Преобразование неанглийских символов в Unicode (UTF-8)
Я скопировал большое количество текста из другой системы на мой компьютер. Когда я смотрел текст на моем компьютере, он выглядел странно. Поэтому я скопировал все шрифты с другого компьютера и установил их на свой компьютер. Теперь текст выглядит хорошо, но на самом деле кажется, что это не в Unicode. Например, если я копирую текст и вставляю в другой редактор, поддерживаемый UTF-8, такой как Notepad++, я получаю английские символы ("bgah;") только так, как показано ниже.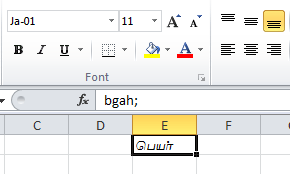
Как преобразовать весь этот текст в текст Unicode, как показано ниже. Так что я могу скопировать текст и вставить в любое другое место.
பெயர்
Приведенный выше текст был получен вручную с помощью http://www.google.com/transliterate/indic/Tamil
Мне нужно сделать это преобразование, чтобы я мог скопировать их в таблицы базы данных.
4 ответа
"bgah" выглядит как система на основе Baamini, которая является пре-юникодной. Он был популярен в Канаде (и в целом в тамильской диаспоре) в 90-х годах.
Как уже упоминалось, это похоже на пользовательскую визуальную кодировку, которая имитирует производительность стороннего скрипта при сохранении кодировки ASCII.
Google "Конвертер Baamini в Юникод". Университет Коломбо, кажется, поднял один: http://www.ucsc.cmb.ac.lk/ltrl/services/feconverter/?maps=t_b-u.xml
Дайте мне знать, если это работает. Если нет, я могу спросить и получить что-то для вас.
"Ja-01" - это шрифт с пользовательской "визуальной кодировкой".
То есть последовательность символов действительно "bgah;" и это только выглядит как тамильский, потому что формы шрифта для латинских символов bg выглядит как பெ,
Этого всегда следует избегать, потому что, сохраняя содержимое как "bgah;" вы теряете возможность искать и обрабатывать его как настоящий тамильский, но такой подход был распространен в дни до Юникода, особенно для менее распространенных сценариев без зрелых стандартов кодирования. Это приложение, вероятно, предшествует широкому использованию TSCII.
Так как это пользовательская кодировка, которая не используется другими шрифтами, очень маловероятно, что вы сможете найти инструмент для преобразования содержимого этой кодировки в надлежащие символы Юникода. Похоже, что это не какой-либо стандартный порядок символов, поэтому вам придется посмотреть на шрифт (например, в charmap.exe) и записать каждый символ, найти соответствующий символ в Unicode и отобразить между ними.
Например, вот тривиальный скрипт Python для замены символов в файле:
mapping= {
u'a': u'\u0BAF', # Tamil letter Ya
u'b': u'\u0BAA', # Tamil letter Pa
u'g': u'\u0BC6', # Tamil vowel sign E (combining)
u'h': u'\u0BB0', # Tamil letter Ra
u';': u'\u0BCD', # Tamil sign virama (combining)
# fill in the rest of the mapping information here!
}
with open('ja01data.txt', 'rb') as fp:
data= fp.read().decode('utf-8')
for char in mapping:
data= data.replace(char, mapping[char])
with open('utf8data.txt', 'wb') as fp:
fp.write(data.encode('utf-8'))
Шрифт, который вы нашли, доставляет вам неприятности. Фактический текст ячейки - "bgah;", он отображается в பெயர், потому что вы нашли шрифт, который может работать с 8-битными не-Unicode-символами. Поэтому чтение или вставка в Notepad++ приведет к появлению "bgah;" так как это настоящий текст. Он может быть снова правильно обработан только после того, как программа, которая отображает строку, использует тот же шрифт.
Откажитесь от шрифта и введите Unicode, чтобы он выглядел так:

Вы могли бы сначала проверить, является ли кодировка TSCII, поскольку это звучит наиболее вероятно. Это 8-битная кодировка, и скопированные вами шрифты, вероятно, основаны на этой кодировке. Проверьте, подходит ли конвертер TSCII в UTF-8 на SourceForge. Проект называется "Любое тамильское кодирование в Unicode", но говорят, что пока поддерживается только TSCII.