT] = 0;
d_updated_water_flow_map[index + FLOW_UP] = 0;
d_updated_water_flow_map[index + FLOW_LEFT] = 0;
d_updated_water_flow_map[index + FLOW_DOWN] = 0;
}
static float *terrain_height_map;
static float *water_height_map;
static float *sediment_height_map;
void init(float *t_height_map,
float *w_height_map,
float *s_height_map,
int SIZE_X,
int SIZE_Y)
{
/* set vars HOST*/
terrain_height_map = t_height_map;
water_height_map = w_height_map;
sediment_height_map = s_height_map;
}
void run_hydro_erosion(int cycles,
float t_step,
float min_tilt_angle,
float SEDIMENT_CAP,
float DISSOLVE_CONST,
float DEPOSIT_CONST,
int SIZE_X,
int SIZE_Y,
float PIPE_LENGTH,
float ADJACENT_LENGTH,
float TIME_STEP,
float MIN_TILT_ANGLE)
{
int numBlocks = (SIZE_X * SIZE_Y + (blockSize - 1)) / blockSize;
int SIZE = SIZE_X * SIZE_Y * sizeof(float);
float *d_terrain_height_map, *d_updated_terrain_height_map;
float *d_water_height_map, *d_updated_water_height_map;
float *d_sediment_height_map, *d_updated_sediment_height_map;
float *d_suspended_sediment_level;
float *d_updated_suspended_sediment_level;
float *d_water_flow_map;
float *d_updated_water_flow_map;
float *d_prev_water_height_map;
float *d_water_velocity_vec;
float *d_rain_map;
cudaCheck(cudaMalloc(&d_water_height_map, SIZE));
cudaCheck(cudaMalloc(&d_updated_water_height_map, SIZE));
cudaCheck(cudaMalloc(&d_prev_water_height_map, SIZE));
cudaCheck(cudaMalloc(&d_water_flow_map, SIZE * 4));
cudaCheck(cudaMalloc(&d_updated_water_flow_map, SIZE * 4)); // changing this array also changes d_terrain_height_map
cudaCheck(cudaMalloc(&d_terrain_height_map, SIZE));
cudaCheck(cudaMalloc(&d_updated_terrain_height_map, SIZE));
cudaCheck(cudaMalloc(&d_sediment_height_map, SIZE));
cudaCheck(cudaMalloc(&d_updated_sediment_height_map, SIZE));
cudaCheck(cudaMalloc(&d_suspended_sediment_level, SIZE));
cudaCheck(cudaMalloc(&d_updated_suspended_sediment_level, SIZE));
cudaCheck(cudaMalloc(&d_rain_map, SIZE));
cudaCheck(cudaMalloc(&d_water_velocity_vec, SIZE * 2));
cudaCheck(cudaMemcpy(d_terrain_height_map, terrain_height_map, SIZE, cudaMemcpyHostToDevice));
cudaCheck(cudaMemcpy(d_water_height_map, water_height_map, SIZE, cudaMemcpyHostToDevice));
cudaCheck(cudaMemcpy(d_sediment_height_map, sediment_height_map, SIZE, cudaMemcpyHostToDevice));
cout << "init terrain_height_map" << endl;
for (int i = 0; i < SIZE_X * SIZE_Y; i++) {
cout << terrain_height_map[i] << ", ";
if (i % SIZE_X == 0 && i != 0) cout << endl;
}
/* launch the kernel on the GPU */
float *temp;
while (cycles--) {
update_water_flow << < numBlocks, blockSize >> >(d_water_height_map, d_water_flow_map, d_updated_water_flow_map, SIZE_X, SIZE_Y);
temp = d_water_flow_map;
d_water_flow_map = d_updated_water_flow_map;
d_updated_water_flow_map = temp;
}
cudaCheck(cudaMemcpy(terrain_height_map, d_terrain_height_map, SIZE, cudaMemcpyDeviceToHost));
cout << "updated terrain" << endl;
for (int i = 0; i < SIZE_X * SIZE_Y; i++) {
cout << terrain_height_map[i] << ", ";
if (i % SIZE_X == 0 && i != 0) cout << endl;
}
}
Файл Python
import bpy
import numpy
import ctypes
import random
width = 4
height = 4
size_x = width
size_y = height
N = size_x * size_y
scrpt_cycles = 1
kernel_cycles = 1
time_step = 0.005
pipe_length = 1.0
adjacent_length = 1.0
min_tilt_angle = 10
sediment_cap = 0.01
dissolve_const = 0.01
deposit_const = 0.01
# initialize arrays
ter_height_map = numpy.ones((N), dtype=numpy.float32)
water_height_map = numpy.zeros((N), dtype=numpy.float32)
sed_height_map = numpy.zeros((N), dtype=numpy.float32)
rain_map = numpy.ones((N), dtype=numpy.float32)
# load terrain height from image
for i in range(0, len(ter_height_map)):
ter_height_map[i] = 1
# import DLL
E = ctypes.cdll.LoadLibrary("E:/Programming/CUDA/erosion/Release/erosion_kernel.dll")
# initialize device memory
E.init( ctypes.c_void_p(ter_height_map.ctypes.data),
ctypes.c_void_p(water_height_map.ctypes.data),
ctypes.c_void_p(sed_height_map.ctypes.data),
ctypes.c_int(size_x),
ctypes.c_int(size_y))
# run erosion
while(scrpt_cycles):
scrpt_cycles = scrpt_cycles - 1
E.run_hydro_erosion(ctypes.c_int(kernel_cycles),
ctypes.c_float(time_step),
ctypes.c_float(min_tilt_angle),
ctypes.c_float(sediment_cap),
ctypes.c_float(dissolve_const),
ctypes.c_float(deposit_const),
ctypes.c_int(size_x),
ctypes.c_int(size_y),
ctypes.c_float(pipe_length),
ctypes.c_float(adjacent_length),
ctypes.c_float(time_step),
ctypes.c_float(min_tilt_angle))
Неверный вывод:
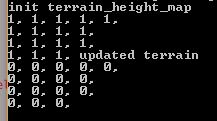
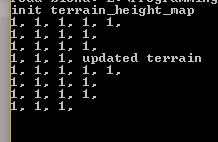
Ожидаемый результат (после того, как я закомментирую update_water_flow):
//update_water_flow << < numBlocks, blockSize >> >(d_water_height_map, d_water_flow_map, d_updated_water_flow_map, SIZE_X, SIZE_Y);
Видеокарта: GTX460M
1 ответ
Проблема здесь в том, что ядро записывало вне пределов, и, по-видимому, компилятор / среда выполнения располагали выделения достаточно близко в памяти устройства, что превышение границ в первом выделении приводило к записи кода во второе выделение:
cudaCheck(cudaMalloc(&d_updated_water_flow_map, SIZE * 4)); // changing this array also changes d_terrain_height_map
cudaCheck(cudaMalloc(&d_terrain_height_map, SIZE));
Доступ за пределы допустимого происходит из-за того, что запуск ядра включает в себя более чем достаточное количество потоков (в данном случае он запускает 1024 потока), тогда как на самом деле нам только "нужно" SIZE_X*SIZE_Y темы (т.е. 16 в этом примере):
#define blockSize 1024
...
int numBlocks = (SIZE_X * SIZE_Y + (blockSize - 1)) / blockSize;
...
update_water_flow << < numBlocks, blockSize >> >(d_water_height_map, d_water_flow_map, d_updated_water_flow_map, SIZE_X, SIZE_Y);
Это, конечно, "типично" в программировании на CUDA, запускать более чем достаточное количество потоков, но при этом важно включить "проверку потока" в ядре, чтобы не допустить, чтобы любые "лишние" потоки сделали любые недопустимые из доступ. В этом случае одна из возможных проверок потока ядра может быть такой:
if ((row >= SIZE_Y) || (col >= SIZE_X)) return;
Вот полностью проработанный пример, основанный на предоставленном коде (хотя и на linux и удалении зависимости blender в коде python), демонстрирующий эффект до и после. Обратите внимание, что мы можем запустить даже такой код с cuda-memcheck, который в этом случае указал бы на недозволенный доступ (для ясности опущен в первом примере ниже):
$ cat t383.cu
extern "C"
void init(float *t_height_map,
float *w_height_map,
float *s_height_map,
int SIZE_X,
int SIZE_Y);
extern "C"
void run_hydro_erosion(int cycles,
float t_step,
float min_tilt_angle,
float SEDIMENT_CAP,
float DISSOLVE_CONST,
float DEPOSIT_CONST,
int SIZE_X,
int SIZE_Y,
float PIPE_LENGTH,
float ADJACENT_LENGTH,
float TIME_STEP,
float MIN_TILT_ANGLE);
extern "C"
void free_mem();
extern "C"
void procedural_rain(float *water_height_map, float *rain_map, int SIZE_X, int SIZE_Y);
// includes, system
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <math.h>
#include <time.h>
#include <iostream>
#include <algorithm>
#include <random>
// includes CUDA
#include <cuda_runtime.h>
using namespace std;
#define FLOW_RIGHT 0
#define FLOW_UP 1
#define FLOW_LEFT 2
#define FLOW_DOWN 3
#define X_VEL 0
#define Y_VEL 1
#define LEFT_CELL row, col - 1
#define RIGHT_CELL row, col + 1
#define ABOVE_CELL row - 1, col
#define BELOW_CELL row + 1, col
// CUDA API error checking macro
#define T 1024
#define M 1536
#define blockSize 1024
#define cudaCheck(error) \
if (error != cudaSuccess) { \
printf("Fatal error: %s at %s:%d\n", \
cudaGetErrorString(error), \
__FILE__, __LINE__); \
exit(1); \
}
__global__ void update_water_flow(float *water_height_map, float *water_flow_map, float *d_updated_water_flow_map, int SIZE_X, int SIZE_Y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int col = index % SIZE_X;
int row = index / SIZE_X;
index = row * (SIZE_X * 4) + col * 4; // 3D index
#ifdef FIX
if ((row >= SIZE_Y) || (col >= SIZE_X)) return;
#endif
d_updated_water_flow_map[index + FLOW_RIGHT] = 0;
d_updated_water_flow_map[index + FLOW_UP] = 0;
d_updated_water_flow_map[index + FLOW_LEFT] = 0;
d_updated_water_flow_map[index + FLOW_DOWN] = 0;
}
static float *terrain_height_map;
static float *water_height_map;
static float *sediment_height_map;
void init(float *t_height_map,
float *w_height_map,
float *s_height_map,
int SIZE_X,
int SIZE_Y)
{
/* set vars HOST*/
terrain_height_map = t_height_map;
water_height_map = w_height_map;
sediment_height_map = s_height_map;
}
void run_hydro_erosion(int cycles,
float t_step,
float min_tilt_angle,
float SEDIMENT_CAP,
float DISSOLVE_CONST,
float DEPOSIT_CONST,
int SIZE_X,
int SIZE_Y,
float PIPE_LENGTH,
float ADJACENT_LENGTH,
float TIME_STEP,
float MIN_TILT_ANGLE)
{
int numBlocks = (SIZE_X * SIZE_Y + (blockSize - 1)) / blockSize;
int SIZE = SIZE_X * SIZE_Y * sizeof(float);
float *d_terrain_height_map, *d_updated_terrain_height_map;
float *d_water_height_map, *d_updated_water_height_map;
float *d_sediment_height_map, *d_updated_sediment_height_map;
float *d_suspended_sediment_level;
float *d_updated_suspended_sediment_level;
float *d_water_flow_map;
float *d_updated_water_flow_map;
float *d_prev_water_height_map;
float *d_water_velocity_vec;
float *d_rain_map;
cudaCheck(cudaMalloc(&d_water_height_map, SIZE));
cudaCheck(cudaMalloc(&d_updated_water_height_map, SIZE));
cudaCheck(cudaMalloc(&d_prev_water_height_map, SIZE));
cudaCheck(cudaMalloc(&d_water_flow_map, SIZE * 4));
cudaCheck(cudaMalloc(&d_updated_water_flow_map, SIZE * 4)); // changing this array also changes d_terrain_height_map
cudaCheck(cudaMalloc(&d_terrain_height_map, SIZE));
cudaCheck(cudaMalloc(&d_updated_terrain_height_map, SIZE));
cudaCheck(cudaMalloc(&d_sediment_height_map, SIZE));
cudaCheck(cudaMalloc(&d_updated_sediment_height_map, SIZE));
cudaCheck(cudaMalloc(&d_suspended_sediment_level, SIZE));
cudaCheck(cudaMalloc(&d_updated_suspended_sediment_level, SIZE));
cudaCheck(cudaMalloc(&d_rain_map, SIZE));
cudaCheck(cudaMalloc(&d_water_velocity_vec, SIZE * 2));
cudaCheck(cudaMemcpy(d_terrain_height_map, terrain_height_map, SIZE, cudaMemcpyHostToDevice));
cudaCheck(cudaMemcpy(d_water_height_map, water_height_map, SIZE, cudaMemcpyHostToDevice));
cudaCheck(cudaMemcpy(d_sediment_height_map, sediment_height_map, SIZE, cudaMemcpyHostToDevice));
cout << "init terrain_height_map" << endl;
for (int i = 0; i < SIZE_X * SIZE_Y; i++) {
cout << terrain_height_map[i] << ", ";
if (i % SIZE_X == 0 && i != 0) cout << endl;
}
/* launch the kernel on the GPU */
float *temp;
while (cycles--) {
update_water_flow << < numBlocks, blockSize >> >(d_water_height_map, d_water_flow_map, d_updated_water_flow_map, SIZE_X, SIZE_Y);
temp = d_water_flow_map;
d_water_flow_map = d_updated_water_flow_map;
d_updated_water_flow_map = temp;
}
cudaCheck(cudaMemcpy(terrain_height_map, d_terrain_height_map, SIZE, cudaMemcpyDeviceToHost));
cout << "updated terrain" << endl;
for (int i = 0; i < SIZE_X * SIZE_Y; i++) {
cout << terrain_height_map[i] << ", ";
if (i % SIZE_X == 0 && i != 0) cout << endl;
}
}
$ cat t383.py
import numpy
import ctypes
import random
width = 4
height = 4
size_x = width
size_y = height
N = size_x * size_y
scrpt_cycles = 1
kernel_cycles = 1
time_step = 0.005
pipe_length = 1.0
adjacent_length = 1.0
min_tilt_angle = 10
sediment_cap = 0.01
dissolve_const = 0.01
deposit_const = 0.01
# initialize arrays
ter_height_map = numpy.ones((N), dtype=numpy.float32)
water_height_map = numpy.zeros((N), dtype=numpy.float32)
sed_height_map = numpy.zeros((N), dtype=numpy.float32)
rain_map = numpy.ones((N), dtype=numpy.float32)
# load terrain height from image
for i in range(0, len(ter_height_map)):
ter_height_map[i] = 1
# import DLL
E = ctypes.cdll.LoadLibrary("./t383.so")
# initialize device memory
E.init( ctypes.c_void_p(ter_height_map.ctypes.data),
ctypes.c_void_p(water_height_map.ctypes.data),
ctypes.c_void_p(sed_height_map.ctypes.data),
ctypes.c_int(size_x),
ctypes.c_int(size_y))
# run erosion
while(scrpt_cycles):
scrpt_cycles = scrpt_cycles - 1
E.run_hydro_erosion(ctypes.c_int(kernel_cycles),
ctypes.c_float(time_step),
ctypes.c_float(min_tilt_angle),
ctypes.c_float(sediment_cap),
ctypes.c_float(dissolve_const),
ctypes.c_float(deposit_const),
ctypes.c_int(size_x),
ctypes.c_int(size_y),
ctypes.c_float(pipe_length),
ctypes.c_float(adjacent_length),
ctypes.c_float(time_step),
ctypes.c_float(min_tilt_angle))
$ nvcc -Xcompiler -fPIC -std=c++11 -shared -arch=sm_61 -o t383.so t383.cu
$ python t383.py
init terrain_height_map
1, 1, 1, 1, 1,
1, 1, 1, 1,
1, 1, 1, 1,
1, 1, 1, updated terrain
0, 0, 0, 0, 0,
0, 0, 0, 0,
0, 0, 0, 0,
0, 0, 0,
$ nvcc -Xcompiler -fPIC -std=c++11 -shared -arch=sm_61 -o t383.so t383.cu -DFIX
$ cuda-memcheck python t383.py
========= CUDA-MEMCHECK
init terrain_height_map
1, 1, 1, 1, 1,
1, 1, 1, 1,
1, 1, 1, 1,
1, 1, 1, updated terrain
1, 1, 1, 1, 1,
1, 1, 1, 1,
1, 1, 1, 1,
1, 1, 1,
========= ERROR SUMMARY: 0 errors
$
Если мы скомпилируем предыдущий пример без исправления, но запустим его с cuda-memcheck мы получим вывод, указывающий на доступ за пределами:
$nvcc -Xcompiler -fPIC -std=c++11 -shared -arch=sm_61 -o t383.so t383.cu
$ cuda-memcheck python t383.py
========= CUDA-MEMCHECK
init terrain_height_map
1, 1, 1, 1, 1,
1, 1, 1, 1,
1, 1, 1, 1,
========= Invalid __global__ write of size 4
========= at 0x000002f0 in update_water_flow(float*, float*, float*, int, int)
========= by thread (31,0,0) in block (0,0,0)
========= Address 0x1050d6009f0 is out of bounds
========= Saved host backtrace up to driver entry point at kernel launch time
========= Host Frame:/usr/lib/x86_64-linux-gnu/libcuda.so.1 (cuLaunchKernel + 0x2c5) [0x204505]
========= Host Frame:./t383.so [0x1c291]
========= Host Frame:./t383.so [0x39e33]
========= Host Frame:./t383.so [0x6879]
========= Host Frame:./t383.so (_Z43__device_stub__Z17update_water_flowPfS_S_iiPfS_S_ii + 0xe3) [0x6747]
========= Host Frame:./t383.so (_Z17update_water_flowPfS_S_ii + 0x38) [0x6781]
========= Host Frame:./t383.so (run_hydro_erosion + 0x8f2) [0x648b]
========= Host Frame:/usr/lib/x86_64-linux-gnu/libffi.so.6 (ffi_call_unix64 + 0x4c) [0x5adc]
========= Host Frame:/usr/lib/x86_64-linux-gnu/libffi.so.6 (ffi_call + 0x1fc) [0x540c]
========= Host Frame:/usr/lib/python2.7/lib-dynload/_ctypes.x86_64-linux-gnu.so (_ctypes_callproc + 0x48e) [0x145fe]
========= Host Frame:/usr/lib/python2.7/lib-dynload/_ctypes.x86_64-linux-gnu.so [0x15f9e]
========= Host Frame:python (PyEval_EvalFrameEx + 0x98d) [0x1244dd]
========= Host Frame:python [0x167d14]
========= Host Frame:python (PyRun_FileExFlags + 0x92) [0x65bf4]
========= Host Frame:python (PyRun_SimpleFileExFlags + 0x2ee) [0x6612d]
========= Host Frame:python (Py_Main + 0xb5e) [0x66d92]
========= Host Frame:/lib/x86_64-linux-gnu/libc.so.6 (__libc_start_main + 0xf5) [0x21f45]
========= Host Frame:python [0x177c2e]
=========
========= Invalid __global__ write of size 4
========= at 0x000002f0 in update_water_flow(float*, float*, float*, int, int)
========= by thread (30,0,0) in block (0,0,0)
========= Address 0x1050d6009e0 is out of bounds
========= Saved host backtrace up to driver entry point at kernel launch time
========= Host Frame:/usr/lib/x86_64-linux-gnu/libcuda.so.1 (cuLaunchKernel + 0x2c5) [0x204505]
========= Host Frame:./t383.so [0x1c291]
========= Host Frame:./t383.so [0x39e33]
========= Host Frame:./t383.so [0x6879]
========= Host Frame:./t383.so (_Z43__device_stub__Z17update_water_flowPfS_S_iiPfS_S_ii + 0xe3) [0x6747]
========= Host Frame:./t383.so (_Z17update_water_flowPfS_S_ii + 0x38) [0x6781]
========= Host Frame:./t383.so (run_hydro_erosion + 0x8f2) [0x648b]
========= Host Frame:/usr/lib/x86_64-linux-gnu/libffi.so.6 (ffi_call_unix64 + 0x4c) [0x5adc]
========= Host Frame:/usr/lib/x86_64-linux-gnu/libffi.so.6 (ffi_call + 0x1fc) [0x540c]
========= Host Frame:/usr/lib/python2.7/lib-dynload/_ctypes.x86_64-linux-gnu.so (_ctypes_callproc + 0x48e) [0x145fe]
========= Host Frame:/usr/lib/python2.7/lib-dynload/_ctypes.x86_64-linux-gnu.so [0x15f9e]
========= Host Frame:python (PyEval_EvalFrameEx + 0x98d) [0x1244dd]
========= Host Frame:python [0x167d14]
========= Host Frame:python (PyRun_FileExFlags + 0x92) [0x65bf4]
========= Host Frame:python (PyRun_SimpleFileExFlags + 0x2ee) [0x6612d]
========= Host Frame:python (Py_Main + 0xb5e) [0x66d92]
========= Host Frame:/lib/x86_64-linux-gnu/libc.so.6 (__libc_start_main + 0xf5) [0x21f45]
========= Host Frame:python [0x177c2e]
=========
... (output truncated for brevity of presentation)
========= ERROR SUMMARY: 18 errors
$