Как создать группы похожих имен в R?
Я хотел бы создать групповые переменные в зависимости от того, насколько похож выбор имен. Я начал с использования пакета stringdist для генерации меры расстояния. Но я не уверен, как использовать эту выходную информацию для создания группы по переменной. Я смотрел на hclust, но похоже, что для использования функций кластеризации вам нужно знать, сколько групп вы хотите получить, и я этого не знаю. Код, с которого я начинаю, ниже:
name_list <- c("Mary", "Mery", "Mary", "Joe", "Jo", "Joey", "Bob", "Beb", "Paul")
name_dist <- stringdistmatrix(name_list)
name_dist
name_dist2 <- stringdistmatrix(name_list, method="soundex")
name_dist2
Я хотел бы видеть фрейм данных с двумя столбцами, которые выглядят как
name = c("Mary", "Mery", "Mary", "Joe", "Jo", "Joey", "Bob", "Beb", "Paul")
name_group = c(1, 1, 1, 2, 2, 2, 3, 3, 4)
Группы могут немного отличаться в зависимости, очевидно, от того, какую меру расстояния я использую (я предложил две выше), но я, вероятно, выберу одну или другую для бега.
По сути, как мне перейти от матрицы расстояний к групповой переменной, не зная количества кластеров, которые я бы хотел?
2 ответа
Вы можете использовать кластерный анализ следующим образом:
# loading the package
require(stringdist);
# Group selection by class numbers or height
num.class <- 5;
num.height <-0.5;
# define names
n <- c("Mary", "Mery", "Mari", "Joe",
"Jo", "Joey", "Bob", "Beb", "Paul");
# calculate distances
d <- stringdistmatrix(n, method="soundex");
# cluster the stuff
h <- hclust(d);
# cut the cluster by num classes
m <- cutree(h, k = num.class);
# cut the cluster by height
p <- cutree(h, h = num.height);
# build the resulting frame
df <- data.frame(names = n,
group.class = m,
group.prob = p);
Это производит:
df;
names group.class group.prob
1 Mary 1 1
2 Mery 1 1
3 Mari 1 1
4 Joe 2 2
5 Jo 2 2
6 Joey 2 2
7 Bob 3 3
8 Beb 4 3
9 Paul 5 4
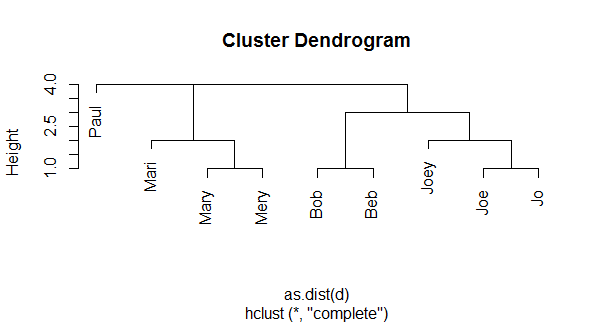
И диаграмма дает вам обзор:
plot(h, labels=n);
С наилучшими пожеланиями
Вы также можете использовать adist(...) в базе R для расчета расстояний Левенштейна и кластера на основе этого.
n<- c("Mary", "Mery", "Mari", "Joe", "Jo", "Joey", "Bob", "Beb", "Paul")
d <- adist(n)
rownames(d) <- n
cl <- hclust(as.dist(d))
plot(cl)