Многопоточные распределители памяти для C/C++
В настоящее время у меня есть многопоточное серверное приложение, и я ищу хороший распределитель многопоточной памяти.
Пока я разрываюсь между:
- Уме Солнца
- Google Tcmalloc
- Распределитель блоков потоков Intel
- Запас Эмери Бергера
Из того, что я обнаружил, запас может быть самым быстрым, но я не слышал об этом до сегодняшнего дня, поэтому я скептически отношусь к тому, действительно ли он так хорош, как кажется. Кто-нибудь имеет личный опыт опробования этих распределителей?
8 ответов
Я использовал tcmalloc и читал о Hoard. Оба имеют схожие реализации и оба достигают примерно линейного масштабирования производительности по отношению к количеству потоков / процессоров (согласно графикам на их соответствующих сайтах).
Итак, если производительность действительно невероятно важна, тогда проведите тестирование производительности / нагрузки. В противном случае, просто бросьте кубик и выберите один из перечисленных (взвешенный по простоте использования на вашей целевой платформе).
А из ссылки на trshiv похоже, что Hoard, tcmalloc и ptmalloc примерно сопоставимы по скорости. В целом, tt выглядит так, как будто ptmalloc оптимизирован, чтобы занимать как можно меньше места, Hoard оптимизирован для компромисса между скоростью и использованием памяти, а tcmalloc оптимизирован для чистой скорости.
Единственный способ действительно сказать, какой распределитель памяти подходит для вашего приложения, это попробовать несколько. Все упомянутые распределители были написаны умными людьми и побьют других по одному или другому микробенчмарку. Если все ваше приложение в течение всего дня использует malloc один 8-байтовый фрагмент в потоке A и освобождает его в потоке B, и больше ничего не нужно обрабатывать, вы, вероятно, могли бы написать распределитель памяти, который отбил бы все перечисленные до сих пор. Это просто не будет очень полезно для многих других.:)
У меня есть некоторый опыт использования Hoard там, где я работаю (достаточно, чтобы в результате этого опыта была обнаружена одна из самых неясных ошибок, исправленных в недавнем выпуске 3.8). Это очень хороший распределитель - но насколько он хорош для вас, зависит от вашей рабочей нагрузки. И вам нужно заплатить за Hoard (хотя это не слишком дорого), чтобы использовать его в коммерческом проекте без GPL-кода.
Очень слегка адаптированный ptmalloc2 уже давно является распределителем, стоящим за malloc от glibc, и поэтому он невероятно широко используется и тестируется. Если стабильность важна превыше всего, это может быть хорошим выбором, но вы не упомянули об этом в своем списке, поэтому я предполагаю, что его нет. Для определенных рабочих нагрузок это ужасно, но то же самое верно для любого malloc общего назначения.
Если вы готовы платить за это (и, насколько я понимаю, цена приемлемая), SmartHeap SMP также является хорошим выбором. Большинство других упомянутых распределителей разработаны как вставные замены malloc/free new/delete, которые могут быть LD_PRELOAD. SmartHeap также можно использовать таким же образом, но он также включает в себя целый API-интерфейс, связанный с распределением ресурсов, который позволяет вам точно настроить ваши распределители в соответствии с вашим сердцем. В тестах, которые мы сделали (опять же, очень специфично для конкретного приложения), SmartHeap был примерно таким же, как и Hoard, по производительности, когда он выполнял роль замены malloc; реальная разница между ними заключается в степени настройки. Вы можете получить лучшую производительность, чем менее универсально, чем вам нужен ваш распределитель.
И, в зависимости от вашего варианта использования, многопоточный распределитель общего назначения может совсем не подходить вам; если вы постоянно используете malloc и освобождаете объекты одинакового размера, вы можете просто написать простой распределитель блоков. Распределение плит используется в нескольких местах ядра Linux, которые соответствуют этому описанию. (Я бы дал вам еще пару полезных ссылок, но я "новый пользователь", и Stack Overflow решила, что новым пользователям не разрешено быть слишком полезными, все в одном ответе. Однако Google может помочь достаточно хорошо.)
Я лично предпочитаю и рекомендую ptmalloc как многопоточный распределитель. Hoard - это хорошо, но в оценке, которую моя команда провела между Hoard и ptmalloc несколько лет назад, ptmalloc была лучше. Из того, что я знаю, ptmalloc существует уже много лет и довольно широко используется в качестве многопоточного распределителя.
Вы можете найти это сравнение полезным.
Может быть, это неправильный способ приблизиться к тому, что вы просите, но, возможно, можно использовать другую тактику вообще. Если вы ищете действительно быстрый распределитель памяти, возможно, вам следует спросить, зачем вам тратить столько времени на выделение памяти, когда вы, возможно, можете просто сойти с распределением переменных в стеке. Распределение стеков, хотя и более раздражающее, но сделанное правильно, может сэкономить вам массу средств на пути к мьютексному конфликту, а также исключить странные проблемы с повреждением памяти в вашем коде. Кроме того, у вас потенциально меньше фрагментации, которая может помочь.
Распределитель locklessinc очень хорош, и разработчик отзывчив, если у вас есть вопросы. Есть статья, которую он написал о некоторых используемых приемах оптимизации, это интересно читать: http://locklessinc.com/articles/allocator_tricks/. Я использовал его в прошлом с отличными результатами.
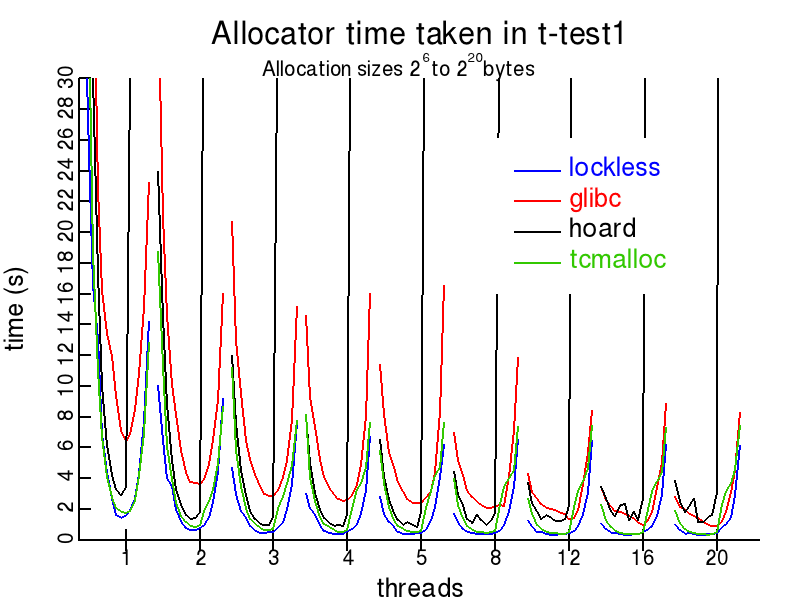
Мы использовали запас на проекте, где я работал несколько лет назад. Казалось, отлично работает. У меня нет опыта работы с другими распределителями. Должно быть довольно легко попробовать разные и выполнить нагрузочное тестирование, не так ли?
Вы можете попробовать ltalloc (универсальный распределитель памяти общего назначения со скоростью быстрого выделения пула).
Возможно, поздний ответ на ваш вопрос, но
зачем делать malloc, если у вас есть проблемы с производительностью?
Лучшим способом было бы сделать malloc большого окна памяти при инициализации, а затем придумать light weight Memory manager это было бы lease out the memory chunks at run time,
Это исключает любую возможность системных вызовов при расширении вашей кучи.